New milestone: Apache Doris 3.0 has been released
We are excited to announce the release of Apache Doris 3.0!
Starting from version 3.X, Apache Doris supports a compute-storage decoupled mode in addition to the compute-storage coupled mode for cluster deployment. With the cloud-native architecture that decouples the computation and storage layers, users can achieve physical isolation between query loads across multiple compute clusters, as well as isolation between read and write loads. Additionally, users can take advantage of low-cost shared storage systems such as object storage or HDFS to significantly reduce storage costs.
Version 3.0 marks a milestone in the evolution of Apache Doris towards a unified data lake and data warehouse architecture. This version introduces the ability to write data back to data lakes, allowing users to perform data analysis, sharing, processing, and storage operations across multiple data sources within Apache Doris. With capabilities such as asynchronous materialized views, Apache Doris can serve as a unified data processing engine for enterprises, helping users better manage data across lakes, warehouses, and databases. Also, Apache Doris 3.0 introduces the Trino Connector. It allows users to quickly connect or adapt to more data sources, and leverage the high-performance compute engine of Doris to deliver faster query results than Trino.
Version 3.0 also enhances support for ETL batch processing scenarios, adding explicit transaction support for operations like insert into select, delete and update. The observability of query execution has also been improved.
In terms of performance, we have improved the framework capabilities, infrastructure, and rules of the query optimizer in version 3.0. This provides optimized performance, which has been proven by blind testing in more complex and diverse business scenarios.
The adaptive Runtime Filter computation method now accurately estimates filters based on data size during execution, delivering better performance under large data volumes and high loads. Additionally, asynchronous materialized view has been more stable and user-friendly in query acceleration and data modeling.
During the development of version 3.0, over 200 contributors submitted nearly 5,000 optimizations and fixes to Apache Doris. Contributors from companies such as VeloDB, Baidu, Meituan, ByteDance, Tencent, Alibaba, Kwai, Huawei, and Tianyi Cloud actively collaborated with the community, contributing test cases from real-world use cases to help us improve Apache Doris. We extend our heartfelt thanks to all the contributors involved in the development, testing, and feedback process for this release.
1. Compute-storage decoupled mode
Since V3.0, Apache Doris supports the compute-storage decoupled mode. Users can choose between it and the compute-storage coupled mode during cluster deployment.
In the compute-storage decoupled mode, the BE nodes no longer store the data, but instead, a shared storage layer (HDFS and object storage) is introduced as the shared data storage layer. The computing and storage resources can be scaled independently, bringing multiple benefits to users:
Workload isolation: Multiple compute clusters can share the same data, allowing users to isolate different business workloads or offline loads using separate compute clusters.
Reduced storage costs: The full dataset is stored in the more cost-effective and highly reliable shared storage, with only hot data cached locally. Compared to the compute-storage coupled mode with three data replicas, the storage cost can be reduced by up to 90%.
Elastic computing resources: Since no data is stored on the BE nodes, the computing resources can be scaled flexibly based on the load requirements. Users can scale in or out an individual compute cluster or increase/decrease the number of compute clusters. This also leads to cost savings.
Improved system robustness: By storing the data in shared storage, Doris no longer needs to handle the complex logic of multi-replica consistency, thus simplifying distributed storage complexity and improving the overall system robustness.
Flexible data sharing and cloning: The flexibility of the compute-storage decoupled mode extends beyond a single Doris cluster. Tables from one Doris cluster can be easily cloned to another Doris cluster, with just metadata replication.
1-1. From coupled to decoupled
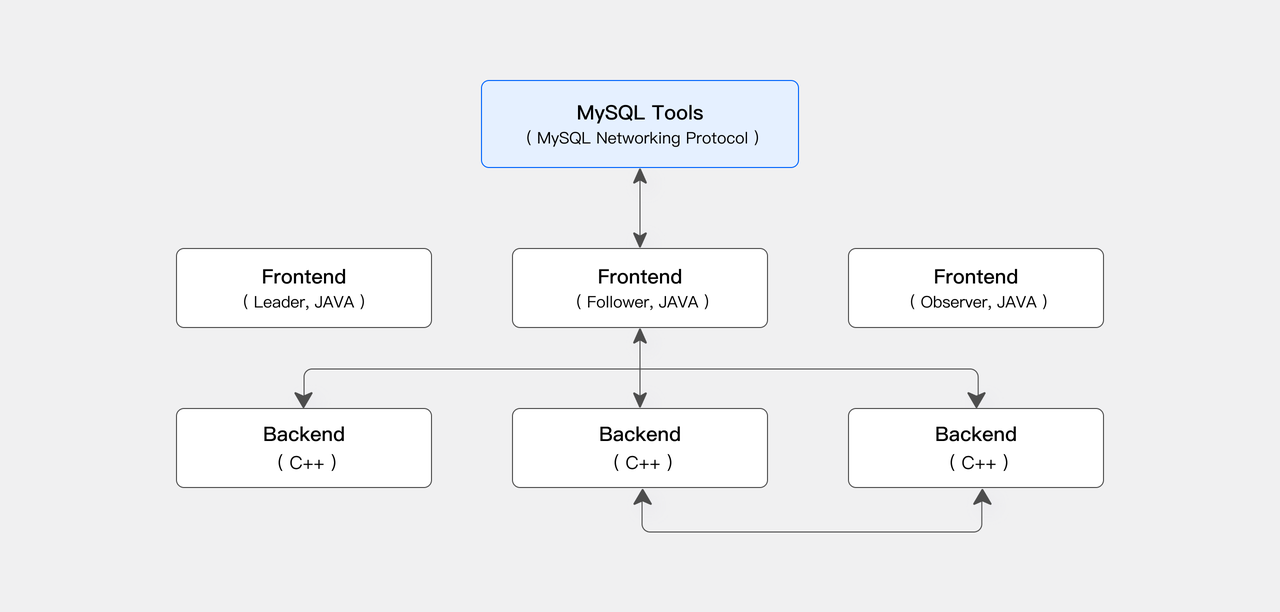
In the compute-storage coupled mode, the Apache Doris architecture consists of two main process types: Frontend (FE) and Backend (BE). The FE is primarily responsible for user request access, query parsing and planning, metadata management, and node management. The BE is responsible for data storage and query plan execution.
The BE nodes employ an MPP (Massively Parallel Processing) distributed computing architecture, leveraging a multi-replica consistency protocol to ensure high service availability and high data reliability.
The maturation of emerging cloud computing infrastructure, including public clouds, private clouds, and Kubernetes-based container platforms, has driven the need for cloud-native capabilities. Increasingly, users are seeking deeper integration between Apache Doris and cloud computing infrastructure to provide more elasticity.
To address this need, the VeloDB team has designed and implemented a cloud-native version of Apache Doris that decouples compute and storage, known as VeloDB Cloud. After extensive production testing and refinement across hundreds of enterprises over a long time, this cloud-native solution has now been contributed to the Apache Doris community, manifesting as the Apache Doris 3.0 in the compute-storage decoupled mode.
