Bucket Shuffle Join
Bucket Shuffle Join is a new function officially added in Doris 0.14. The purpose is to provide local optimization for some join queries to reduce the time-consuming of data transmission between nodes and speed up the query.
It's design, implementation can be referred to ISSUE 4394。
Noun Interpretation
- FE: Frontend, the front-end node of Doris. Responsible for metadata management and request access.
- BE: Backend, Doris's back-end node. Responsible for query execution and data storage.
- Left table: the left table in join query. Perform probe expr. The order can be adjusted by join reorder.
- Right table: the right table in join query. Perform build expr The order can be adjusted by join reorder.
Principle
The conventional distributed join methods supported by Doris is: Shuffle Join, Broadcast Join. Both of these join will lead to some network overhead.
For example, there are join queries for table A and table B. the join method is hashjoin. The cost of different join types is as follows:
- Broadcast Join: If table a has three executing hashjoinnodes according to the data distribution, table B needs to be sent to the three HashJoinNode. Its network overhead is
3B, and its memory overhead is3B. - Shuffle Join: Shuffle join will distribute the data of tables A and B to the nodes of the cluster according to hash calculation, so its network overhead is
A + Band memory overhead isB.
The data distribution information of each Doris table is saved in FE. If the join statement hits the data distribution column of the left table, we should use the data distribution information to reduce the network and memory overhead of the join query. This is the source of the idea of bucket shuffle join.
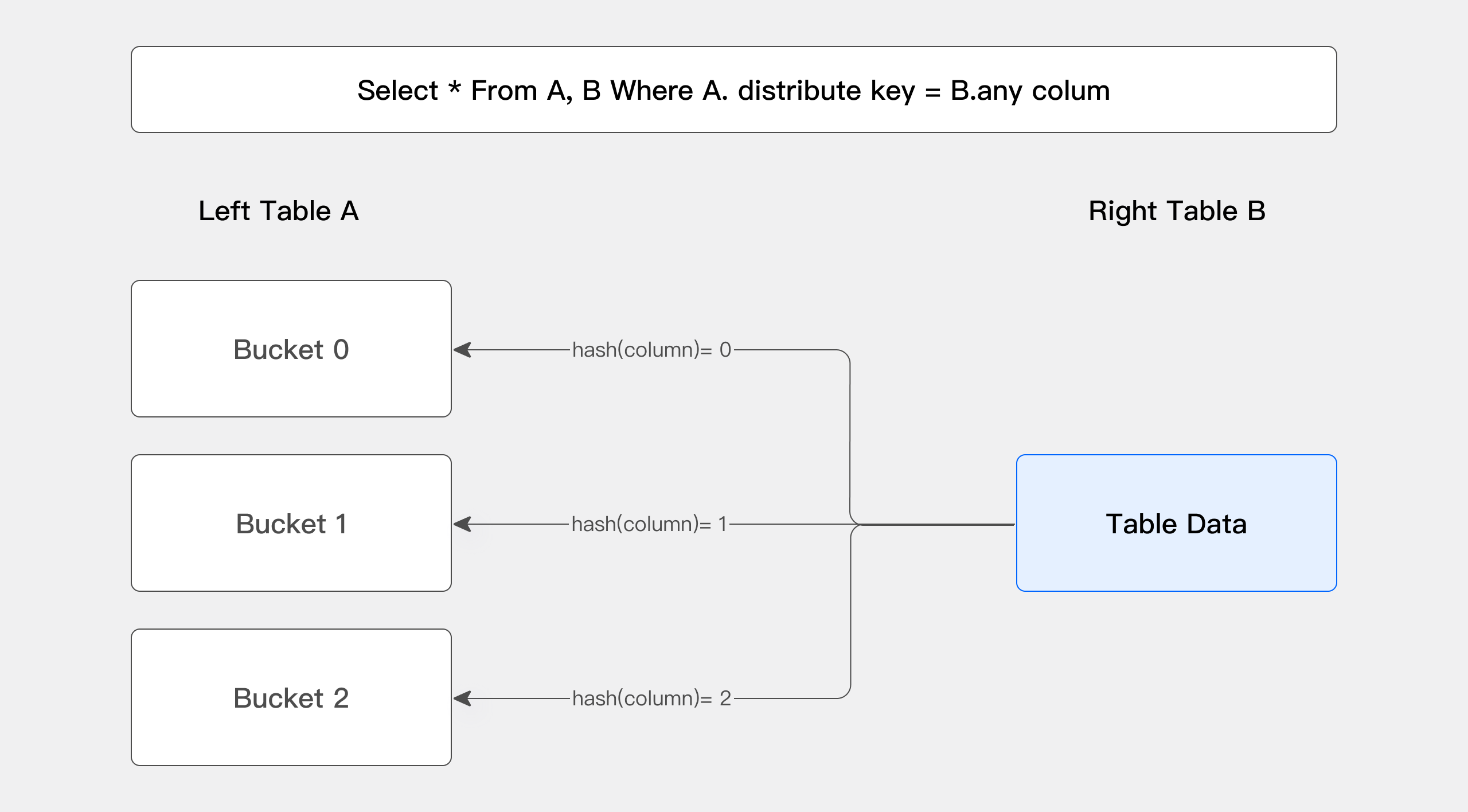
The picture above shows how the Bucket Shuffle Join works. The SQL query is A table join B table. The equivalent expression of join hits the data distribution column of A. According to the data distribution information of table A. Bucket Shuffle Join sends the data of table B to the corresponding data storage and calculation node of table A. The cost of Bucket Shuffle Join is as follows:
-
network cost:
B < min(3B, A + B) -
memory cost:
B <= min(3B, B)
Therefore, compared with Broadcast Join and Shuffle Join, Bucket shuffle join has obvious performance advantages. It reduces the time-consuming of data transmission between nodes and the memory cost of join. Compared with Doris's original join method, it has the following advantages
- First of all, Bucket Shuffle Join reduces the network and memory cost which makes some join queries have better performance. Especially when FE can perform partition clipping and bucket clipping of the left table.
- Secondly, unlike Colorate Join, it is not intrusive to the data distribution of tables, which is transparent to users. There is no mandatory requirement for the data distribution of the table, which is not easy to lead to the problem of data skew.
