Memory Control Strategy
Doris Allocator is the unified entry point for large-block memory applications in the system. It intervenes in the process of limiting memory allocation at the right time to ensure efficient and controllable memory applications.
Doris MemoryArbitrator is a memory arbitrator that monitors the memory usage of the Doris BE process in real time, and regularly updates the memory status and collects snapshots of memory-related statistics.
Doris MemoryReclamation is a memory reclaimer that triggers memory GC to reclaim part of the memory when the available memory is insufficient, ensuring the stability of most task executions on the cluster.
Doris Allocator
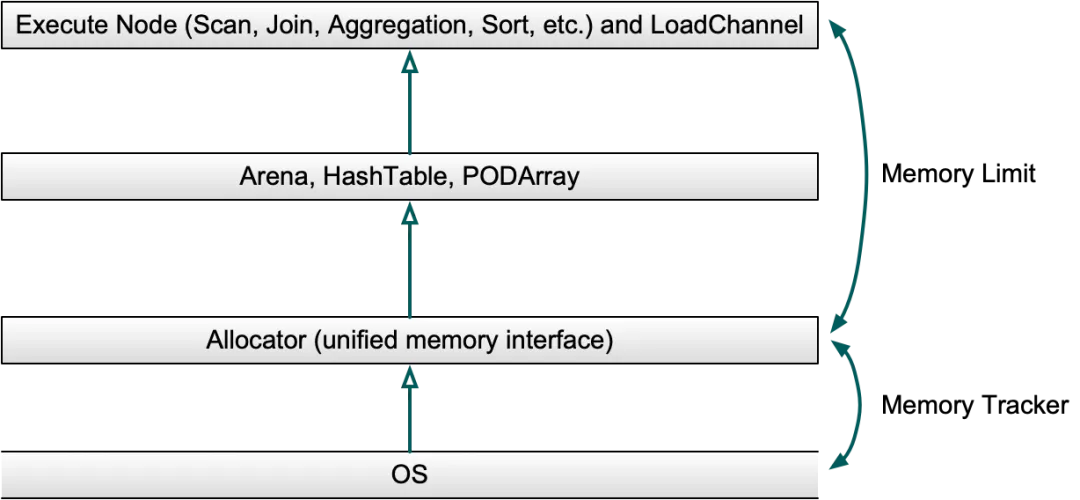
Allocator applies for memory from the system and uses MemTracker to track the size of memory applications and releases during the application process. The large memory required for executing operators in batches will be managed by different data structures.
During the query execution process, the allocation of large blocks of memory is mainly managed by Arena, HashTable, and PODArray data structures. Allocator serves as the unified memory interface of Arena, PODArray, and HashTable to achieve unified memory management and local memory reuse.
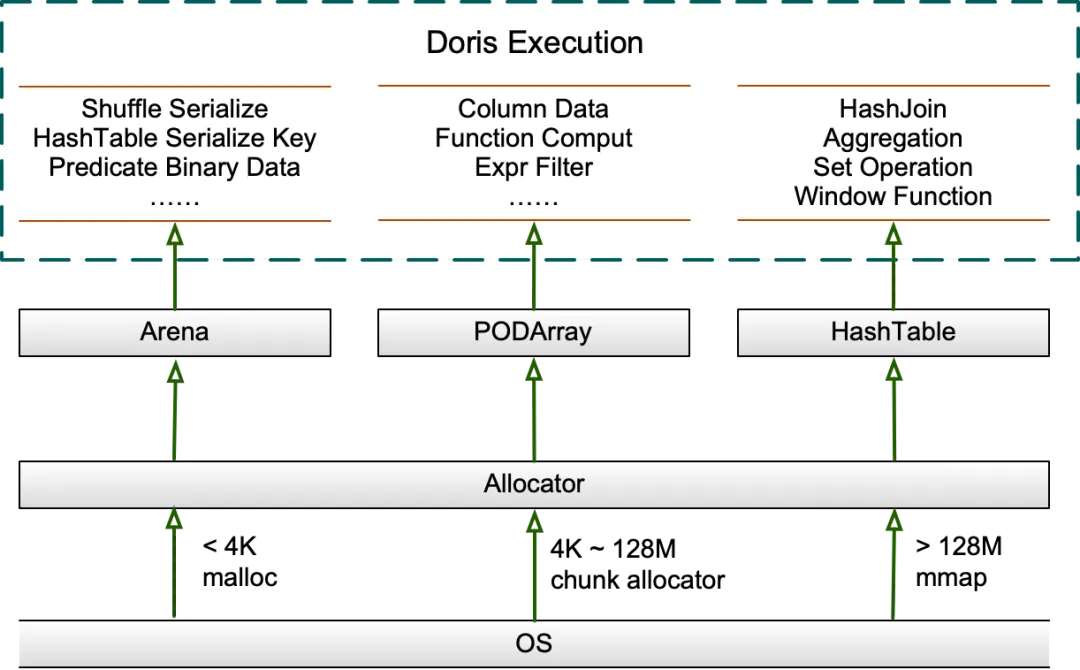
Allocator uses a general memory allocator to apply for memory. In the choice of Jemalloc and TCMalloc, Doris previously used the Spin Lock of CentralFreeList in TCMalloc to account for 40% of the total query time in high-concurrency tests. Although turning off aggressive memory decommit can effectively improve performance, it will waste a lot of memory. For this reason, a separate thread has to be used to periodically recycle the TCMalloc cache. Jemalloc outperforms TCMalloc under high concurrency and is mature and stable. In Doris 1.2.2, Jemalloc was switched to. After tuning, the performance is on par with TCMalloc in most scenarios, and it uses less memory. The performance of high-concurrency scenarios is also significantly improved.
