Using Doris and Iceberg
As a new open data management architecture, the Data Lakehouse integrates the high performance and real-time capabilities of a data warehouse with the low cost and flexibility of a data lake, helping users more conveniently meet various data processing and analysis needs. It has been increasingly applied in enterprise big data systems.
In recent versions, Apache Doris has deepened its integration with data lakes and now offers a mature Data Lakehouse solution.
- Since version 0.15, Apache Doris has introduced Hive and Iceberg external tables, exploring the capabilities of combining with Apache Iceberg for data lakes.
- Starting from version 1.2, Apache Doris officially introduced the Multi-Catalog feature, enabling automatic metadata mapping and data access for various data sources, along with numerous performance optimizations for external data reading and query execution. It now fully supports building a high-speed and user-friendly Lakehouse architecture.
- In version 2.1, Apache Doris further strengthened its Data Lakehouse architecture, enhancing the reading and writing capabilities of mainstream data lake formats (Hudi, Iceberg, Paimon, etc.), introducing compatibility with multiple SQL dialects, and seamless migration from existing systems to Apache Doris. For data science and large-scale data reading scenarios, Doris integrated the Arrow Flight high-speed reading interface, achieving a 100x improvement in data transfer efficiency.
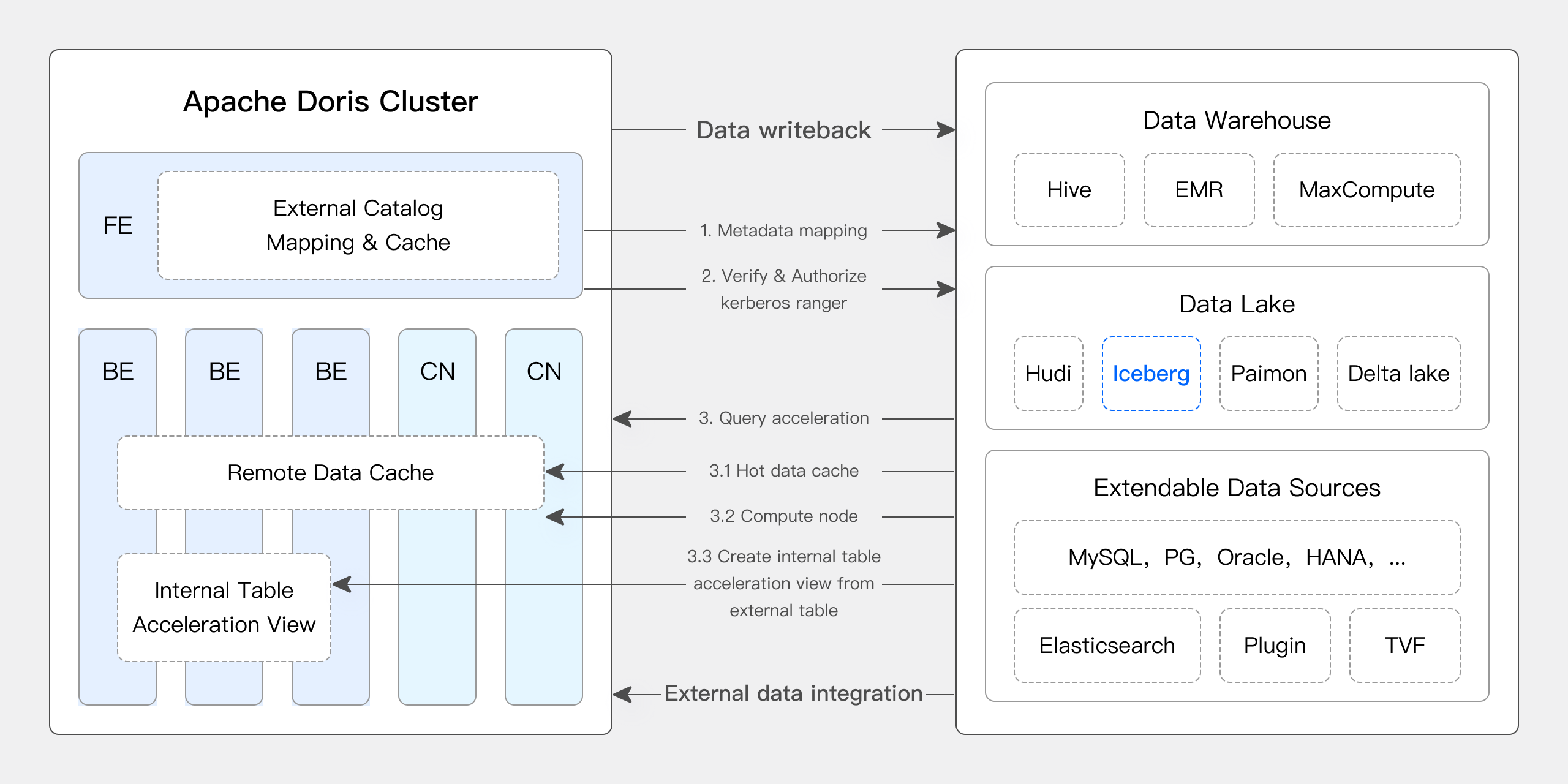
Apache Doris & Iceberg
Apache Iceberg is an open-source, high-performance, and highly reliable data lake table format that enables the analysis and management of massive-scale data. It supports various mainstream query engines, including Apache Doris, is compatible with HDFS and various object cloud storage, and features ACID compliance, schema evolution, advanced filtering, hidden partitioning, and partition layout evolution to ensure high-performance queries, data reliability, consistency, and flexibility with features like time travel and version rollback.
