JD.com's exploration and practice with Apache Doris in real time OLAP

Guide: This article discusses the exploration and practice of the search engine team in JD.com using Apache Flink and Apache Doris in real-time data analysis. The popularity of stream computing is increasing day by day: More papers are published on Google Dataflow; Apache Flink has become the one of the most popular engine in the world; There is wide application of real-time analytical databases more than ever before, such as Apache Doris; Stream computing engines are really flourishing. However, no engine is perfect enough to solve every problem. It is important to find a suitable OLAP engine for the business. We hope that JD.com's practice in real-time OLAP and stream computing may give you some inspiration.
Author: Li Zhe, data engineer of JD.com, who focused on offline data, stream computing and application development.
About JD.com
JD.com (NASDAQ: JD), a leading e-commerce company in China, had a net income of RMB 951.6 billion in 2021. JD Group owns JD Retail, JD Global, JD Technology, JD Logistics, JD Cloud, etc. Jingdong Group was officially listed on the NASDAQ Stock Exchange in May 2014.
JD Search Box's Requirement: Real-time Data Analysis
JD search box, as the entrance of the e-commerce platform, provides a link betwee merchants and users. Users can express their needs through the search box. In order to better understand user intentions and quickly improve the conversion rate, multiple A/B tests are running online at the same time, which apply to multiple products. The category, organization, and brand all need to be monitored online for better conversion. At present, JD search box demands real-time data in application mainly includes three parts:
- The overall data of JD search box.
- Real-time monitoring of the A/B test.
- Top list of hot search words to reflect changes in public opinion. Words trending can reflect what users care
The analysis mentioned above needs to refine the data to the SKU-level. At the same time, we also undertake the task of building a real-time data platform to show our business analysists different real-time stream computing data.
Although different business analysists care about different data granularity, time frequency, and dimensions, we are hoping to establish a unified real-time OLAP data warehouse and provide a set of safe, reliable and flexible real-time data services.
At present, the newly generated exposure logs every day reach hundreds of millions. The logs willl increase by 10 times if they are stored as SKU. And they would grow to billions of records if based on A/B test. Aggregation queries cross multi-dimension require second-level response time.
Such an amount of data also brings huge challenges to the team: 2 billion rows have been created daily; Up to 60 million rows need to be imported per minute; Data latency should be limited to 1 minute; MDX query needs to be executed within 3 seconds; QPS has reached above 20. Yet a new reliable OLAP database with high stability should be able to respond to priority 0 emergency.
The Evolution of the Real-time Architecture
Our previous architecture is based on Apache Storm for a point-to-point data processing. This approach can quickly meet the needs of real-time reports during the stage of rapid business growth in the early days. However, with the continuous development of business, disadvantages gradually appear. For example, poor flexibility, poor data consistency, low development efficiency and increased resource costs.
