Doris Storage File Format Optimization
File format
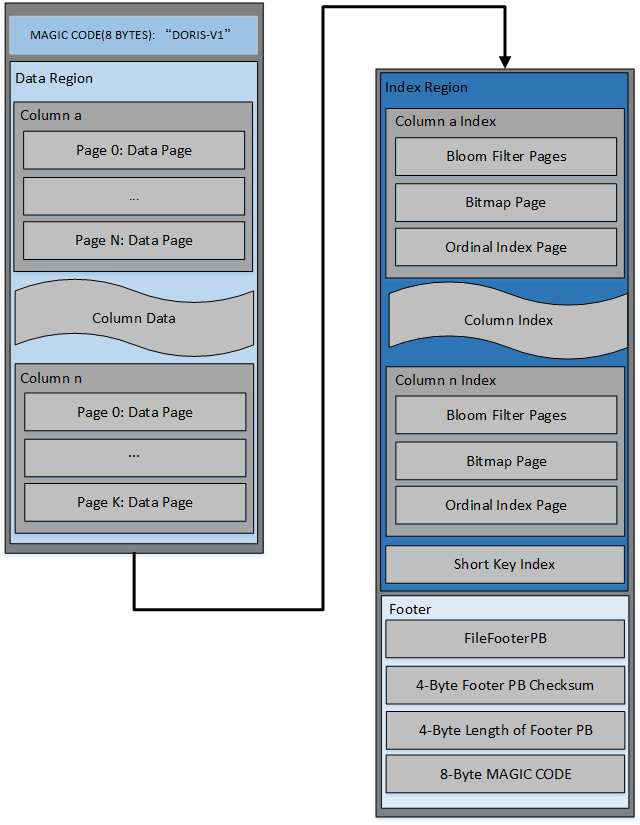
Documents include:
- The file starts with an 8-byte magic code to identify the file format and version
- Data Region: Used to store data information for each column, where the data is loaded on demand by pages.
- Index Region: Doris stores the index data of each column in Index Region, where the data is loaded according to column granularity, so the data information of the following column is stored separately.
- Footer
- FileFooterPB: Metadata Information for Definition Files
- Checksum of 4 bytes of footer Pb content
- Four bytes FileFooterPB message length for reading FileFooterPB
- The 8 byte MAGIC CODE is stored in the last bit to facilitate the identification of file types in different scenarios.
The data in the file is organized in the form of page, which is the basic unit of coding and compression. Current page types include the following:
DataPage
Data Page is divided into two types: nullable and non-nullable data pages.
Nullable's data page includes:
+----------------+
| value count |
|----------------|
| first row id |
|----------------|
| bitmap length |
|----------------|
| null bitmap |
|----------------|
| data |
|----------------|
| checksum |
+----------------+
non -zero data page32467;- 26500;- 229140;-
|----------------|
| value count |
|----------------|
| first row id |
|----------------|
| data |
|----------------|
| checksum |
+----------------+
The meanings of each field are as follows:
- value count
- Represents the number of rows in a page
- First row id
- Line number of the first line in page
- bitmap length
- Represents the number of bytes in the next bitmap
- null bitmap
- bitmap representing null information
- Data
- Store data after encoding and compress
- You need to write in the header information of the data: is_compressed
- Various kinds of data encoded by different codes need to write some field information in the header information in order to achieve data parsing.
- TODO: Add header information for various encodings
- Checksum
- Store page granularity checksum, including page header and subsequent actual data
Bloom Filter Pages
For each bloom filter column, a page of the bloom filter is generated corresponding to the granularity of the page and saved in the bloom filter pages area.
Ordinal Index Page
For each column, a sparse index of row numbers is established according to page granularity. The content is a pointer to the block (including offset and length) for the line number of the start line of the page
Short Key Index page
We generate a sparse index of short key every N rows (configurable) with the contents of short key - > line number (ordinal)
Column's other indexes
The format design supports the subsequent expansion of other index information, such as inverted index, spatial index, etc. It only needs to write the required data to the existing column data, and add the corresponding metadata fields to FileFooterPB.