Apache Doris provides native support for several core features of Iceberg:
- Supports multiple Iceberg Catalog types such as Hive Metastore, Hadoop, REST, Glue, Google Dataproc Metastore, DLF, etc.
- Native support for Iceberg V1/V2 table formats and reading of Position Delete, Equality Delete files.
- Supports querying Iceberg table snapshot history through table functions.
- Supports Time Travel functionality.
- Native support for the Iceberg table engine. It allows Apache Doris to directly create, manage, and write data to Iceberg tables. It supports comprehensive partition Transform functions, providing capabilities like hidden partitioning and partition layout evolution.
Users can quickly build an efficient Data Lakehouse solution based on Apache Doris + Apache Iceberg to flexibly address various real-time data analysis and processing needs.
- Use the high-performance query engine of Doris to perform data analysis by associating Iceberg table data and other data sources, building a unified federated data analysis platform.
- Manage and build Iceberg tables directly through Doris, complete data cleaning, processing, and writing to Iceberg tables in Doris, building a unified data processing platform for data lakes.
- Share Doris data with other upstream and downstream systems for further processing through the Iceberg table engine, building a unified open data storage platform.
In the future, Apache Iceberg will serve as one of the native table engines for Apache Doris, providing more comprehensive analysis and management functions for lake-formatted data. Apache Doris will also gradually support more advanced features of Apache Iceberg, including Update/Delete/Merge, sorting during write-back, incremental data reading, metadata management, etc., to jointly build a unified, high-performance, real-time data lake platform.
For more information, please refer to Iceberg Catalog
User Guide
This document mainly explains how to quickly set up an Apache Doris + Apache Iceberg testing & demonstration environment in a Docker environment and demonstrate the usage of various functions.