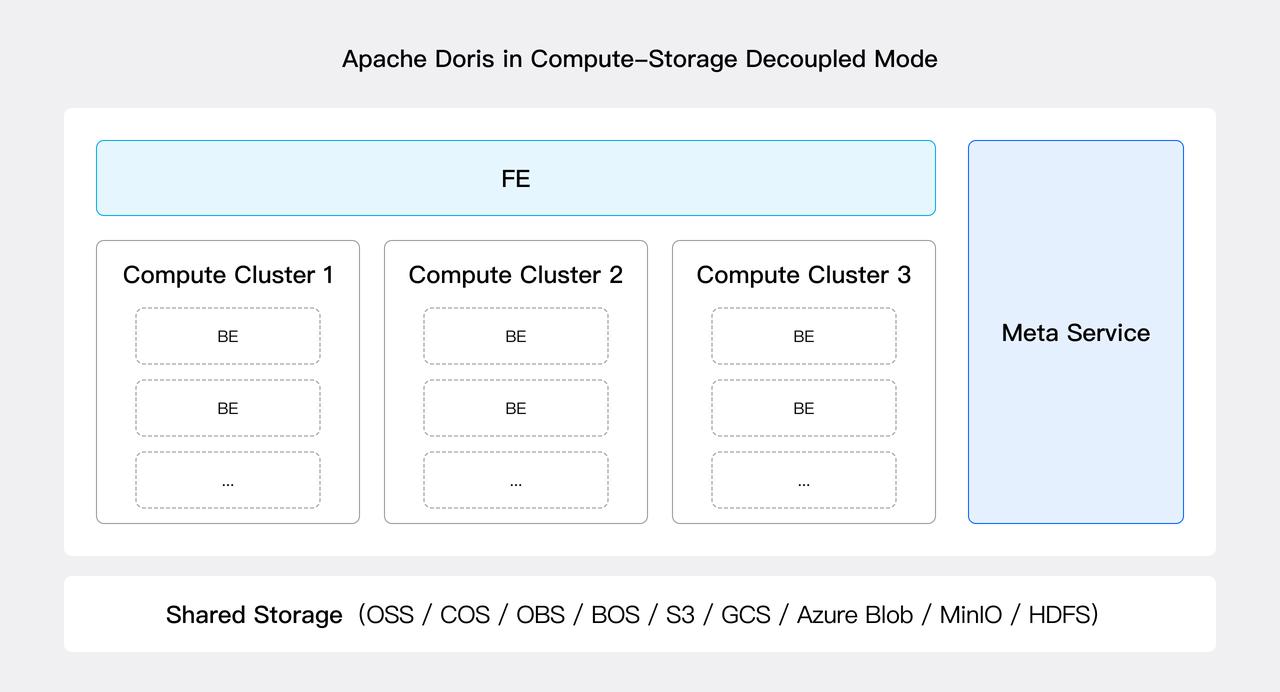
In the compute-storage decoupled mode, the Apache Doris architecture consists of three layers:
- Meta data layer: A new Meta Service module has been introduced to provide meta data services, such as processing database and table information, schemas, rowset meta, and transactions. The Meta Service is stateless and horizontally scalable. In V3.0, all of the BE's meta data and parts of the FE's meta data have been migrated to the Meta Service. We will finish the migration of the remains in future versions.
- Computation layer: The stateless BE nodes execute query plans and cache a portion of the data and tablet meta data locally to improve query performance. Multiple stateless BE nodes can be organized into a computing resource pool (i.e., compute cluster), and multiple compute clusters can share the same data and metadata service. The compute clusters can be elastically scaled by adding or removing nodes as needed.
- Shared storage layer: Data is persisted to the shared storage layer, which currently supports HDFS as well as various cloud-based object storage systems that are compatible with the S3 protocol, such as S3, OSS, GCS, Azure Blob, COS, BOS, and MinIO.
1-2 Design highlight
The design of the compute-storage decoupled mode of Apache Doris highlights the transformation of the FE's in-memory metadata model into a shared metadata service. This approach offers a globally consistent state view, allowing any node to directly submit writes without needing to go through the FE for publishing. During write operations, data is stored in shared storage, while metadata is managed by the metadata service. This effectively controls the number of small files in shared storage. Meanwhile, the real-time write performance for individual tables is nearly on par with that in the compute-storage coupled mode. The system's overall write capacity is no longer limited by the processing power of a single FE node.
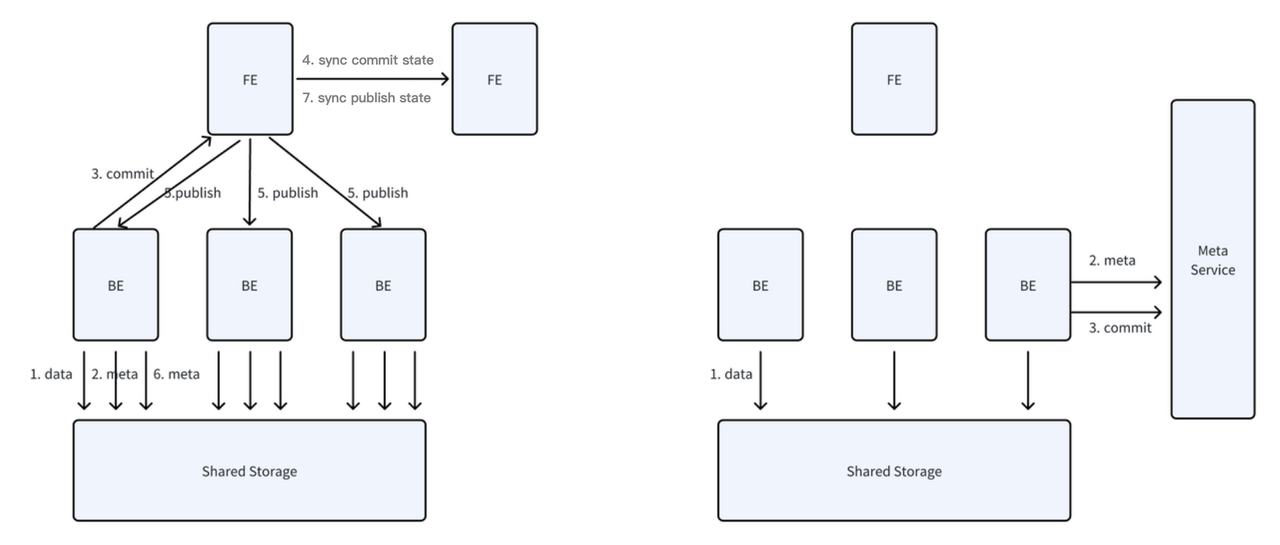
Based on the globally consistent state view, for data garbage collection, we have adopted a design approach for data deletion that is easier to prove correct and more efficient.
Specifically, data in the shared storage is incorporated into the globally consistent view offered by the shared meta data service. Whenever data is generated, we bind it to a separate, independent transaction. Similarly, for a meta data deletion operation, we also bind it to a separate, independent transaction. The purpose of this approach is to ensure that deletion and write operations cannot succeed together. The view records which data needs to be deleted, and the asynchronous deletion process can simply perform a forward deletion of the data based on the transaction records, without the need for reverse garbage collection.