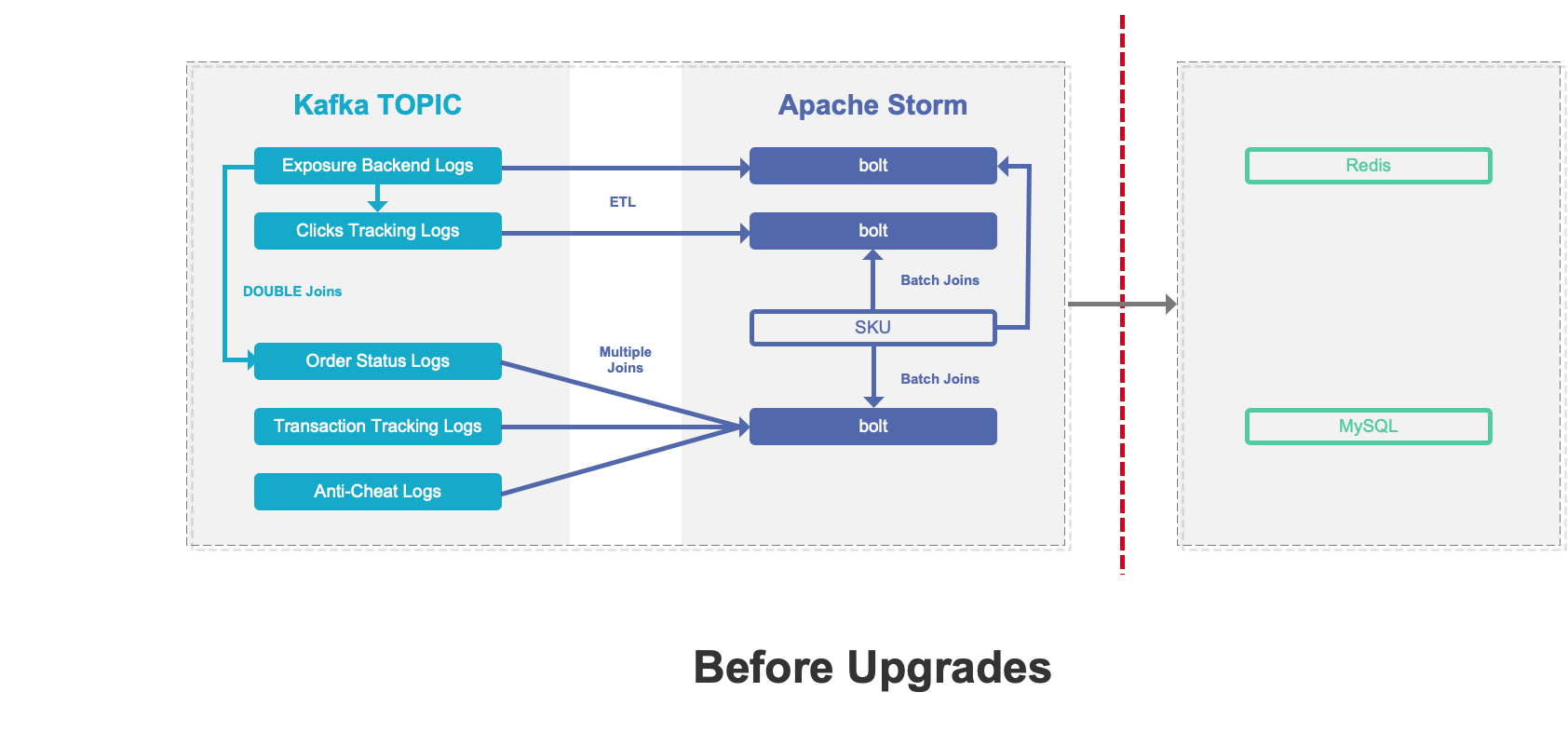
In order to solve the problems of the previous architecture, we first upgraded the architecture and replaced Apache Storm with Apache Flink to achieve high throughput. At the same time, according to the characteristics of the search data, the real-time data is processed hierarchically, which means the PV data flow, the SKU data flow and the A/B test data flow are created. It is expected to build the upper real-time OLAP layer based on the real-time flow.