All scripts and code mentioned in this document can be obtained from this address: https://github.com/apache/doris/tree/master/samples/datalake/iceberg_and_paimon
01 Environment Preparation
This document uses Docker Compose for deployment, with the following components and versions:
| Component | Version |
|---|---|
| Apache Doris | Default 2.1.5, can be modified |
| Apache Iceberg | 1.4.3 |
| MinIO | RELEASE.2024-04-29T09-56-05Z |
02 Environment Deployment
-
Start all components
bash ./start_all.sh -
After starting, you can use the following script to log in to the Doris command line:
-- login doris
bash ./start_doris_client.sh
03 Create Iceberg Table
After logging into the Doris command line, an Iceberg Catalog named Iceberg has already been created in the Doris cluster (can be viewed by SHOW CATALOGS/SHOW CREATE CATALOG iceberg). The following is the creation statement for this Catalog:
-- Already created
CREATE CATALOG `iceberg` PROPERTIES (
"type" = "iceberg",
"iceberg.catalog.type" = "rest",
"warehouse" = "s3://warehouse/",
"uri" = "http://rest:8181",
"s3.access_key" = "admin",
"s3.secret_key" = "password",
"s3.endpoint" = "http://minio:9000"
);
Create a database and an Iceberg table in the Iceberg Catalog:
mysql> SWITCH iceberg;
Query OK, 0 rows affected (0.00 sec)
mysql> CREATE DATABASE nyc;
Query OK, 0 rows affected (0.12 sec)
mysql> CREATE TABLE iceberg.nyc.taxis
(
vendor_id BIGINT,
trip_id BIGINT,
trip_distance FLOAT,
fare_amount DOUBLE,
store_and_fwd_flag STRING,
ts DATETIME
)
PARTITION BY LIST (vendor_id, DAY(ts)) ()
PROPERTIES (
"compression-codec" = "zstd",
"write-format" = "parquet"
);
Query OK, 0 rows affected (0.15 sec)
04 Data Insertion
Insert data into the Iceberg table:
mysql> INSERT INTO iceberg.nyc.taxis
VALUES
(1, 1000371, 1.8, 15.32, 'N', '2024-01-01 9:15:23'),
(2, 1000372, 2.5, 22.15, 'N', '2024-01-02 12:10:11'),
(2, 1000373, 0.9, 9.01, 'N', '2024-01-01 3:25:15'),
(1, 1000374, 8.4, 42.13, 'Y', '2024-01-03 7:12:33');
Query OK, 4 rows affected (1.61 sec)
{'status':'COMMITTED', 'txnId':'10085'}
Create an Iceberg table using CREATE TABLE AS SELECT:
mysql> CREATE TABLE iceberg.nyc.taxis2 AS SELECT * FROM iceberg.nyc.taxis;
Query OK, 6 rows affected (0.25 sec)
{'status':'COMMITTED', 'txnId':'10088'}
05 Data Query
-
Simple query
mysql> SELECT * FROM iceberg.nyc.taxis;
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| vendor_id | trip_id | trip_distance | fare_amount | store_and_fwd_flag | ts |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| 1 | 1000374 | 8.4 | 42.13 | Y | 2024-01-03 07:12:33.000000 |
| 1 | 1000371 | 1.8 | 15.32 | N | 2024-01-01 09:15:23.000000 |
| 2 | 1000373 | 0.9 | 9.01 | N | 2024-01-01 03:25:15.000000 |
| 2 | 1000372 | 2.5 | 22.15 | N | 2024-01-02 12:10:11.000000 |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
4 rows in set (0.37 sec)
mysql> SELECT * FROM iceberg.nyc.taxis2;
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| vendor_id | trip_id | trip_distance | fare_amount | store_and_fwd_flag | ts |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| 1 | 1000374 | 8.4 | 42.13 | Y | 2024-01-03 07:12:33.000000 |
| 1 | 1000371 | 1.8 | 15.32 | N | 2024-01-01 09:15:23.000000 |
| 2 | 1000373 | 0.9 | 9.01 | N | 2024-01-01 03:25:15.000000 |
| 2 | 1000372 | 2.5 | 22.15 | N | 2024-01-02 12:10:11.000000 |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
4 rows in set (0.35 sec) -
Partition pruning
mysql> SELECT * FROM iceberg.nyc.taxis where vendor_id = 2 and ts >= '2024-01-01' and ts < '2024-01-02';
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| vendor_id | trip_id | trip_distance | fare_amount | store_and_fwd_flag | ts |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| 2 | 1000373 | 0.9 | 9.01 | N | 2024-01-01 03:25:15.000000 |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
1 row in set (0.06 sec)
mysql> EXPLAIN VERBOSE SELECT * FROM iceberg.nyc.taxis where vendor_id = 2 and ts >= '2024-01-01' and ts < '2024-01-02';
....
