Optimizing Join with Colocate Group
Defining colocate group is an efficient way of Join, through which the execution engine can effectively avoid the transmission overhead of input data in Join operations (for an introduction to Colocate Group, see Colocation Join)
However, in some use cases, even if a Colocate Group has been successfully established, the execution plan may still show as Shuffle Join or Bucket Shuffle Join. This situation typically occurs when Doris is in the process of data organization, for instance, it may be migrating tablets between BE to ensure a more balanced distribution of data across multiple BE.
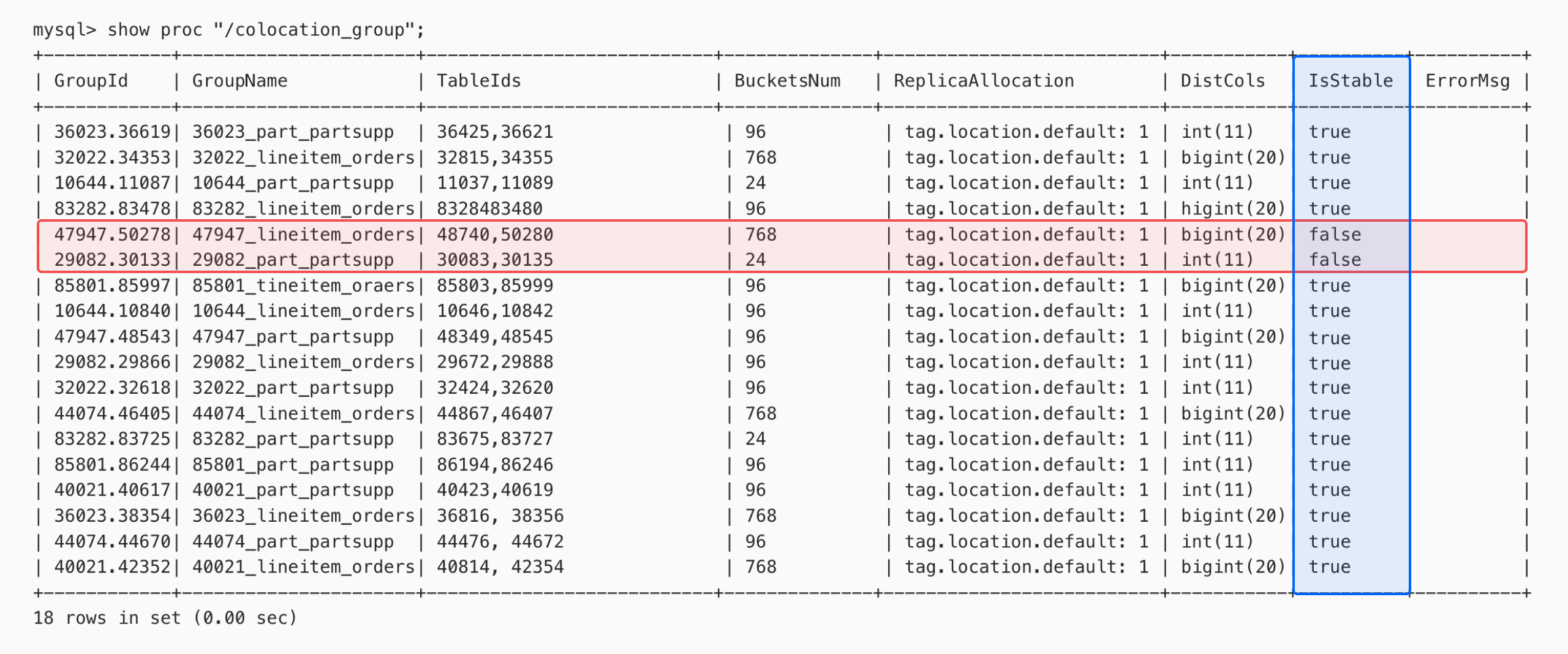
You can view the Colocate Group status using the command show proc "/colocation_group"; as shown in the figure below: If IsStable appears as false, it indicates that there are unavailable colocation group instances.