As the tablet-related meta data in the FE is gradually migrated to the shared meta data service, the scalability of the Doris cluster will no longer be constrained by the memory capacity of a single FE node. Building upon the shared meta data service and the forward data deletion technique, we can conveniently expand functionality such as data sharing and lightweight cloning.
1-3 Comparison with alternative solutions
Another design of decoupling compute and storage in the industry is to store the data and BE node meta data in a shared object storage or HDFS. However, this approach brings the following problems:
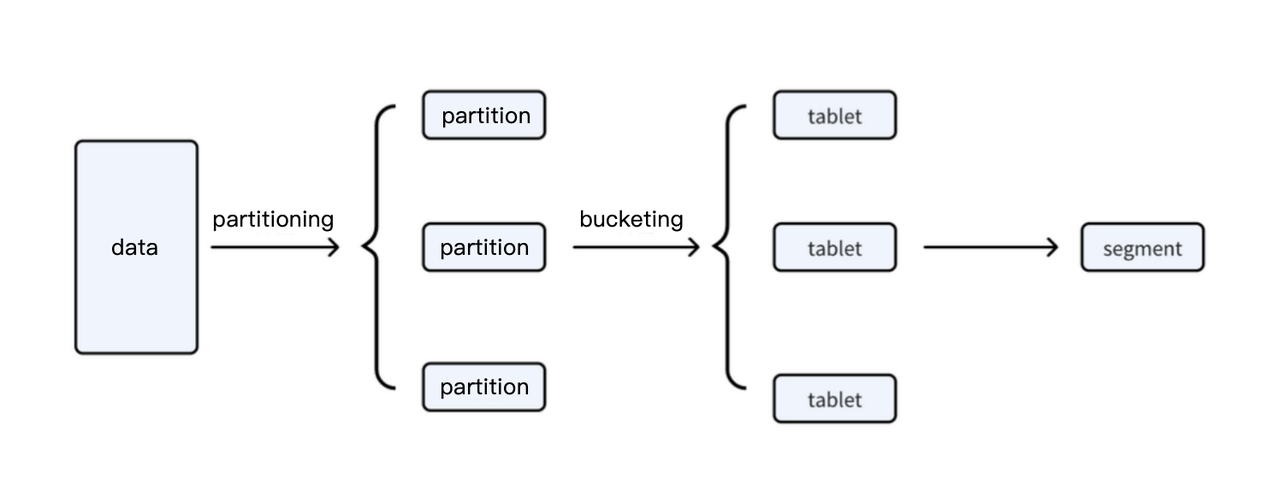
Inability to support real-time writes: During data writes, the data is mapped to tablets based on the partitioning and bucketing rules, generating segment files and rowset meta data. During the write process, a two-phase commit (Publish) is performed through the FE. When a BE node receives the Publish request, it then sets the rowset as visible. The Publish operation must not fail. If the rowset meta data is stored in the shared storage, the total small file data during the real-time write process would triple the size of the actual data files - one replica of data files, one for rowset meta data, and another for rowset meta data changes during Publish. The Publish operation is driven by a single FE node, so the write capacity of a single table or even the entire system is limited by the FE node's capabilities.
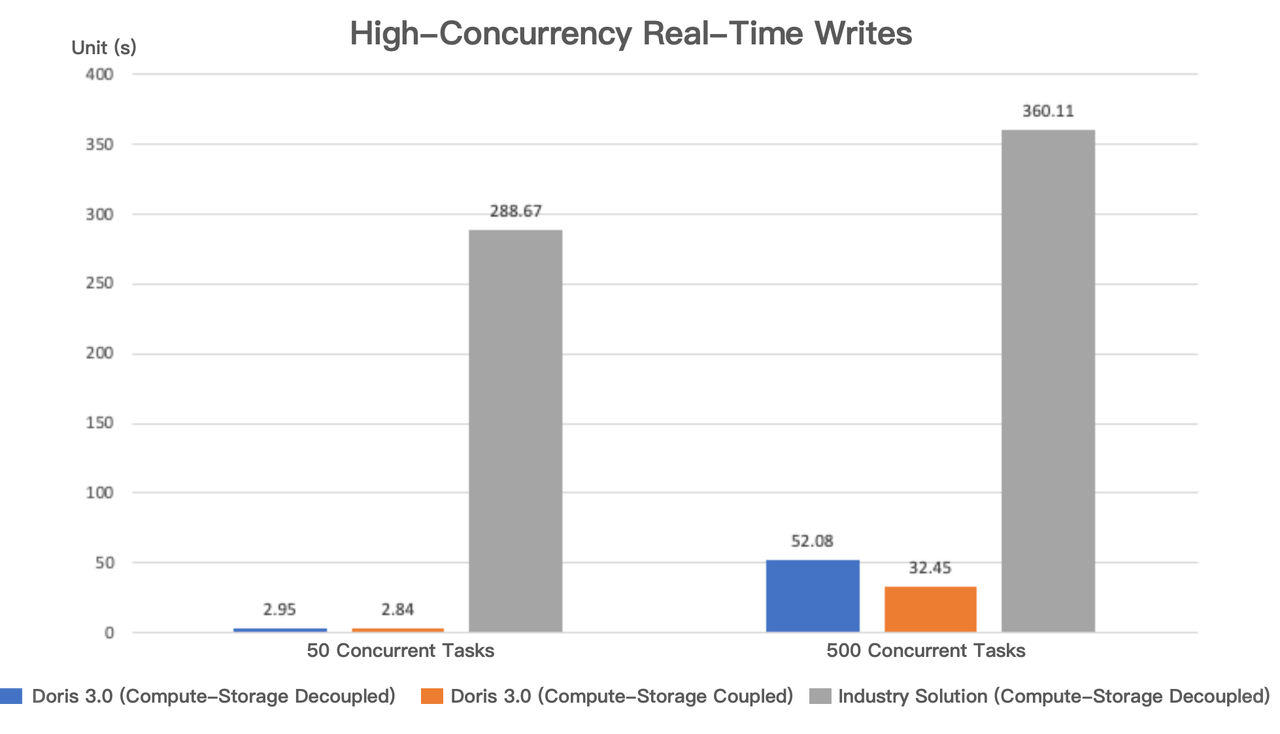
We compared the real-time data write performance of Apache Doris 3.0 with the above-described solution. We simulated 500 concurrent tasks writing 10,000 data files with 500 rows each, and 50 concurrent tasks writing 250 data files with 20,000 rows each, using the same computational resources.
The results showed that at 50 concurrent tasks, the micro-batch write performances of Apache Doris in both compute-storage coupled and decoupled modes were almost identical, while the industry solution lagged behind Apache Doris by a factor of 100.
At 500 concurrent tasks, the performance of Apache Doris in the compute-storage decoupled mode showed slight degradation, but it still maintained an 11X advantage over the industry solution. To ensure a fair test, Apache Doris did not enable the Group Commit feature (which the industry solution lacks). Enabling Group Commit would further enhance real-time write performance.