| 0:VICEBERG_SCAN_NODE(71)
| table: taxis
| predicates: (ts[#5] < '2024-01-02 00:00:00'), (vendor_id[#0] = 2), (ts[#5] >= '2024-01-01 00:00:00')
| inputSplitNum=1, totalFileSize=3539, scanRanges=1
| partition=1/0
| backends:
| 10002
| s3://warehouse/wh/nyc/taxis/data/vendor_id=2/ts_day=2024-01-01/40e6ca404efa4a44-b888f23546d3a69c_5708e229-2f3d-4b68-a66b-44298a9d9815-0.zstd.parquet start: 0 length: 3539
| cardinality=6, numNodes=1
| pushdown agg=NONE
| icebergPredicatePushdown=
| ref(name="ts") < 1704153600000000
| ref(name="vendor_id") == 2
| ref(name="ts") >= 1704067200000000
....By examining the result of the
EXPLAIN VERBOSEstatement, it can be seen that the predicate conditionvendor_id = 2 and ts >= '2024-01-01' and ts < '2024-01-02'ultimately only hits one partition (partition=1/0).It can also be observed that because a partition Transform function
DAY(ts)was specified when creating the table, the original value in the data2024-01-01 03:25:15.000000will be transformed into the partition information in the file directoryts_day=2024-01-01.
06 Time Travel
Let's insert a few more rows of data:
INSERT INTO iceberg.nyc.taxis VALUES (1, 1000375, 8.8, 55.55, 'Y', '2024-01-01 8:10:22'), (3, 1000376, 7.4, 32.35, 'N', '2024-01-02 1:14:45');
Query OK, 2 rows affected (0.17 sec)
{'status':'COMMITTED', 'txnId':'10086'}
mysql> SELECT * FROM iceberg.nyc.taxis;
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| vendor_id | trip_id | trip_distance | fare_amount | store_and_fwd_flag | ts |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| 3 | 1000376 | 7.4 | 32.35 | N | 2024-01-02 01:14:45.000000 |
| 2 | 1000372 | 2.5 | 22.15 | N | 2024-01-02 12:10:11.000000 |
| 1 | 1000374 | 8.4 | 42.13 | Y | 2024-01-03 07:12:33.000000 |
| 1 | 1000371 | 1.8 | 15.32 | N | 2024-01-01 09:15:23.000000 |
| 1 | 1000375 | 8.8 | 55.55 | Y | 2024-01-01 08:10:22.000000 |
| 2 | 1000373 | 0.9 | 9.01 | N | 2024-01-01 03:25:15.000000 |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
6 rows in set (0.11 sec)
Use the iceberg_meta table function to query the snapshot information of the table:
mysql> select * from iceberg_meta("table" = "iceberg.nyc.taxis", "query_type" = "snapshots");
+---------------------+---------------------+---------------------+-----------+-----------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| committed_at | snapshot_id | parent_id | operation | manifest_list | summary |
+---------------------+---------------------+---------------------+-----------+-----------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| 2024-07-29 03:38:22 | 8483933166442433486 | -1 | append | s3://warehouse/wh/nyc/taxis/metadata/snap-8483933166442433486-1-5f7b7736-8022-4ba1-9db2-51ae7553be4d.avro | {"added-data-files":"4","added-records":"4","added-files-size":"14156","changed-partition-count":"4","total-records":"4","total-files-size":"14156","total-data-files":"4","total-delete-files":"0","total-position-deletes":"0","total-equality-deletes":"0"} |
| 2024-07-29 03:40:23 | 4726331391239920914 | 8483933166442433486 | append | s3://warehouse/wh/nyc/taxis/metadata/snap-4726331391239920914-1-6aa3d142-6c9c-4553-9c04-08ad4d49a4ea.avro | {"added-data-files":"2","added-records":"2","added-files-size":"7078","changed-partition-count":"2","total-records":"6","total-files-size":"21234","total-data-files":"6","total-delete-files":"0","total-position-deletes":"0","total-equality-deletes":"0"} |