Arena
Arena is a memory pool that maintains a list of memory blocks and allocates memory from them to respond to alloc requests, thereby reducing the number of times memory is requested from the system to improve performance. The memory block is called Chunk, which exists throughout the life cycle of the memory pool and is uniformly released during destruction, which is usually the same as the query life cycle. It also supports memory alignment and is mainly used to save serialized/deserialized data during the Shuffle process, serialized Key in HashTable, etc.
Chunk is initially 4096 bytes, and uses a cursor to record the allocated memory location internally. If the remaining size of the current Chunk cannot meet the current memory request, a new Chunk is requested and added to the list. To reduce the number of times memory is requested from the system, when the current Chunk is less than 128M, the size of each newly requested Chunk is doubled. When the current Chunk is greater than 128M, the size of the newly requested Chunk is allocated up to 128M on the premise of meeting the current memory request, to avoid wasting too much memory. By default, the previous Chunk will no longer participate in subsequent alloc.
HashTable
HashTable in Doris is mainly used in Hash Join, aggregation, set operation, and window function. The mainly used PartitionedHashTable contains up to 16 sub-HashTables, supports parallel merging of two HashTables, and each sub-Hash Join is independently expanded, which is expected to reduce the use of total memory, and the delay during expansion will also be amortized.
When the HashTable is less than 8M, it will be expanded by a multiple of 4. When the HashTable is greater than 8M, it will be expanded by a multiple of 2. When the HashTable is less than 2G, the expansion factor is 50%, that is, the expansion is triggered when the HashTable is filled to 50%. After the HashTable is greater than 2G, the expansion factor is adjusted to 75%. In order to avoid wasting too much memory, the HashTable is usually pre-expanded according to the amount of data before building it. In addition, Doris designed different HashTables for different scenarios, such as using PHmap to optimize concurrent performance in aggregation scenarios.
PODArray
PODArray is a dynamic array of POD type. It is different from std::vector in that it does not initialize elements, supports some std::vector interfaces, supports memory alignment and expansion in multiples of 2. When PODArray is destructed, it does not call the destructor of each element, but directly releases the entire block of memory. It is mainly used to save data in columns such as String. In addition, it is also widely used in function calculation and expression filtering.
Memory reuse
Doris has done a lot of memory reuse in the execution layer, and the visible memory hotspots are basically blocked. For example, the reuse of data blocks Block runs through the execution of Query; for example, the Sender end of Shuffle always keeps one Block to receive data, and one Block is used alternately in RPC transmission; and the storage layer reuses the predicate column to read, filter, copy to the upper layer Block, and Clear when reading a Tablet; when load the Aggregate Key table, the MemTable of cached data reaches a certain size and then shrinks after pre-aggregation and continues to write, etc.
In addition, Doris will pre-allocate a batch of Free Blocks based on the number of Scanners and threads before the data Scan starts. Each time the Scanner is scheduled, a Block will be obtained from it and passed to the storage layer to read the data. After the reading is completed, the Block will be placed in the producer queue for consumption by the upper-layer operator and subsequent calculations. After the upper-layer operator copies the data, it will put the Block back into the Free Block for the next Scanner scheduling, thereby realizing memory reuse. After the data Scan is completed, the Free Block will be uniformly released in the previously pre-allocated threads to avoid the extra overhead caused by memory application and release not being in the same thread. The number of Free Blocks also controls the concurrency of data Scan to a certain extent.
Memory GC
Doris BE will periodically obtain the physical memory of the process and the current available memory of the system from the system, and collect snapshots of all query, load, and compaction task MemTracker. When the BE process memory exceeds the limit or the system has insufficient available memory, Doris will release the cache and terminate some queries or loads to release memory. This process is executed regularly by a separate GC thread.