Additionally, the industry solution also faces stability and cost issues in terms of real-time data ingestion:
Stability concerns: A large number of small files can put pressure on the shared storage, especially HDFS, and introduce stability risks.
High object storage request costs: Some public cloud object storage services charge 10 times more for Put and Delete operations compared to Get operations. A large number of small files can lead to a significant increase in object storage request costs, which can even exceed the storage costs.
Limited scalability: Use cases of the compute-storage decoupled model often handles larger data storage sizes, since the FE (Frontend) meta data is entirely in-memory, when the number of tablets reaches a certain high level (e.g. tens of millions), the FE's memory pressure can become a bottleneck that limits the overall write throughput of the system.
Potential data deletion logic issues: In the compute-storage decoupled architecture, data is stored with one single replica. Therefore, the data deletion logic is critical for the system's reliability. The conventional approach of cross-system data deletion by comparing the differences can be challenging. During the write process, there is no way to completely avoid deletion and write from succeeding together, which can lead to data loss. Additionally, when the storage system experiences anomalies, the input used for difference calculation may be incorrect, which potentially leads to unintended data deletion.
Data sharing and lightweight cloning: The flexibility of the decoupled storage-compute architecture can enable future data sharing and lightweight data cloning, reducing the burden of enterprise data management. However, if each cluster has a separate FE, after cloning data across clusters, it becomes difficult to accurately determine which data is no longer referenced and can be safely deleted, as calculating cross-cluster references can easily lead to unintended data deletion.
By evolving the FE's full in-memory meta data model into a shared meta data service, Apache Doris 3.0 avoids all the aforementioned issues.
1-4 Query performance comparison
In the compute-storage decoupled mode, data needs to be read from the remote shared storage system, the main bottleneck has become the network bandwidth instead of the disk I/O in the compute-storage coupled mode.
To accelerate data access, Apache Doris has implemented a high-speed caching mechanism based on local disks, and provides two cache management policies: LRU (Least Recently Used) and TTL (Time-To-Live). The newly imported data is asynchronously written to the cache to accelerate the first-time access to the latest data. If the data required by a query is not in the cache, the system will read the data from the remote storage into memory and synchronously write it to the cache for subsequent queries.
In use cases involving multiple compute clusters, Apache Doris provides a cache preheating function. When a new compute cluster is established, users can choose to preheat specific data (such as tables or partitions) to further improve query efficiency.
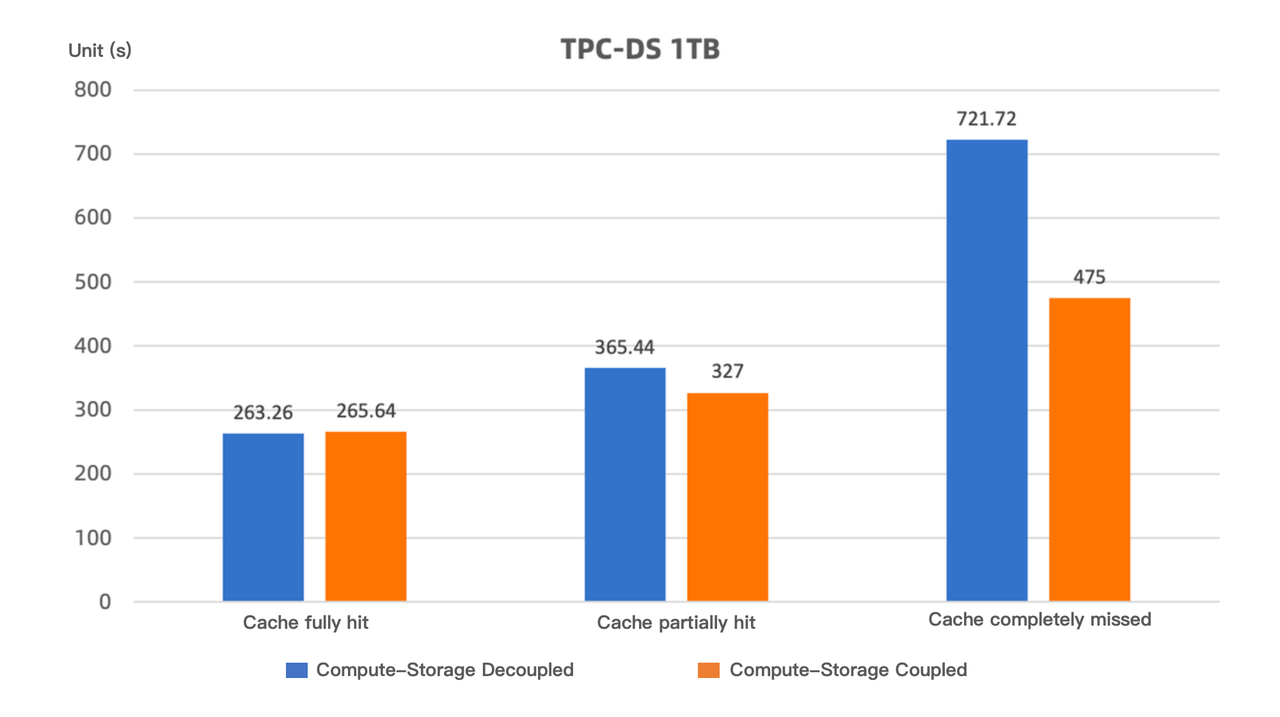
In this context, we have conducted performance tests with different caching strategies in both the compute-storage coupled and decoupled modes, using the TPC-DS 1TB test dataset. The results are concluded as follows:
When the cache is fully hit (i.e., all the data required for the query is loaded into the cache), the query performance of the compute-storage decoupled mode is on par with that of the compute-storage coupled mode.
When the cache is partially hit (i.e., the cache is cleared before the test, and data is gradually loaded into the cache during the test, with performance continuously improving), the query performance of the compute-storage decoupled mode is about 10% lower than that of the compute-storage coupled mode. This test scenario is the most similar to the real-life use cases.
When the cache is completely missed (i.e., the cache is cleared before every SQL execution, simulating an extreme case), the performance loss is around 35%. Even so, Apache Doris in the compute-storage decoupled mode delivers much higher performance than its alternative solutions.