- Finally, it can provide more optimization space for join reorder.
Usage
Set session variable
Set session variable enable_bucket_shuffle_join to true, FE will automatically plan queries that can be converted to Bucket Shuffle Join.
set enable_bucket_shuffle_join = true;
In FE's distributed query planning, the priority order is Colorate Join -> Bucket Shuffle Join -> Broadcast Join -> Shuffle Join. However, if the user explicitly hints the type of join, for example:
select * from test join [shuffle] baseall on test.k1 = baseall.k1;
the above order of preference will not take effect.
The session variable is set to true by default in version 0.14, while it needs to be set to true manually in version 0.13.
View the type of join
You can use the explain command to check whether the join is a Bucket Shuffle Join
| 2:HASH JOIN |
| | join op: INNER JOIN (BUCKET_SHUFFLE) |
| | hash predicates: |
| | colocate: false, reason: table not in the same group |
| | equal join conjunct: `test`.`k1` = `baseall`.`k1`
The join type indicates that the join method to be used is:BUCKET_SHUFFLE。
Planning rules of Bucket Shuffle Join
In most scenarios, users only need to turn on the session variable by default to transparently use the performance improvement brought by this join method. However, if we understand the planning rules of Bucket Shuffle Join, we can use it to write more efficient SQL.
- Bucket Shuffle Join only works when the join condition is equivalent. The reason is similar to Colorate Join. They all rely on hash to calculate the determined data distribution.
- The bucket column of two tables is included in the equivalent join condition. When the bucket column of the left table is an equivalent join condition, it has a high probability of being planned as a Bucket Shuffle Join.
- Because the hash values of different data types have different calculation results. Bucket Shuffle Join requires that the bucket column type of the left table and the equivalent join column type of the right table should be consistent, otherwise the corresponding planning cannot be carried out.
- Bucket Shuffle Join only works on Doris native OLAP tables. For ODBC, MySQL, ES External Table, when they are used as left tables, they cannot be planned as Bucket Shuffle Join.
- For partitioned tables, because the data distribution rules of each partition may be different, the Bucket Shuffle Join can only guarantee that the left table is a single partition. Therefore, in SQL execution, we need to use the
wherecondition as far as possible to make the partition clipping policy effective. - If the left table is a colorate table, the data distribution rules of each partition are determined. So the bucket shuffle join can perform better on the colorate table.