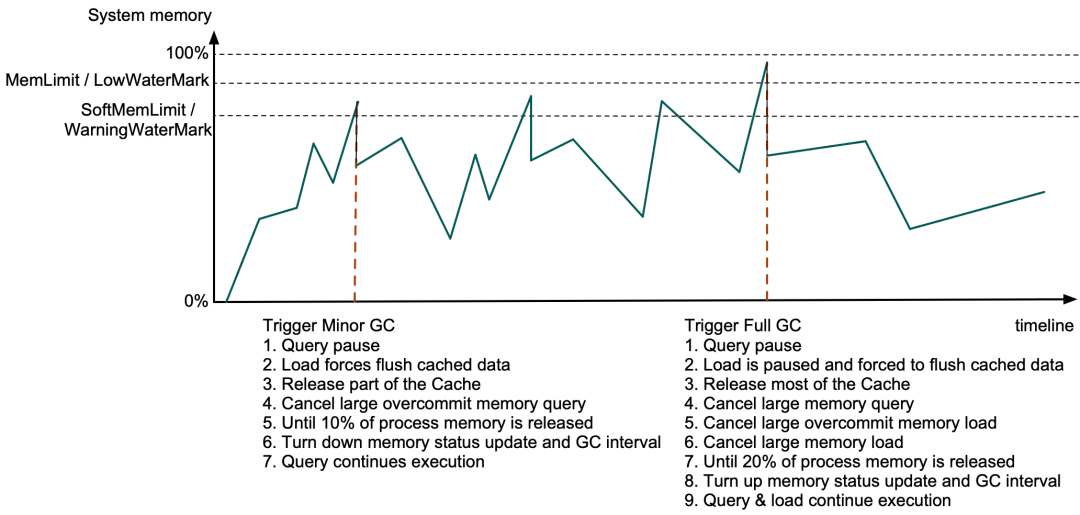
Minor GC is triggered when the Doris BE process memory exceeds SoftMemLimit (81% of the total system memory by default) or the remaining available system memory is lower than the Warning watermark (usually no more than 3.2GB). At this time, the query will be paused when the Allocator allocates memory, and the data in the forced cache will be load and some Data Page Cache and expired Segment Cache will be released. If the released memory is less than 10% of the process memory, if query memory over-issuance is enabled, the query with a large memory over-issuance ratio will be canceled until 10% of the process memory is released or no query can be canceled, and then the system memory status acquisition interval and GC interval will be lowered. Other queries will continue to execute after the remaining memory is found.
If the BE process memory exceeds MemLimit (90% of the total system memory by default) or the remaining available system memory is lower than the Low watermark (usually no more than 1.6GB), Full GC is triggered. In addition to the above operations, the load will also be paused when the cache data is forced to be flushed, and all Data Page Cache and most other caches will be released. If the released memory is less than 20%, it will start to search in the MemTracker list of all queries and loads according to a certain strategy, and cancel queries with large memory usage, loads with large memory over-issuance ratios, and loads with large memory usage in turn until 20% of the process memory is released. Then, the system memory status acquisition interval and GC interval are increased, and other queries and loads will continue to execute. The GC time is usually between hundreds of us and tens of ms.
Memory limit and watermark calculation method
-
Process memory limit MemLimit =
be.conf/mem_limit * PhysicalMemory, the default is 90% of the total system memory, for details, please refer to . -
Process memory soft limit SoftMemLimit =
be.conf/mem_limit * PhysicalMemory * be.conf/soft_mem_limit_frac, the default is 81% of the total system memory. -
System remaining available memory low water mark LowWaterMark =
be.conf/max_sys_mem_available_low_water_mark_bytes, the default is -1, then LowWaterMark =min(PhysicalMemory - MemLimit, PhysicalMemory * 0.05), on a machine with 64G memory, the value of LowWaterMark is slightly less than 3.2 GB (because the actual value ofPhysicalMemoryis often less than 64G). -
System remaining available memory warning water mark WarningWaterMark =
2 * LowWaterMark, on a machine with 64G memory,WarningWaterMarkdefaults to slightly less than 6.4 GB.
Calculation of remaining available memory in the system
When the available memory in the error message is less than the low water mark, it is also treated as a process memory overrun. The value of the available memory in the system comes from MemAvailable in /proc/meminfo. When MemAvailable is insufficient, continuing to request memory may return std::bad_alloc or cause BE process OOM. Because refreshing process memory statistics and BE memory GC have a certain lag, a small part of the memory buffer is reserved as the low water mark to avoid OOM as much as possible.
Among them, MemAvailable is the total amount of memory that can be provided to the user process without triggering swap as much as possible, given by the operating system based on factors such as the current free memory, buffer, cache, and memory fragmentation. A simple calculation formula is: MemAvailable = MemFree - LowWaterMark + (PageCache - min(PageCache / 2, LowWaterMark)), which is the same as the available value seen by cmd free. For details, please refer to:
why-is-memavailable-a-lot-less-than-memfreebufferscached
The default low water mark is 3.2G (1.6G before 2.1.5), which is calculated based on MemTotal, vm/min_free_kbytes, confg::mem_limit, config::max_sys_mem_available_low_water_mark_bytes, and avoids wasting too much memory. Among them, MemTotal is the total system memory, and the value is also taken from /proc/meminfo; vm/min_free_kbytes is the buffer reserved by the operating system for the memory GC process, and the value is usually between 0.4% and 5%. On some cloud servers, vm/min_free_kbytes may be 5%, which will make the system available memory appear to be less than the actual value; increasing config::max_sys_mem_available_low_water_mark_bytes will reserve more memory buffer for Full GC on machines with more than 64G memory, otherwise reducing it will make the best possible use of memory.
