BloomFilter Index
Indexing Principles
The BloomFilter index is a type of skip list index based on BloomFilter. Its principle is to use BloomFilter to skip data blocks that do not meet the specified conditions for equality queries, thereby reducing IO and accelerating queries.
BloomFilter is a fast lookup algorithm proposed by Bloom in 1970, which uses multiple hash functions. It is commonly used in scenarios where quick determination of whether an element belongs to a set is needed without requiring 100% accuracy. BloomFilter has the following characteristics:
- A space-efficient probabilistic data structure used to check if an element is in a set.
- For a membership check, BloomFilter returns one of two results: possibly in the set or definitely not in the set.
A BloomFilter consists of a very long binary bit array and a series of hash functions. The bit array is initially all set to 0. When an element is to be checked, it is hashed by a series of hash functions to generate a series of values, and the bits at these positions in the array are set to 1.
The figure below shows an example of a BloomFilter with m=18 and k=3 (where m is the size of the bit array and k is the number of hash functions). Elements x, y, and z in the set are hashed by 3 different hash functions into the bit array. When querying element w, if any bit calculated by the hash functions is 0, then w is not in the set. Conversely, if all bits are 1, it only indicates that w may be in the set, but not definitely, due to possible hash collisions.
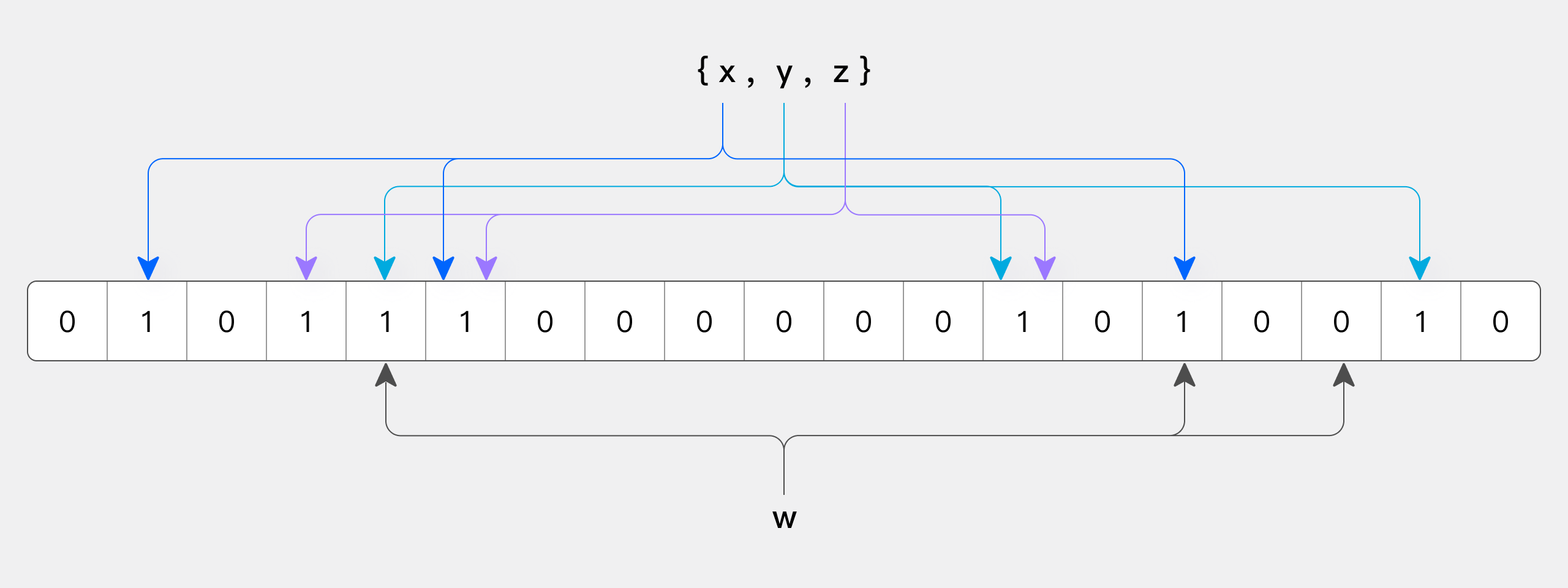
Thus, if all bits at the calculated positions are 1, it only indicates that the element may be in the set, not definitely, due to possible hash collisions. This is the "false positive" nature of BloomFilter. Therefore, a BloomFilter-based index can only skip data that does not meet the conditions but cannot precisely locate data that does.