Metadata Definition
SegmentFooterPB is defined as:
message ColumnPB {
required int32 unique_id = 1; // The column id is used here, and the column name is not used
optional string name = 2; // Column name, when name equals __DORIS_DELETE_SIGN__, this column is a hidden delete column
required string type = 3; // Column type
optional bool is_key = 4; // Whether column is a primary key column
optional string aggregation = 5; // Aggregate type
optional bool is_nullable = 6; // Whether column is allowed to assign null
optional bytes default_value = 7; // Default value
optional int32 precision = 8; // Precision of column
optional int32 frac = 9;
optional int32 length = 10; // Length of column
optional int32 index_length = 11; // Length of column index
optional bool is_bf_column = 12; // Whether column has bloom filter index
optional bool has_bitmap_index = 15 [default=false]; // Whether column has bitmap index
}
// page offset
message PagePointerPB {
required uint64 offset; // offset of page in segment file
required uint32 length; // length of page
}
message MetadataPairPB {
optional string key = 1;
optional bytes value = 2;
}
message ColumnMetaPB {
optional ColumnMessage encoding; // Encoding of column
optional PagePointerPB dict_page // Dictionary page
repeated PagePointerPB bloom_filter_pages; // Bloom filter pages
optional PagePointerPB ordinal_index_page; // Ordinal index page
optional PagePointerPB page_zone_map_page; // Page level of statistics index data
optional PagePointerPB bitmap_index_page; // Bitmap index page
optional uint64 data_footprint; // The size of the index in the column
optional uint64 index_footprint; // The size of the data in the column
optional uint64 raw_data_footprint; // Original column data size
optional CompressKind compress_kind; // Column compression type
optional ZoneMapPB column_zone_map; // Segment level of statistics index data
repeated MetadataPairPB column_meta_datas;
}
message SegmentFooterPB {
optional uint32 version = 2 [default = 1]; // For version compatibility and upgrade use
repeated ColumnPB schema = 5; // Schema of columns
optional uint64 num_values = 4; // Number of lines saved in the file
optional uint64 index_footprint = 7; // Index size
optional uint64 data_footprint = 8; // Data size
optional uint64 raw_data_footprint = 8; // Original data size
optional CompressKind compress_kind = 9 [default = COMPRESS_LZO]; // Compression type
repeated ColumnMetaPB column_metas = 10; // Column metadata
optional PagePointerPB key_index_page = 11; // short key index page
}
Read-write logic
Write
The general writing process is as follows:
- Write magic
- Generate corresponding Column Writer according to schema information. Each Column Writer obtains corresponding encoding information (configurable) according to different types, and generates corresponding encoder according to encoding.
- Call encoder - > add (value) for data writing. Each K line generates a short key index entry, and if the current page satisfies certain conditions (the size exceeds 1M or the number of rows is K), a new page is generated and cached in memory.
- Continuous cycle step 3 until data writing is completed. Brush the data of each column into the file in sequence
- Generate FileFooterPB information and write it to the file.
Relevant issues:
-
How does the index of short key be generated?
- Now we still generate a short key sparse index according to how many rows are sparse, and keep a short sparse index generated every 1024 rows. The specific content is: short key - > ordinal
-
What should be stored in the ordinal index?
- Store the first ordinal to page pointer mapping information for pages
-
What are stored in pages of different encoding types?
- Dictionary Compression
- plain
- rle
- bshuf
Read
- Read the magic of the file and judge the type and version of the file.
- Read FileFooterPB and check sum
- Read short key index and data ordinal index information of corresponding columns according to required columns
- Use start key and end key, locate the row number to be read through short key index, then determine the row ranges to be read through ordinal index, and filter the row ranges to be read through statistics, inverted index and so on.
- Then read row data through ordinal index according to row ranges
Relevant issues:
-
How to quickly locate a row within the page?
The data inside the page is encoding, so it cannot locate the row-level data quickly. Different encoding methods have different schemes for fast line number positioning in-house, which need to be analyzed concretely:
- If it is rle-coded, skip is performed by resolving the head of RLE until the RLE block containing the row is reached, and then the reverse solution is performed.
- binary plain encoding: offset information will be stored in the page, and offset information will be specified in the page header. When reading, offset information will be parsed into the array first, so that you can quickly locate the data of a row of block through offset data information of each row.
-
How to achieve efficient block reading? Consider merging adjacent blocks while they are being read, one-time reading? This requires judging whether the block is continuous at the time of reading, and if it is continuous, reading it once.
Coding
In the existing Doris storage, plain encoding is adopted for string type encoding, which is inefficient. After comparison, it is found that in Baidu statistics scenario, data will expand more than twice because of string type coding. Therefore, it is planned to introduce dictionary-based coding compression.
Compression
It implements a scalable compression framework, supports a variety of compression algorithms, facilitates the subsequent addition of new compression algorithms, and plans to introduce zstd compression.
TODO
- How to implement nested types? How to locate line numbers in nested types?
- How to optimize the downstream inverted index and column statistics caused by ScanRange splitting?
