Pipeline 执行引擎
Pipeline 执行引擎 是 Doris 在 2.0 版本加入的实验性功能。目标是为了替换当前 Doris 的火山模型的执行引擎,充分释放多核 CPU 的计算能力,并对 Doris 的查询线程的数目进行限制,解决 Doris 的执行线程膨胀的问题。
它的具体设计、实现和效果可以参阅 [DSIP-027](DSIP-027: Support Pipeline Exec Engine - DORIS - Apache Software Foundation)。
原理
当前的 Doris 的 SQL 执行引擎是基于传统的火山模型进行设计,在单机多核的场景下存在下面的一些问题:
-
无法充分利用多核计算能力,提升查询性能,多数场景下进行性能调优时需要手动设置并行度,在生产环境中几乎很难进行设定。
-
单机查询的每个 Instance 对应线程池的一个线程,这会带来额外的两个问题。
-
线程池一旦打满。Doris 的查询引擎会进入假性死锁,对后续的查询无法响应。同时有一定概率进入逻辑死锁的情况:比如所有的线程都在执行一个 Instance 的 Probe 任务。
-
阻塞的算子会占用线程资源,而阻塞的线程资源无法让渡给能够调度的 Instance,整体资源利用率上不去。
-
-
阻塞算子依赖操作系统的线程调度机制,线程切换开销较大(尤其在系统混布的场景中)
由此带来的一系列问题驱动 Doris 需要实现适应现代多核 CPU 的体系结构的执行引擎。
而如下图所示(引用自[Push versus pull-based loop fusion in query engines](jfp_1800010a (cambridge.org))),Pipeline 执行引擎基于多核 CPU 的特点,重新设计由数据驱动的执行引擎:
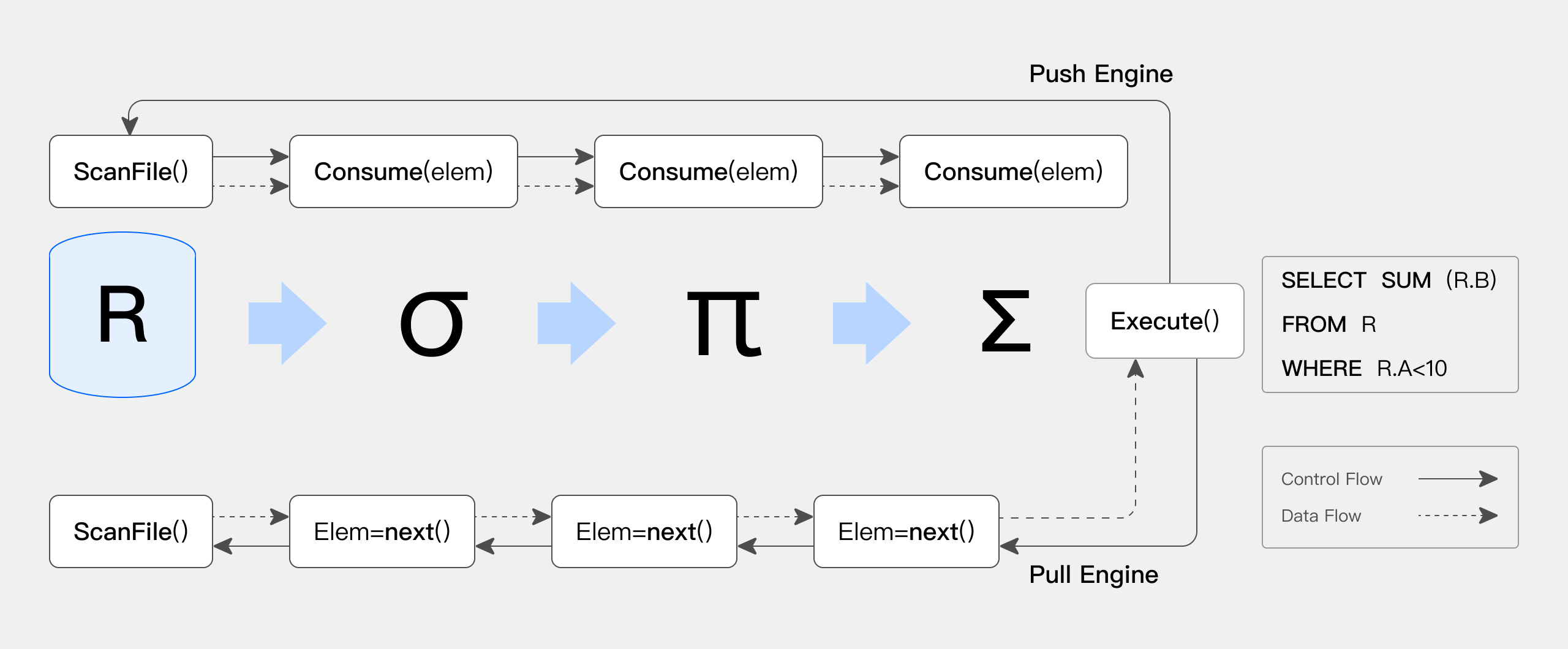
-
将传统 Pull 拉取的逻辑驱动的执行流程改造为 Push 模型的数据驱动的执行引擎
-
阻塞操作异步化,减少了线程切换,线程阻塞导致的执行开销,对于 CPU 的利用更为高效
-
控制了执行线程的数目,通过时间片的切换的控制,在混合负载的场景中,减少大查询对于小查询的资源挤占问题
从而提高了 CPU 在混合负载 SQL 上执行时的效率,提升了 SQL 查询的性能。
使用方式
查询
- enable_pipeline_engine
将 session 变量 enable_pipeline_engine 设置为 true,则 BE 在进行查询执行时将会使用 Pipeline 执行引擎。
set enable_pipeline_engine = true;
- parallel_pipeline_task_num
parallel_pipeline_task_num 代表了 SQL 查询进行查询并发的 Pipeline Task 数目。Doris 默认的配置为 0,此时 Pipeline Task 数目将自动设置为当前集群机器中最少的 CPU 数量的一半。用户也可以根据自己的实际情况进行调整。
set parallel_pipeline_task_num = 0;
可以通过设置 max_instance_num 来限制自动设置的并发数 (默认为 64)
导入
导入的引擎选择设置,详见导入文档。