When selecting OLAP database, the following points need to be considered:
- The data latency is at minute-level and the query response time is at second-level
- Suppots standard SQL, which reduces the cost of use
- Supports JOIN to facilitate adding dimension
- Traffic data can be deduplicated approximately, but order data must be exact deduplicated
- High throughput with tens of millions of records per minute and tens of billions of new records every day
- Query concurrency needs to be high because Front-end may need it
By comparing the OLAP engines that support real-time import , we made an in-depth comparison among Apache Druid, Elasticsearch, Clickhouse and Apache Doris:
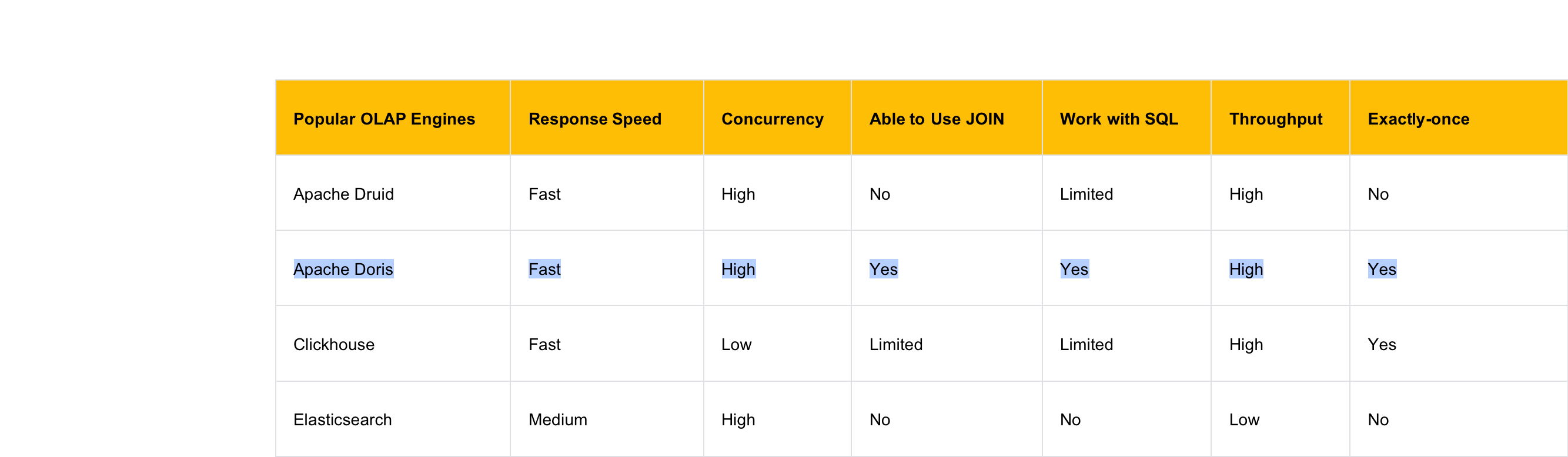
We found out that Doris and Clickhouse can meet our needs. But the concurrency of Clickhouse is low for us, which is a potential risk. Moreover, the data import of Clickhouse has no TRANSACTION and cannot achieve Exactly-once semantics. Clickhouse is not fully supportive of SQL.