The Doris BloomFilter index is built on a per-page basis, with each data block storing a BloomFilter. During writing, each value in the data block is hashed into the corresponding BloomFilter. During querying, for equality conditions, it is checked if the BloomFilter of each data block contains the value. If not, the data block is skipped, reducing IO and speeding up the query.
Use Cases
BloomFilter indexes can accelerate equality queries (including = and IN) and are effective for high cardinality fields, such as unique id fields like userid.
BloomFilter has the following limitations:
- It has no effect on queries other than in and =, such as !=, NOT IN, >, <, etc.
- It does not support BloomFilter indexing on columns of type Tinyint, Float, Double.
- It has limited acceleration effect on low cardinality fields. For example, a "gender" field with only two values will likely be included in almost every data block, making the BloomFilter index meaningless.
To check the effect of a BloomFilter index on a query, you can analyze relevant metrics in the Query Profile.
- BlockConditionsFilteredBloomFilterTime is the time consumed by the BloomFilter index.
- RowsBloomFilterFiltered is the number of rows filtered out by the BloomFilter. You can compare it with other Rows values to analyze the filtering effect of the BloomFilter index.
Syntax
Creating a BloomFilter Index When Creating a Table
Due to historical reasons, the syntax for defining BloomFilter indexes differs from the general INDEX syntax used for inverted indexes. BloomFilter indexes are specified in the table's PROPERTIES using "bloom_filter_columns", which can specify one or more fields.
PROPERTIES (
"bloom_filter_columns" = "column_name1,column_name2"
);
Viewing BloomFilter Indexes
SHOW CREATE TABLE table_name;
Adding or Removing BloomFilter Indexes on an Existing Table
Modify the table's bloom_filter_columns property via ALTER TABLE to add or remove BloomFilter indexes.
Add a BloomFilter index for column_name3
ALTER TABLE table_name SET ("bloom_filter_columns" = "column_name1,column_name2,column_name3");
Remove the BloomFilter index for column_name1
ALTER TABLE table_name SET ("bloom_filter_columns" = "column_name2,column_name3");
Usage Example
Here is an example of how to create a BloomFilter index in Doris.
Creating a BloomFilter Index
The BloomFilter index in Doris is created by adding the "bloom_filter_columns" property in the CREATE TABLE statement, with k1, k2, k3 being the key columns for the BloomFilter index. For example, the following creates BloomFilter indexes on saler_id and category_id.
CREATE TABLE IF NOT EXISTS sale_detail_bloom (
sale_date date NOT NULL COMMENT "Sale date",
customer_id int NOT NULL COMMENT "Customer ID",
saler_id int NOT NULL COMMENT "Salesperson",
sku_id int NOT NULL COMMENT "Product ID",
category_id int NOT NULL COMMENT "Product category",
sale_count int NOT NULL COMMENT "Sales quantity",
sale_price DECIMAL(12,2) NOT NULL COMMENT "Unit price",
sale_amt DECIMAL(20,2) COMMENT "Total sales amount"
)
DUPLICATE KEY(sale_date, customer_id, saler_id, sku_id, category_id)
DISTRIBUTED BY HASH(saler_id) BUCKETS 10
PROPERTIES (
"replication_num" = "1",
"bloom_filter_columns"="saler_id,category_id"
);