+---------------------+---------------------+---------------------+-----------+-----------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
2 rows in set (0.07 sec)
Query a specified snapshot using the FOR VERSION AS OF statement:
mysql> SELECT * FROM iceberg.nyc.taxis FOR VERSION AS OF 8483933166442433486;
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| vendor_id | trip_id | trip_distance | fare_amount | store_and_fwd_flag | ts |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| 1 | 1000371 | 1.8 | 15.32 | N | 2024-01-01 09:15:23.000000 |
| 1 | 1000374 | 8.4 | 42.13 | Y | 2024-01-03 07:12:33.000000 |
| 2 | 1000372 | 2.5 | 22.15 | N | 2024-01-02 12:10:11.000000 |
| 2 | 1000373 | 0.9 | 9.01 | N | 2024-01-01 03:25:15.000000 |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
4 rows in set (0.05 sec)
mysql> SELECT * FROM iceberg.nyc.taxis FOR VERSION AS OF 4726331391239920914;
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| vendor_id | trip_id | trip_distance | fare_amount | store_and_fwd_flag | ts |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| 1 | 1000374 | 8.4 | 42.13 | Y | 2024-01-03 07:12:33.000000 |
| 1 | 1000375 | 8.8 | 55.55 | Y | 2024-01-01 08:10:22.000000 |
| 3 | 1000376 | 7.4 | 32.35 | N | 2024-01-02 01:14:45.000000 |
| 2 | 1000372 | 2.5 | 22.15 | N | 2024-01-02 12:10:11.000000 |
| 2 | 1000373 | 0.9 | 9.01 | N | 2024-01-01 03:25:15.000000 |
| 1 | 1000371 | 1.8 | 15.32 | N | 2024-01-01 09:15:23.000000 |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
6 rows in set (0.04 sec)
Query a specified snapshot using the FOR TIME AS OF statement:
mysql> SELECT * FROM iceberg.nyc.taxis FOR TIME AS OF "2024-07-29 03:38:23";
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| vendor_id | trip_id | trip_distance | fare_amount | store_and_fwd_flag | ts |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| 1 | 1000374 | 8.4 | 42.13 | Y | 2024-01-03 07:12:33.000000 |
| 1 | 1000371 | 1.8 | 15.32 | N | 2024-01-01 09:15:23.000000 |
| 2 | 1000372 | 2.5 | 22.15 | N | 2024-01-02 12:10:11.000000 |
| 2 | 1000373 | 0.9 | 9.01 | N | 2024-01-01 03:25:15.000000 |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
4 rows in set (0.04 sec)
mysql> SELECT * FROM iceberg.nyc.taxis FOR TIME AS OF "2024-07-29 03:40:22";
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| vendor_id | trip_id | trip_distance | fare_amount | store_and_fwd_flag | ts |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| 2 | 1000373 | 0.9 | 9.01 | N | 2024-01-01 03:25:15.000000 |
| 1 | 1000374 | 8.4 | 42.13 | Y | 2024-01-03 07:12:33.000000 |
| 2 | 1000372 | 2.5 | 22.15 | N | 2024-01-02 12:10:11.000000 |
| 1 | 1000371 | 1.8 | 15.32 | N | 2024-01-01 09:15:23.000000 |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
4 rows in set (0.05 sec)
07 Interacting with PyIceberg
Load an iceberg table:
from pyiceberg.catalog import load_catalog
catalog = load_catalog(
"iceberg",
**{
"warehouse" = "warehouse",
"uri" = "http://rest:8181",
"s3.access-key-id" = "admin",
"s3.secret-access-key" = "password",
"s3.endpoint" = "http://minio:9000"
},
)
table = catalog.load_table("nyc.taxis")
Read table as Arrow Table:
print(table.scan().to_arrow())
pyarrow.Table
vendor_id: int64
trip_id: int64
trip_distance: float
fare_amount: double
store_and_fwd_flag: large_string
ts: timestamp[us]
----
vendor_id: [[1],[1],[2],[2]]
trip_id: [[1000371],[1000374],[1000373],[1000372]]
trip_distance: [[1.8],[8.4],[0.9],[2.5]]
fare_amount: [[15.32],[42.13],[9.01],[22.15]]
store_and_fwd_flag: [["N"],["Y"],["N"],["N"]]