1-5 Write speed comparison
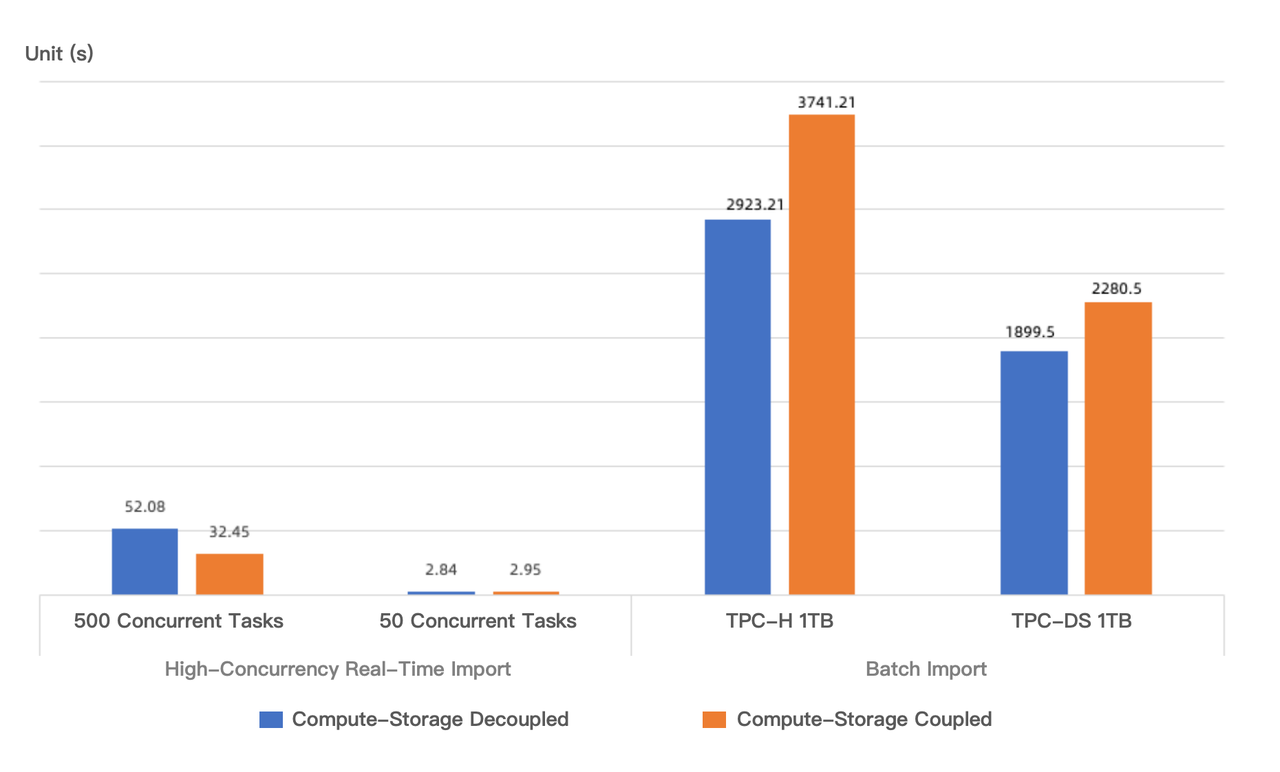
In terms of write performance, we have simulated two test cases under the same computing resources: batch import and high-concurrency real-time import. The comparison of write performance between the compute-storage coupled mode and the compute-storage decoupled mode is as follows:
Batch import: When importing the 1TB TPC-H and 1TB TPC-DS test datasets, the write performance of the compute-storage decoupled mode is 20.05% and 27.98% higher than the compute-storage coupled mode, respectively, under the single-replica configuration. During batch import, the segment file size is generally in the range of tens to hundreds of MB. In the compute-storage decoupled mode, the segment files are split into smaller files and concurrently uploaded to the object storage, which can result in higher throughput compared to writing to local disks. In real-life deployments, the compute-storage coupled mode typically uses three replicas, which means the write speed advantage of the compute-storage decoupled mode will be even more pronounced.
High-concurrency real-time import: as described in the "Comparison with alternative solutions" section.
1-6 Tips for production environment
Performance: For real-time data analysis, users can achieve query performance comparable to the compute-storage coupled mode by specifying a TTL (Time-To-Live) for the cache and writing newly ingested data into the cache. To prevent query jitter, users can cache the data generated by background tasks such as compaction and schema changes based on how frequently used the data is.
Workload isolation: Users can achieve physical resource isolation for different business using multiple compute clusters. For workload isolation within a single compute cluster, users can utilize the Workload Group mechanism to limit and isolate resources for different queries.
1-7 Notes
Apache Doris 3.0 does not support the co-existence of the compute-storage coupled mode and the compute-storage decoupled mode. Users need to specify one of them during cluster deployment.
If users need the compute-storage coupled mode, following the documentation for its deployment and upgrade. We recommend using Doris Manager for quick deployment and cluster upgrades. However, the compute-storage decoupled mode does not yet support Doris Manager deployment and upgrade. We will continue iteration for better support in future versions.
Currently Apache Doris does not support in-place upgrade from V2.1 to the compute-storage decoupled mode of V3.0. For such purpose, users need to perform data migration using tools like X2Doris after deploying the compute-storage decoupled clusters. In the future, we will support migration without service interruption through the CCR (Change Data Capture) capability.
2. Data lakehouse
Apache Doris is positioned as a real-time data warehouse, but it is much more than that. In previous versions, we have consistently pushed beyond the boundaries of traditional data warehouse capabilities, advancing towards a unified data lakehouse. Version 3.0 marks a milestone in this journey, with its capabilities in the lakehouse architecture becoming fully mature. We believe that a unified lakehouse is identified by boundaryless data and lakehouse fusion:
Boundaryless data: Apache Doris serves as a unified query processing engine, breaking down data barriers across different systems. It provides a consistent and ultra-fast analysis experience across all data sources, including data warehouses, data lakes, data streams, and local data files.
Lakehouse query acceleration: Without the need to migrate data to Apache Doris, users can leverage Doris’ efficient query engine to directly query data stored in data lakes such as Iceberg, Hudi, Paimon, and offline data warehouses like Hive, thereby accelerating query analysis.
Federated analysis: By extending its catalog and storage plugins, Apache Doris enhances its federated analysis capabilities, allowing users to perform unified analysis across multiple heterogeneous data sources without physically centralizing the data in a single storage system. This enables external table queries and federated joins between internal and external tables, breaking down data silos and providing globally consistent data insights.
Data lake construction: Apache Doris introduces write-back functionality for Hive and Iceberg, allowing users to directly create Hive and Iceberg tables through Doris and write data into them. This allows users to write internal table data back to the offline lakehouse or process offline lakehouse data using Doris and save the results back into the lakehouse, simplifying and streamlining the data lake construction process.
Lakehouse fusion: As data lake architectures become increasingly complex, the costs of technology selection and maintenance rise for users. Achieving consistent fine-grained access control across multiple systems also becomes challenging, and real-time performance suffers. To address this, Apache Doris integrates core features of the data lake, transforming itself into a lightweight, efficient, native real-time lakehouse.
Real-time data updates: Starting with version 1.2, Apache Doris enhanced the primary key model by introducing Merge-on-Write, supporting real-time updates. This feature allows high-frequency, real-time data updates based on primary key changes from upstream data sources.
Data science and AI computation support: From version 2.1, Apache Doris, using the efficient Arrow Flight protocol, increased the openness of its storage system and its support for various compute loads, enabling data science and AI computations.
Enhancements for semi-structured and unstructured Data: Apache Doris has introduced support for data types like Array, Map, Struct, JSON, and Variant, with plans to support vector indexing in the future.