Finally, we chose Apache Doris as our real-time OLAP database. For user behavior log data, we use Aggregation Key data table; As for E-commerce orders data, we use Unique Key data table. Moreover, we split the previous tasks and reuse the logic we tried before. Therefore, when Flink is processing, there will be new topic flow and real-time flow of different granularities generated in DWD. The new architecture is as follows:
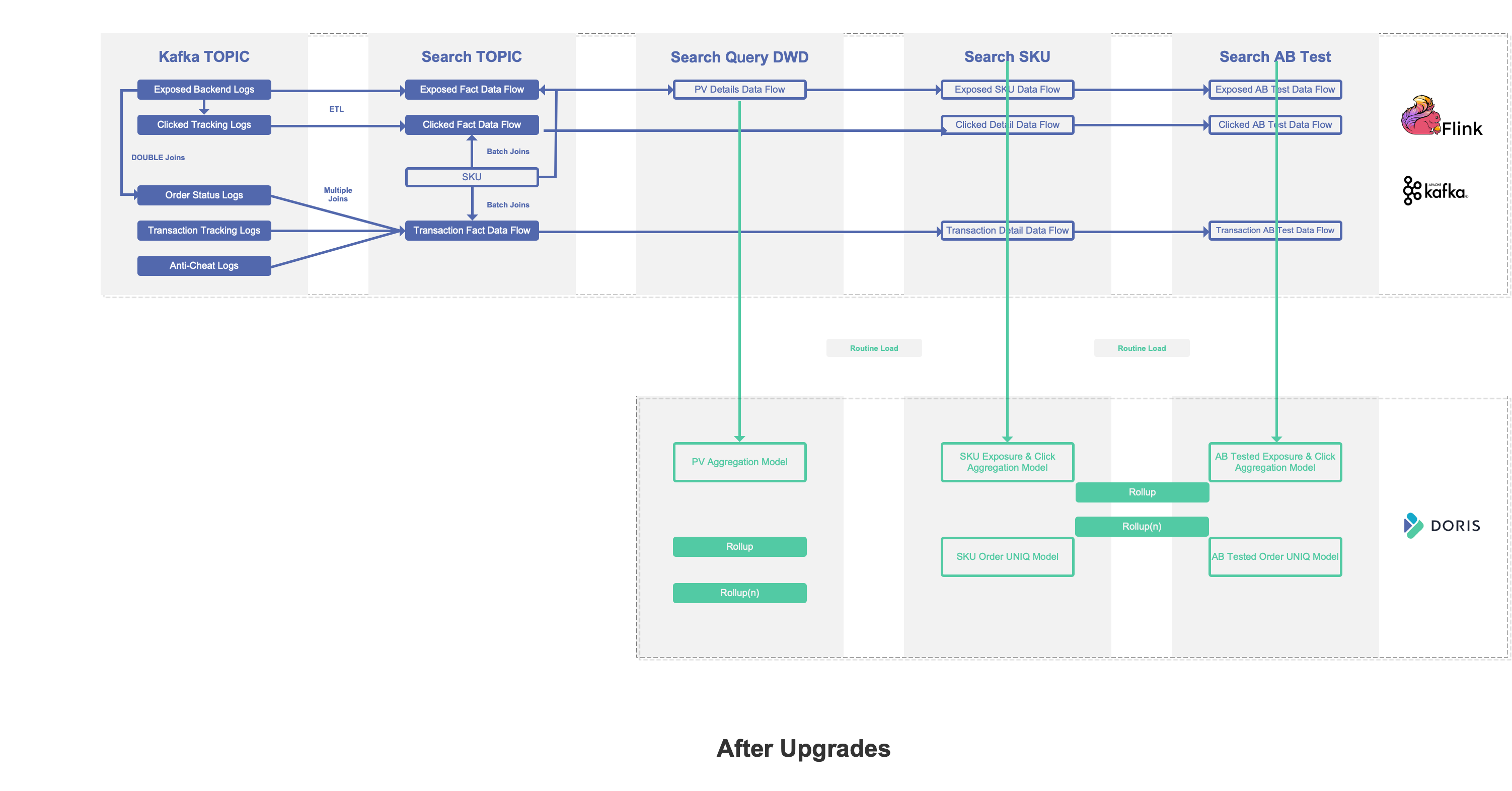
In the current technical architecture, flink task is very light. Based on the production data detail layer, we directly use Doris to act as the aggregation layer function. And we ask Doris to complete window calculation which previously belongs to Flink. We also take advantage of the routine load to consume real-time data. Although the data is fine-grained before importing, based on the Aggregation Key, asynchronous aggregation will be automatically performed. The degree of aggregation is completely determined by the number of dimensions. By creating Rollup on the base table, double-write or multi-write and pre-aggregate operations are performed during import, which is similar to the function of materialized view, which can highly aggregate data to improve query performance.
