Bucket Shuffle Join
Bucket Shuffle Join 是在 Doris 0.14 版本中正式加入的新功能。旨在为某些 Join 查询提供本地性优化,来减少数据在节点间的传输耗时,来加速查询。
它的设计、实现和效果可以参阅 ISSUE 4394。
名词解释
-
左表:Join 查询时,左边的表。进行 Probe 操作。可被 Join Reorder 调整顺序。
-
右表:Join 查询时,右边的表。进行 Build 操作。可被 Join Reorder 调整顺序。
原理
Doris 支持的常规分布式 Join 方式包括了 shuffle join 和 broadcast join。这两种 join 都会导致不小的网络开销:
举个例子,当前存在 A 表与 B 表的 Join 查询,它的 Join 方式为 HashJoin,不同 Join 类型的开销如下:
-
Broadcast Join: 如果根据数据分布,查询规划出 A 表有 3 个执行的 HashJoinNode,那么需要将 B 表全量的发送到 3 个 HashJoinNode,那么它的网络开销是
3B,它的内存开销也是3B。 -
Shuffle Join: Shuffle Join 会将 A,B 两张表的数据根据哈希计算分散到集群的节点之中,所以它的网络开销为
A + B,内存开销为B。
在 FE 之中保存了 Doris 每个表的数据分布信息,如果 join 语句命中了表的数据分布列,我们应该使用数据分布信息来减少 join 语句的网络与内存开销,这就是 Bucket Shuffle Join 的思路来源。
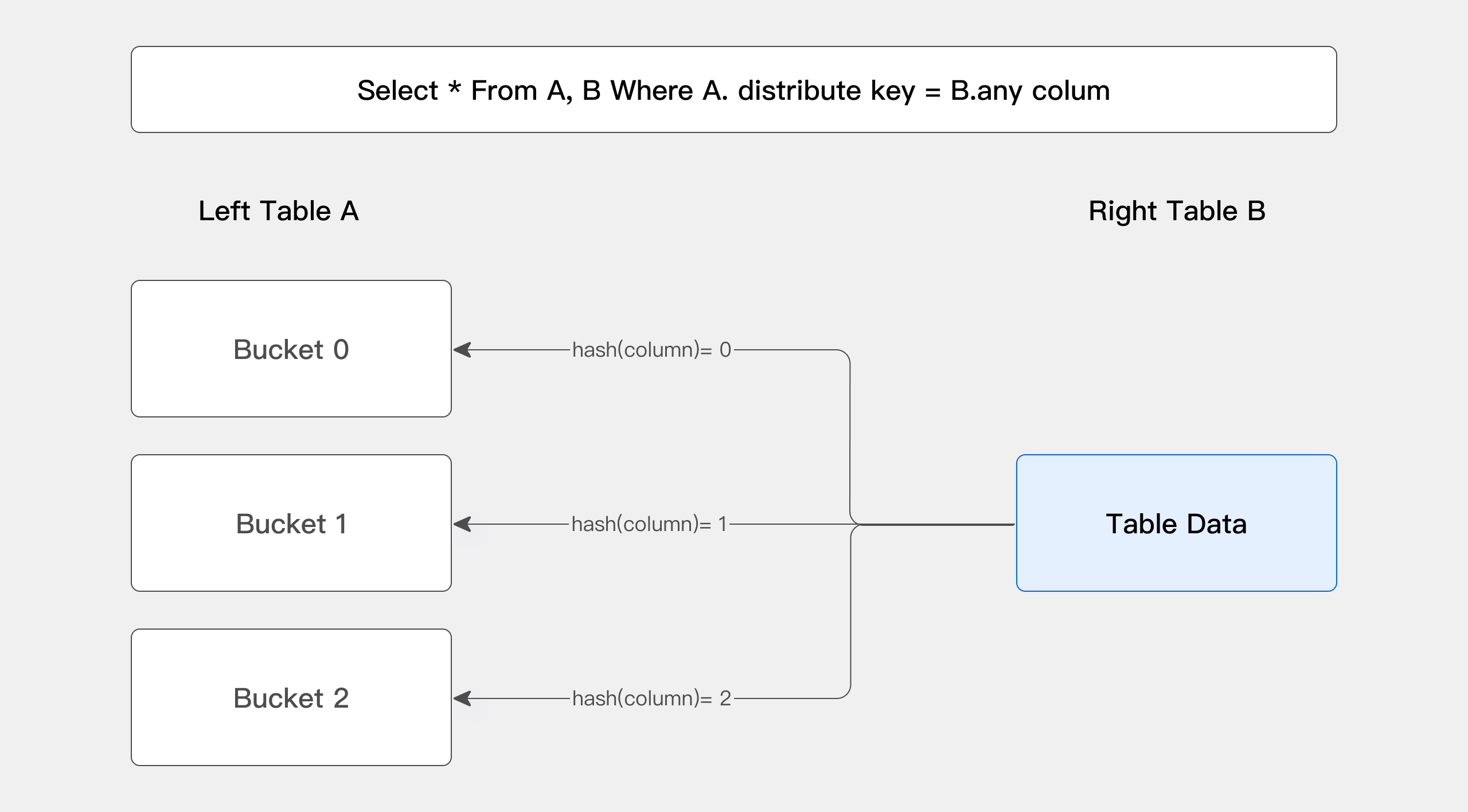
上面的图片展示了 Bucket Shuffle Join 的工作原理。SQL 语句为 A 表 join B 表,并且 join 的等值表达式命中了 A 的数据分布列。而 Bucket Shuffle Join 会根据 A 表的数据分布信息,将 B 表的数据发送到对应的 A 表的数据存储计算节点。Bucket Shuffle Join 开销如下:
-
网络开销:
B < min(3B, A + B) -
内存开销:
B <= min(3B, B)
可见,相比于 Broadcast Join 与 Shuffle Join,Bucket Shuffle Join 有着较为明显的性能优势。减少数据在节点间的传输耗时和 Join 时的内存开销。相对于 Doris 原有的 Join 方式,它有着下面的优点
-
首先,Bucket-Shuffle-Join 降低了网络与内存开销,使一些 Join 查询具有了更好的性能。尤其是当 FE 能够执行左表的分区裁剪与桶裁剪时。
-
其次,同时与 Colocate Join 不同,它对于表的数据分布方式并没有侵入性,这对于用户来说是透明的。对于表的数据分布没有强制性的要求,不容易导致数据倾斜的问题。
-
最后,它可以为 Join Reorder 提供更多可能的优化空间。
使用方式
设置 Session 变量