Improved resource efficiency by decoupling storage and compute: With version 3.0, Apache Doris supports a decoupled storage and compute mode, further improving resource efficiency and scalability.
2-1 Faster queries in the data lakehouse
TPC-H and TPC-DS benchmarking proves that Apache Doris achieves average query performance that is 3 to 5 times faster than Trino/Presto.
In V3.0, we have focused on optimizing query performance for production environments, including:
More granular task splitting strategy: By adjusting the consistent hashing algorithm and introducing a task sharding weighting mechanism, we ensure balanced query loads across all nodes.
Scheduling optimizations for use cases with numerous partitions and files: For cases with a large number of files (over 1 million), we have largely reduced query latency (from 100 seconds to 10 seconds) and alleviated memory pressure on the Frontend (FE) by asynchronously and batch-fetching file shards.
We will continue to specifically enhance query acceleration performance in real-world business scenarios, improve the actual user experience, and build an industry-leading lakehouse query acceleration engine.
2-2 Federated analysis: more data connectors
Previous versions of Apache Doris support connectors for over 10 mainstream data lakehouses, warehouses, and relational databases. In V3.0, we have introduced the Trino Connector compatibility framework, which expands the range of data sources that Apache Doris can connect to. With this framework, users can easily adapt their existing setups to access corresponding data sources using Doris and leverage its high-speed computing engine for data analysis.
Currently, Doris has completed adaptations for Delta Lake, Kudu, BigQuery, Kafka, TPCH, and TPCDS. We also encourage contributions from developers to prolong this list.
See doc:
Trino Connector: https://doris.apache.org/community/how-to-contribute/trino-connector-developer-guide/
TPC-H: https://doris.apache.org/docs/3.0/lakehouse/datalake-analytics/tpch/
TPC-DS: https://doris.apache.org/docs/3.0/lakehouse/datalake-analytics/tpcds/
Delta Lake: https://doris.apache.org/docs/3.0/lakehouse/datalake-analytics/deltalake/
Kudu: https://doris.apache.org/docs/3.0/lakehouse/datalake-analytics/kudu/
BigQuery: https://doris.apache.org/docs/3.0/lakehouse/datalake-analytics/bigquery/
2-3 Data lake building
In V3.0, we have introduced data writeback functionality for Hive and Iceberg. This allows users to create Hive and Iceberg tables directly through Doris and write data into these tables, and enables users to perform data analysis, sharing, processing, and storage operations across multiple data sources within Doris.
In future iterations, Apache Doris will further enhance support for data lake table formats and improve the openness of storage APIs.
3. Upgraded semi-structured data analysis capabilities
In versions 2.0 and 2.1, Apache Doris introduced some well-embraced features such as inverted index, NGram Bloom Filter, and Variant data type to support high-performance full-text search and multi-dimensional analysis. With them, the storage and processing of complex semi-structured data have been more flexible and efficient.
In V3.0, we have further enhanced the capabilities in this scenario.
After extensive testing in production environments, the Variant data type has gained sufficient stability and become the preferred choice for JSON data storage and analysis. In V3.0, we have made multiple optimizations to it:
Support for indexing of the Variant data type to accelerate queries, including inverted index, Bloom Filter index, and the built-in ZoneMap index.
Support for flexible partial column updates for Unique Key tables containing the Variant data type.
Support for the use of the Variant data type in the compute-storage decoupled mode, with optimizations of its metadata storage.
Support for exporting the Variant data type to formats such as Parquet and CSV.
The inverted index, introduced since V2.0, has reached a high level of maturity after more than a year of refinement and is now running in production environments of hundreds of enterprises. In V3.0, we have made multiple optimizations to the inverted index:
After performance optimizations, including lock concurrency, Apache Doris outperforms Elasticsearch in key metrics such as query latency and concurrency in real-time reporting analysis.
Optimized index file in the compute-storage decoupled mode to reduce remote storage calls and decrease index query latency.
Support for the Array data type to accelerate the
array_containsqueries.Enhanced the
match_phrase_*functionality, including support for slop and phrase prefix matchingmatch_phrase_prefix.
4. Enhanced ETL capabilities
4-1. Transaction improvements
Data processing in data warehouses often involves multiple data changes that need to be handled as a single transaction. V3.0 provides explicit transaction support for insert into select, delete, and update operations. Example cases include:
Transactional requirements: For example, when updating data within a time range, the typical approach is to first delete the data in that time range, and then insert the new data. Considering that the data might already be in service, there is a need to ensure that queries visit either the old data or the new data. Thus, it can be achieved by executing the
deleteandinsert into selectoperations in a transaction.BEGIN;
DELETE FROM table WHERE date >= "2024-07-01" AND date <= "2024-07-31";
INSERT INTO table SELECT * FROM stage_table;
COMMIT;Simplified the processing of failed tasks: For example, when two
insert into selectoperations are executed within a single transaction, if any of the operations fail, it can be retried directly.BEGIN WITH LABEL label_etl_1;
INTO table1 SELECT * FROM stage_table1;
INSERT INTO table SELECT * FROM stage_table;
COMMIT;
See doc: https://doris.apache.org/docs/3.0/data-operate/transaction/ Currently, explicit transaction synchronization is not supported in Cross-Cluster Replication (CCR).
4-2. Improved observability
Real-time profile retrieval: In previous versions, due to issues with the execution plan or the data, some complex queries might have high computational requirements, so developers can only access the query profile for performance analysis after the completion of the query. This makes it hard to promptly identify issues in query execution to guarantee stability of the production environment. Now, with the ability to retrieve real-time profiles, V3.0 allows users to monitor query execution as the query is running. It also allows them to better monitor the progress of each ETL job.
backend_active_taskssystem table: Thebackend_active_taskssystem table provides real-time resource consumption information for each query on each BE node. Users can analyze this system table using SQL to obtain the resource usage of each query, which helps identify large queries or abnormal workloads.
5. Asynchronous materialized view
In V3.0, asynchronous materialized view is faster and more stable. It is also more user-friendly for query acceleration and data modeling scenarios. We have restructured the logic for transparent rewrite and expanded its capabilities, making it 2X faster.
5-1 Refresh
Support for incremental update of materialized views by partitions and partition roll-ups on materialized views to allow refreshes at different granularities.
Support for nested materialized views, which is useful in data modeling scenarios.
Support for index creation and sort key specification in asynchronous materialized views, which will improve query performance after the materialized view is hit.
Higher usability of materialized view DDL with support for atomically replacing materialized views, allowing modifications to the materialized view definition SQL while keeping the materialized view available.
Support for non-deterministic functions in materialized views to better serve daily materialized view creation.
Support for trigger-based materialized view refresh, which ensures data consistency in data modeling with nested materialized views.
Support for a broader range of SQL patterns for building partitioned materialized views, making the incremental update capability available to more use cases.
5-2 Refresh stability
- V3.0 supports specifying a Workload Group for building materialized views. This is to limit the resources used by the materialized view build process and ensure that sufficient resources remain available for ongoing queries.