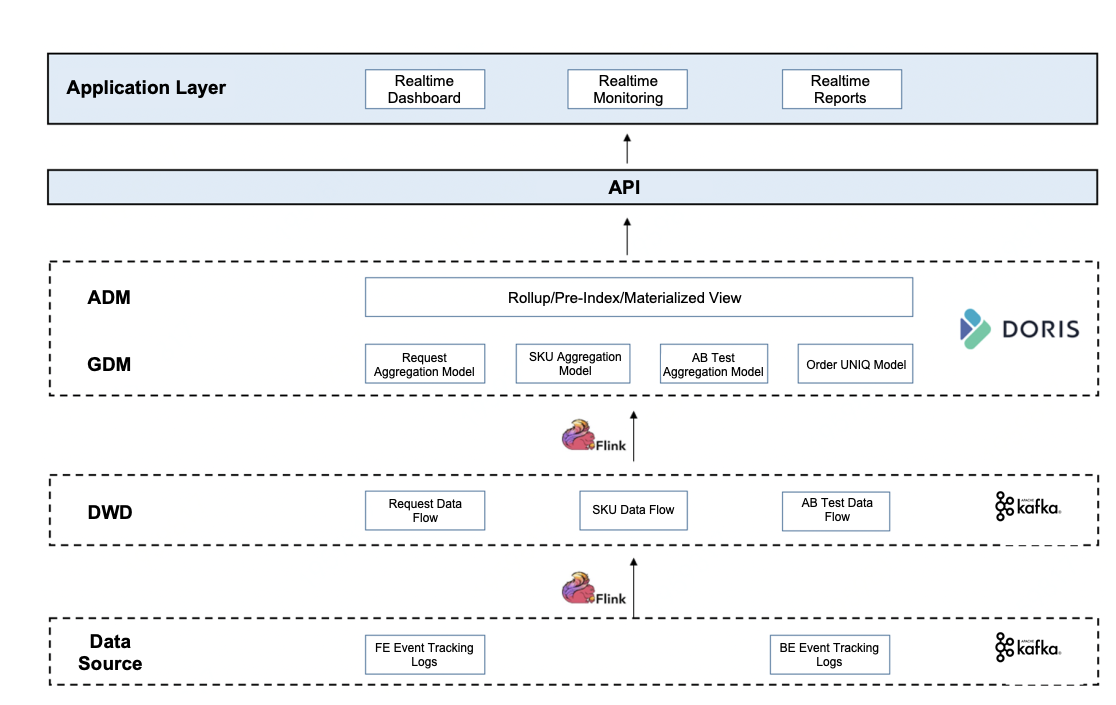
Another advantage of using Kafka to directly connect to Doris at the detail layer is that it naturally supports data backtracking. Data backtracking means that when real-time data is out of order, the "late" data can be recalculated and the previous results can be updated. This is because delayed data can be written to the table whenever it arrives. The final solution is as follows:
Optimization during the Promotion
As mentioned above, we have established Aggregation Key of different granularities in Doris, including PV, SKU, and A/B test granularity. Here we take the exposure A/B test model with the largest amount of daily production data as an example to explain how to support the query of tens of billions of records per day during the big promotion period.
Strategy we used:
- Monitoring: 10, 30, 60 minutes A/B test with indicators, such as exposure PV, UV, exposure SKU pieces, click PV, click UV and CTR.
- Data Modeling: Use exposed real-time data to establish Aggregation Key; And perform HyperLogLog approximate calculation with UV and PV
Clusters we had:
- 30+ virtual machines with storage of NVMe SSD
- 40+ partitions exposed by A/B test
- Tens of billions of new data are created every day
- 2 Rollups
Benefits overall:
- Bucket Field can quickly locate tablet partition when querying
- Import 600 million records in 10 minutes
- 2 Rollups have relatively low IO, which meet the requirement of the query
Look Ahead
JD search box introduced Apache Doris in May 2020, with a scale of 30+ BEs, 10+ routine load tasks running online at the same time. Replacing Flink's window computing with Doris can not only improve development efficiency, adapt to dimension changes, but also reduce computing resources. Apache Doris provides unified interface services ensuring data consistency and security. We are also pushing the upgrade of JD search box's OLAP platform to the latest version. After upgrading, we plan to use the bitmap function to support accurate deduplication operations of UV and other indicators. In addition, we also plan to use the appropriate Flink window to develop the real-time stream computing of the aggregation layer to increase the richness and completeness of the data.