ts: [[2024-01-01 09:15:23.000000],[2024-01-03 07:12:33.000000],[2024-01-01 03:25:15.000000],[2024-01-02 12:10:11.000000]]
Read table as Pandas DataFrame:
print(table.scan().to_pandas())
vendor_id trip_id trip_distance fare_amount store_and_fwd_flag ts
0 1 1000371 1.8 15.32 N 2024-01-01 09:15:23
1 1 1000374 8.4 42.13 Y 2024-01-03 07:12:33
2 2 1000373 0.9 9.01 N 2024-01-01 03:25:15
3 2 1000372 2.5 22.15 N 2024-01-02 12:10:11
Read table as Polars DataFrame:
import polars as pl
print(pl.scan_iceberg(table).collect())
shape: (4, 6)
┌───────────┬─────────┬───────────────┬─────────────┬────────────────────┬─────────────────────┐
│ vendor_id ┆ trip_id ┆ trip_distance ┆ fare_amount ┆ store_and_fwd_flag ┆ ts │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ i64 ┆ f32 ┆ f64 ┆ str ┆ datetime[μs] │
╞═══════════╪═════════╪═══════════════╪═════════════╪════════════════════╪═════════════════════╡
│ 1 ┆ 1000371 ┆ 1.8 ┆ 15.32 ┆ N ┆ 2024-01-01 09:15:23 │
│ 1 ┆ 1000374 ┆ 8.4 ┆ 42.13 ┆ Y ┆ 2024-01-03 07:12:33 │
│ 2 ┆ 1000373 ┆ 0.9 ┆ 9.01 ┆ N ┆ 2024-01-01 03:25:15 │
│ 2 ┆ 1000372 ┆ 2.5 ┆ 22.15 ┆ N ┆ 2024-01-02 12:10:11 │
└───────────┴─────────┴───────────────┴─────────────┴────────────────────┴─────────────────────┘
Write iceberg table by PyIceberg, please see step
08 Appendix
Write iceberg table by PyIceberg
Load an iceberg table:
from pyiceberg.catalog import load_catalog
catalog = load_catalog(
"iceberg",
**{
"warehouse" = "warehouse",
"uri" = "http://rest:8181",
"s3.access-key-id" = "admin",
"s3.secret-access-key" = "password",
"s3.endpoint" = "http://minio:9000"
},
)
table = catalog.load_table("nyc.taxis")
Write table with Arrow Table :
import pyarrow as pa
df = pa.Table.from_pydict(
{
"vendor_id": pa.array([1, 2, 2, 1], pa.int64()),
"trip_id": pa.array([1000371, 1000372, 1000373, 1000374], pa.int64()),
"trip_distance": pa.array([1.8, 2.5, 0.9, 8.4], pa.float32()),
"fare_amount": pa.array([15.32, 22.15, 9.01, 42.13], pa.float64()),
"store_and_fwd_flag": pa.array(["N", "N", "N", "Y"], pa.string()),
"ts": pa.compute.strptime(
["2024-01-01 9:15:23", "2024-01-02 12:10:11", "2024-01-01 3:25:15", "2024-01-03 7:12:33"],
"%Y-%m-%d %H:%M:%S",
"us",
),
}
)
table.append(df)
Write table with Pandas DataFrame :
import pyarrow as pa
import pandas as pd
df = pd.DataFrame(
{
"vendor_id": pd.Series([1, 2, 2, 1]).astype("int64[pyarrow]"),
"trip_id": pd.Series([1000371, 1000372, 1000373, 1000374]).astype("int64[pyarrow]"),
"trip_distance": pd.Series([1.8, 2.5, 0.9, 8.4]).astype("float32[pyarrow]"),
"fare_amount": pd.Series([15.32, 22.15, 9.01, 42.13]).astype("float64[pyarrow]"),
"store_and_fwd_flag": pd.Series(["N", "N", "N", "Y"]).astype("string[pyarrow]"),
"ts": pd.Series(["2024-01-01 9:15:23", "2024-01-02 12:10:11", "2024-01-01 3:25:15", "2024-01-03 7:12:33"]).astype("timestamp[us][pyarrow]"),
}
)
table.append(pa.Table.from_pandas(df))
Write table with Polars DataFrame :
import polars as pl
df = pl.DataFrame(
{
"vendor_id": [1, 2, 2, 1],
"trip_id": [1000371, 1000372, 1000373, 1000374],
"trip_distance": [1.8, 2.5, 0.9, 8.4],
"fare_amount": [15.32, 22.15, 9.01, 42.13],
"store_and_fwd_flag": ["N", "N", "N", "Y"],
"ts": ["2024-01-01 9:15:23", "2024-01-02 12:10:11", "2024-01-01 3:25:15", "2024-01-03 7:12:33"],
},
{
"vendor_id": pl.Int64,
"trip_id": pl.Int64,
"trip_distance": pl.Float32,
"fare_amount": pl.Float64,
"store_and_fwd_flag": pl.String,
"ts": pl.String,
},
).with_columns(pl.col("ts").str.strptime(pl.Datetime, "%Y-%m-%d %H:%M:%S"))
table.append(df.to_arrow())