将 session 变量enable_bucket_shuffle_join设置为true,则 FE 在进行查询规划时就会默认将能够转换为 Bucket Shuffle Join 的查询自动规划为 Bucket Shuffle Join。
set enable_bucket_shuffle_join = true;
在 FE 进行分布式查询规划时,优先选择的顺序为 Colocate Join -> Bucket Shuffle Join -> Broadcast Join -> Shuffle Join。但是如果用户显式 hint 了 Join 的类型,如:
select * from test join [shuffle] baseall on test.k1 = baseall.k1;
则上述的选择优先顺序则不生效。
该 session 变量在 0.14 版本默认为true, 而 0.13 版本需要手动设置为true。
查看 Join 的类型
可以通过explain命令来查看 Join 是否为 Bucket Shuffle Join:
| 2:HASH JOIN |
| | join op: INNER JOIN (BUCKET_SHUFFLE) |
| | hash predicates: |
| | colocate: false, reason: table not in the same group |
| | equal join conjunct: `test`.`k1` = `baseall`.`k1`
在 Join 类型之中会指明使用的 Join 方式为:BUCKET_SHUFFLE。
Bucket Shuffle Join 的规划规则
在绝大多数场景之中,用户只需要默认打开 session 变量的开关就可以透明的使用这种 Join 方式带来的性能提升,但是如果了解 Bucket Shuffle Join 的规划规则,可以帮助我们利用它写出更加高效的 SQL。
-
Bucket Shuffle Join 只生效于 Join 条件为等值的场景,原因与 Colocate Join 类似,它们都依赖 hash 来计算确定的数据分布。
-
在等值 Join 条件之中包含两张表的分桶列,当左表的分桶列为等值的 Join 条件时,它有很大概率会被规划为 Bucket Shuffle Join。
-
由于不同的数据类型的 hash 值计算结果不同,所以 Bucket Shuffle Join 要求左表的分桶列的类型与右表等值 join 列的类型需要保持一致,否则无法进行对应的规划。
-
Bucket Shuffle Join 只作用于 Doris 原生的 OLAP 表,对于 ODBC,MySQL,ES 等外表,当其作为左表时是无法规划生效的。
-
对于分区表,由于每一个分区的数据分布规则可能不同,所以 Bucket Shuffle Join 只能保证左表为单分区时生效。所以在 SQL 执行之中,需要尽量使用
where条件使分区裁剪的策略能够生效。 -
假如左表为 Colocate 的表,那么它每个分区的数据分布规则是确定的,Bucket Shuffle Join 能在 Colocate 表上表现更好。