5-3 Transparent rewrite
Support for transparent rewrite of more Join types, including derived Joins. Even when there is a mismatch of Join types between the query and materialized view, transparent rewrite can still be performed by compensating with additional predicates, as long as the materialized view can provide all the data needed for the query.
Support for more aggregate functions for roll-up as well as rewrite of multi-dimensional aggregations like GROUPING SETS, ROLLUP, and CUBE; support rewriting queries with aggregations when the materialized view does not contain aggregations, simplifying Join operations and expression computation.
Support for transparent rewrite of nested materialized views, enabling higher performance for complex queries.
For partially invalid partitioned materialized views, V3.0 supports
Union Allthe base tables for data completion, expanding the applicability of partitioned materialized views.
5-4 Transparent rewrite performance
- Continuous optimization has been done to improve the transparent rewrite performance, achieving 2X the speed compared to version 2.1.0.
6. Performance improvement
6-1 Smarter optimizer
In V3.0, the query optimizer has been enhanced in terms of framework capabilities, distributed plan support, optimizer infrastructure, and rule expansion. It provides better optimization capabilities for more complex and diverse business scenarios, with higher blind test performance for complex SQL:
Improved plan enumeration capability: The key structure Memo for plan enumeration has been restructured and normalized. This improves the efficiency of the Cascades framework in plan enumeration and the possibility of producing better plans. Additionally, it fixes incomplete column pruning during the Join Reorder process in older versions, which led to unnecessary overhead of the Join operator, thus improving the execution performance in the relevant scenarios.
Improved distributed plan support: The distributed query plan has been enhanced to allow aggregation, join, and window function operations to more intelligently identify the data characteristics of intermediate computation results, avoiding ineffective data redistribution operations. Meanwhile, we have optimized the execution under the multi-replica continuous execution mode, making it more data cache-friendly.
Improved optimizer infrastructure: V3 has fixed several issues in cost model and statistics information estimation. The fixes to the cost model are more adaptable to the evolution of the execution engine, making the execution plan more stable compared to previous versions.
Enhanced Runtime Filter plan support: On the basis of Join Runtime Filter, V3.0 has expanded the capability of the TopN Runtime Filter to achieve better performance in use cases that involve a TopN operator.
Enriched optimization rule library: Based on user feedback and internal testing results, we have introduced optimization rules such as Intersect Reorder to enrich the rule set of the optimizer.
6-2 Self-adaptive Runtime Filter
In previous versions, the generation of Runtime Filter relies on manual setting by users based on statistical information. However, inaccurate settings in certain cases could lead to performance instability.
In V3.0, Doris implements a self-adaptive Runtime Filter calculation approach. It can estimate the Runtime Filter at runtime based on the data size with high accuracy, enabling better performance in use cases with large data volumes and high workloads.
6-3 Function performance optimization
- V3.0 has improved the vectorized implementation of dozens of functions, enabling a performance improvement of over 50% for some commonly used functions.
- V3.0 has also made extensive optimizations to the aggregation of nullable data types, enabling a 30% performance improvement.
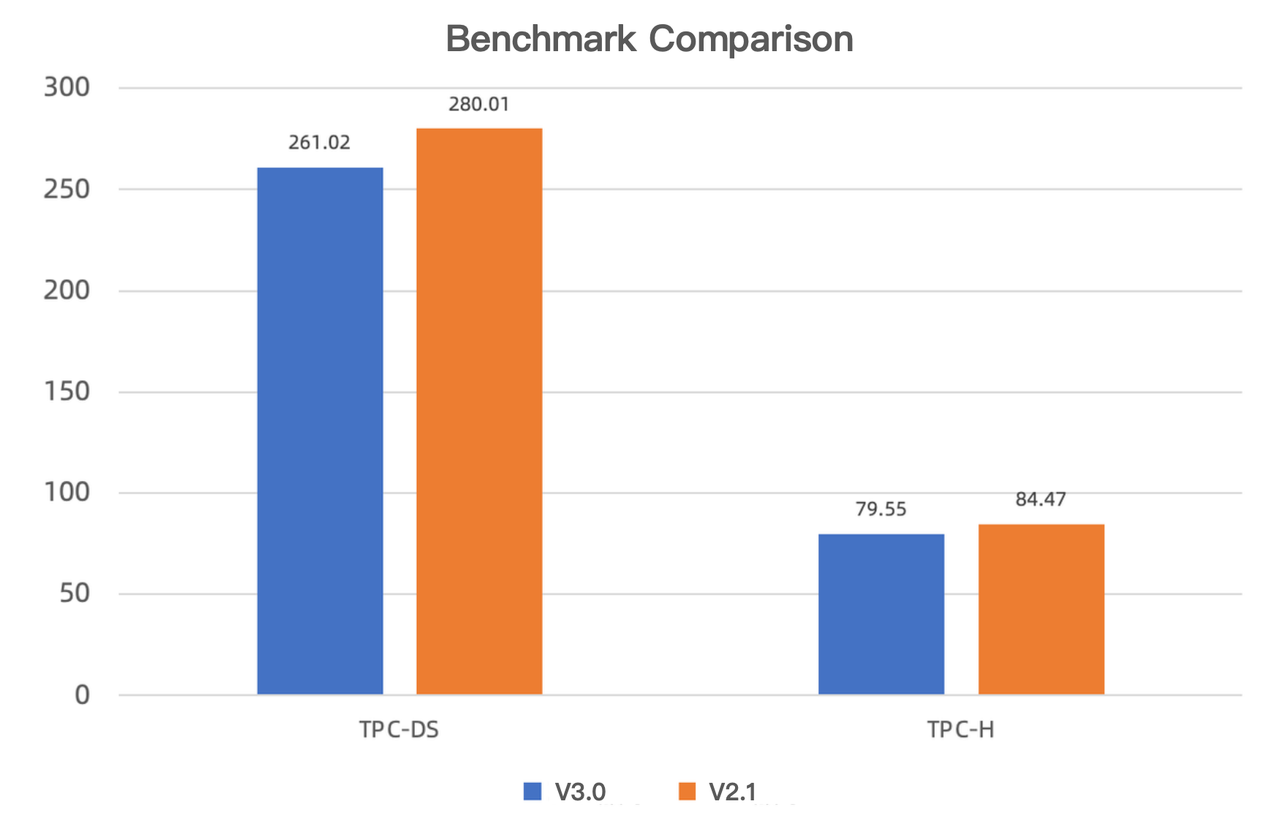
6-4 Blind test performance improvement
Our blind tests on V3.0 and V2.1 show that the new version is 7.3% and 6.2% faster in TPC-DS and TPC-H benchmark tests, respectively.
7. New features
7-1 Java UDTF
Version 3.0 has added support for Java UDTFs. The key operations are as follows:
Implementing a UDTF: Similar to a UDF, a UDTF requires the user to implement an
evaluatemethod. Note that the return value of a UDTF function must be of theArraydata type.public class UDTFStringTest {
public ArrayList<String> evaluate(String value, String separator) {
if (value == null || separator == null) {
return null;
} else {
return new ArrayList<>(Arrays.asList(value.split(separator)));
}
}
}Creating a UDTF: By default, two corresponding functions will be created -
java-utdfandjava-utdf_outer. The_outersuffix adds a single row ofNULLdata when the table function generates 0 rows of output.CREATE TABLES FUNCTION java-utdf(string, string) RETURNS array<string> PROPERTIES (
"file"="file:///pathTo/java-udaf.jar",
"symbol"="org.apache.doris.udf.demo.UDTFStringTest",
"always_nullable"="true",
"type"="JAVA_UDF"
);
7-2 Generated column
A generated column is a special column whose value is calculated from the values of other columns rather than directly inserted or updated by the user. It supports pre-computing the results of expressions and storing them in the database, which is suitable for scenarios that require frequent queries or complex calculations.
Results can be automatically calculated based on predefined expressions when data is imported or updated, and then stored persistently. In this way, during subsequent queries, the system can directly access these calculated results without performing complex calculations, thereby improving query performance.
Generated columns are supported since V3.0. When creating a table, you can specify a column as generated column. A generated column automatically calculates values based on the defined expression when data is written. Generated columns allow for more complex expressions to be defined, but the value cannot be explicitly written or set.
8. Functional improvements
8-1. Materialized view
We have refactored the selection logic for materialized views and migrated it from the rule-based optimizer (RBO) to the cost-based optimizer (CBO). This aligns the selection logic with that of asynchronous materialized views. This functionality is enabled by default. If any issues are encountered, you can revert to the RBO mode using set global enable_sync_mv_cost_based_rewrite = false.
8-2. Routine Load
In previous versions, the Routine Load functionality faced some usability challenges, such as uneven task scheduling across BE nodes, untimely task scheduling, complex configuration requirements (the need to change multiple FE and BE settings for optimization), insufficient overall stability (where restarts or upgrades could frequently pause Routine Load jobs, requiring manual user intervention to resume).
To address these issues, we have made extensive optimizations to the Routine Load feature:
Resource scheduling: We have improved the scheduling balance to make sure that tasks are more evenly distributed across BE nodes. Jobs that encounter unrepairable errors will be promptly paused to avoid wasting resources on futile scheduling attempts. Additionally, we have improved the timeliness of the scheduling process, which has enhanced the import performance of Routine Load.
Parameter configuration: Users in most environments no longer need to modify FE and BE configurations for optimization. An automatic adjustment mechanism with timeout parameter has been introduced to prevent tasks from constantly retrying when cluster pressure increases.
Stability: We have enhanced the robustness of Doris in various exceptional scenarios, such as FE failovers, BE rolling upgrades, and Kafka cluster anomalies, ensuring continuous stable operation. We have also optimized the Auto Resume mechanism, allowing Routine Load to automatically resume operation after faults are repaired, reducing the need for manual user intervention.
9. Behavior changed
cpu_resource_limitwill no longer be supported, and all types of resource isolation will be implemented through Workload Groups.Please use JDK 17 for Apache Doris 3.0 and later versions. The recommended version being
jdk-17.0.10_linux-x64_bin.tar.gz.
Try Apache Doris 3.0 now!
Before the official release of version 3.0, the compute-storage decoupled mode of Apache Doris has undergone nearly two years of extensive testing and optimization in the production environments of hundreds of enterprises. Contributors from many tech giants have collaborated with the community to provide a significant number of test cases based on their real-world business needs. This has rigorously validated the usability and stability of version 3.0.
We highly recommend users with compute-storage decoupling needs to download version 3.0 and experience it firsthand.
Going forward, we will accelerate our release iteration cycle to deliver a more stable version experience for all users. Feel free to join us in the Apache Doris community and engage directly with the core developers.
Credits
Special thanks to the following contributors who participated in the development, testing, and provided feedback for this version:
@133tosakarin、@390008457、@924060929、@AcKing-Sam、@AshinGau、@BePPPower、@BiteTheDDDDt、@ByteYue、@CSTGluigi、@CalvinKirs、@Ceng23333、@DarvenDuan、@DongLiang-0、@Doris-Extras、@Dragonliu2018、@Emor-nj、@FreeOnePlus、@Gabriel39、@GoGoWen、@HappenLee、@HowardQin、@Hyman-zhao、@INNOCENT-BOY、@JNSimba、@JackDrogon、@Jibing-Li、@KassieZ、@Lchangliang、@LemonLiTree、@LiBinfeng-01、@LompleZ、@M1saka2003、@Mryange、@Nitin-Kashyap、@On-Work-Song、@SWJTU-ZhangLei、@StarryVerse、@TangSiyang2001、@Tech-Circle-48、@Thearas、@Vallishp、@WinkerDu、@XieJiann、@XuJianxu、@XuPengfei-1020、@Yukang-Lian、@Yulei-Yang、@Z-SWEI、@ZhongJinHacker、@adonis0147、@airborne12、@allenhooo、@amorynan、@bingquanzhao、@biohazard4321、@bobhan1、@caiconghui、@cambyzju、@caoliang-web、@catpineapple、@cjj2010、@csun5285、@dataroaring、@deardeng、@dongsilun、@dutyu、@echo-hhj、@eldenmoon、@elvestar、@englefly、@feelshana、@feifeifeimoon、@feiniaofeiafei、@felixwluo、@freemandealer、@gavinchou、@ghkang98、@gnehil、@hechao-ustc、@hello-stephen、@httpshirley、@hubgeter、@hust-hhb、@iszhangpch、@iwanttobepowerful、@ixzc、@jacktengg、@jackwener、@jeffreys-cat、@kaijchen、@kaka11chen、@kindred77、@koarz、@kobe6th、@kylinmac、@larshelge、@liaoxin01、@lide-reed、@liugddx、@liujiwen-up、@liutang123、@lsy3993、@luwei16、@luzhijing、@lxliyou001、@mongo360、@morningman、@morrySnow、@mrhhsg、@my-vegetable-has-exploded、@mymeiyi、@nanfeng1999、@nextdreamblue、@pingchunzhang、@platoneko、@py023、@qidaye、@qzsee、@raboof、@rohitrs1983、@rotkang、@ryanzryu、@seawinde、@shoothzj、@shuke987、@sjyango、@smallhibiscus、@sollhui、@sollhui、@spaces-X、@stalary、@starocean999、@superdiaodiao、@suxiaogang223、@taptao、@vhwzx、@vinlee19、@w41ter、@wangbo、@wangshuo128、@whutpencil、@wsjz、@wuwenchi、@wyxxxcat、@xiaokang、@xiedeyantu、@xiedeyantu、@xingyingone、@xinyiZzz、@xy720、@xzj7019、@yagagagaga、@yiguolei、@yongjinhou、@ytwp、@yuanyuan8983、@yujun777、@yuxuan-luo、@zclllyybb、@zddr、@zfr9527、@zgxme、@zhangbutao、@zhangstar333、@zhannngchen、@zhiqiang-hhhh、@ziyanTOP、@zxealous、@zy-kkk、@zzzxl1993、@zzzzzzzs
