并行执行
Doris的并行执行模型是一种Pipeline 执行模型,主要参考了Hyper论文中Pipeline的实现方式,Pipeline 执行模型能够充分释放多核 CPU 的计算能力,并对 Doris 的查询线程的数目进行限制,解决 Doris 的执行线程膨胀的问题。它的具体设计、实现和效果可以参阅 [DSIP-027](DSIP-027: Support Pipeline Exec Engine - DORIS - Apache Software Foundation) 以及 [DSIP-035](DSIP-035: PipelineX Execution Engine - DORIS - Apache Software Foundation)。 Doris 3.0 之后,Pipeline 执行模型彻底替换了原有的火山模型,基于Pipeline 执行模型,Doris 实现了 Query、DDL、DML 语句的并行处理。
物理计划
为了更好的理解Pipeline 执行模型,首先需要介绍一下物理查询计划中两个重要的概念:PlanFragment和PlanNode。我们使用下面这条SQL 作为例子:
SELECT k1, SUM(v1) FROM A,B WHERE A.k2 = B.k2 GROUP BY k1 ORDER BY SUM(v1);
FE 首先会把它翻译成下面这种逻辑计划,计划中每个节点就是一个PlanNode,每种Node的具体含义,可以参考查看物理计划的介绍。
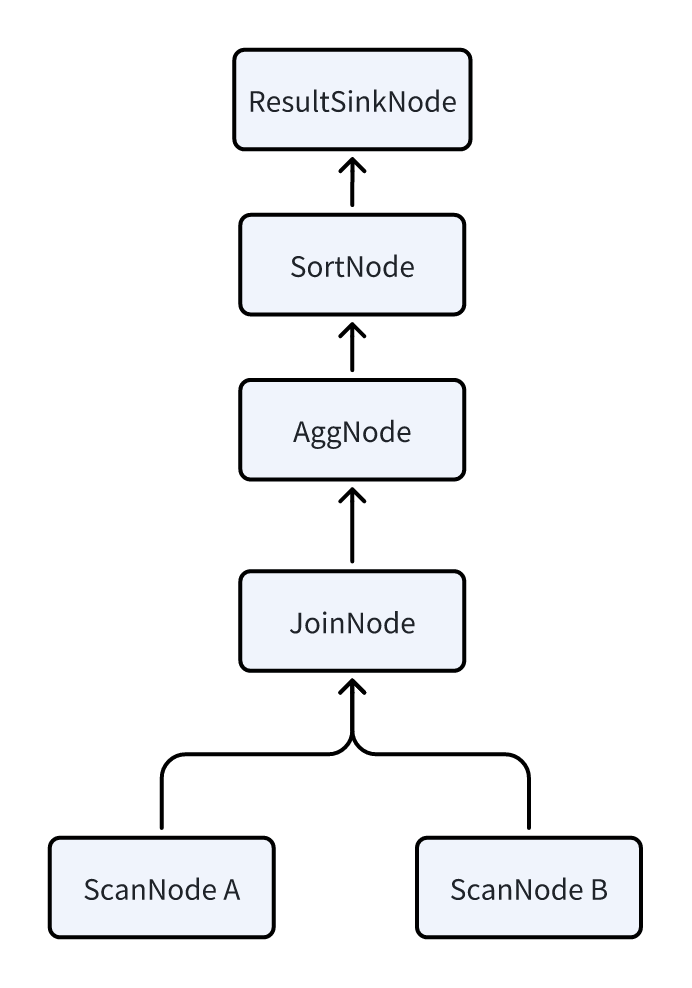
由于Doris 是一个MPP的架构,每个查询都会尽可能的让所有的BE 都参与进来并行执行,来降低查询的延时。所以还需要将上述逻辑计划拆分为一个物理计划,拆分物理计划基本上就是在逻辑计划中插入了DataSink和ExchangeNode,通过这两个Node完成了数据在多个BE 之间的Shuffle。拆分完成后,每个PlanFragment 相当于包含了一部分PlanNode,可以作为一个独立的任务发送给BE,每个BE 完成了PlanFragment内包含的PlanNode的计算后,通过DataSink和ExchangeNode 这两个算子把数据shuffle到其他BE上来进行接下来的计算。
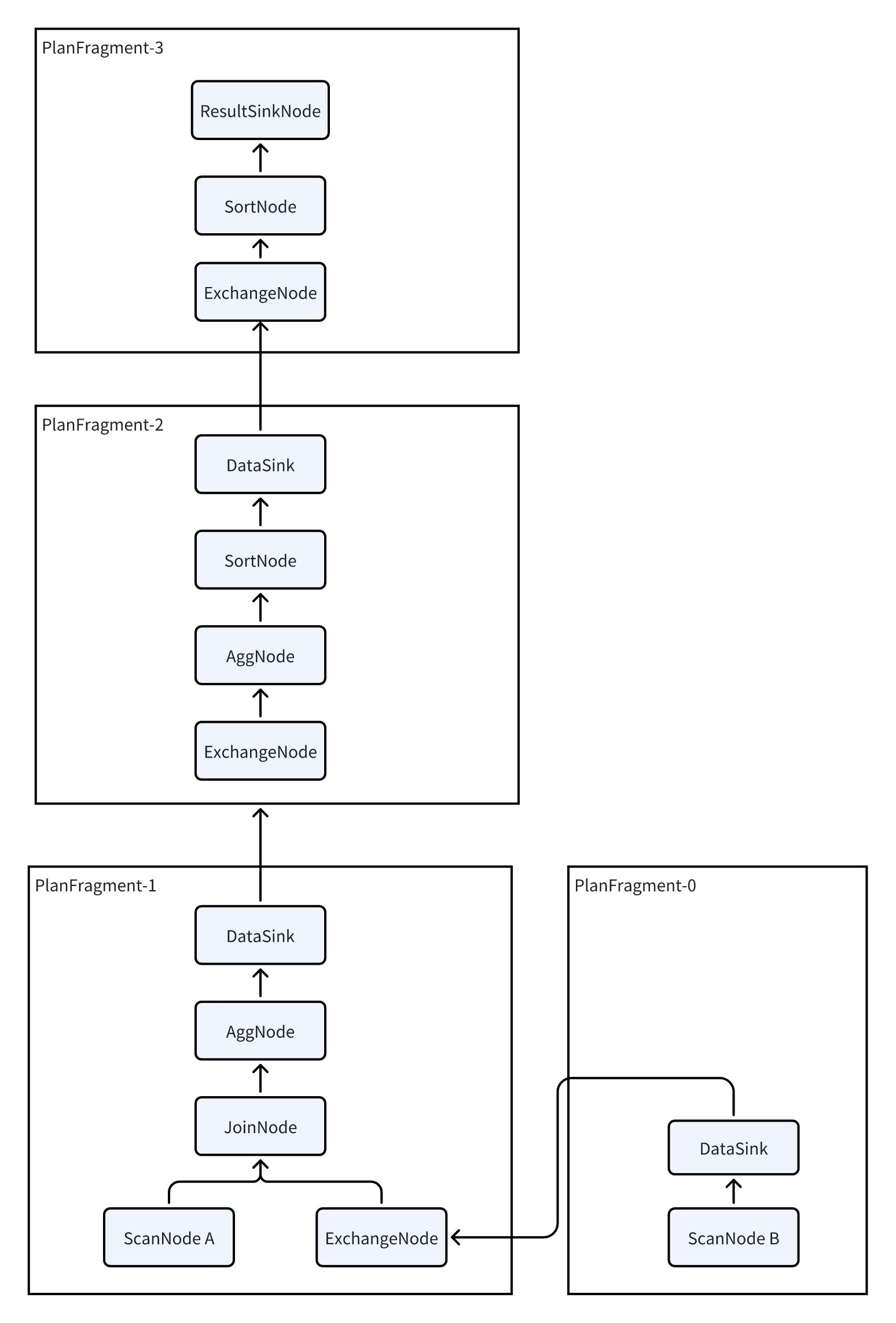
所以Doris的规划分为3层: PLAN:执行计划,一个SQL会被执行规划器翻译成一个执行计划,之后执行计划会提供给执行引擎执行。
FRAGMENT:由于DORIS是一个分布式执行引擎。一个完整的执行计划会被切分为多个单机的执行片段。一个FRAGMENT表是一个完整的单机执行片段。多个FRAGMENT组合在一起,构成一个完整的PLAN。
PLAN NODE:算子,是执行计划的最小单位。一个FRAGMENT由多个算子构成。每一个算子负责一个实际的执行逻辑,比如聚合,连接等
Pipeline 执行
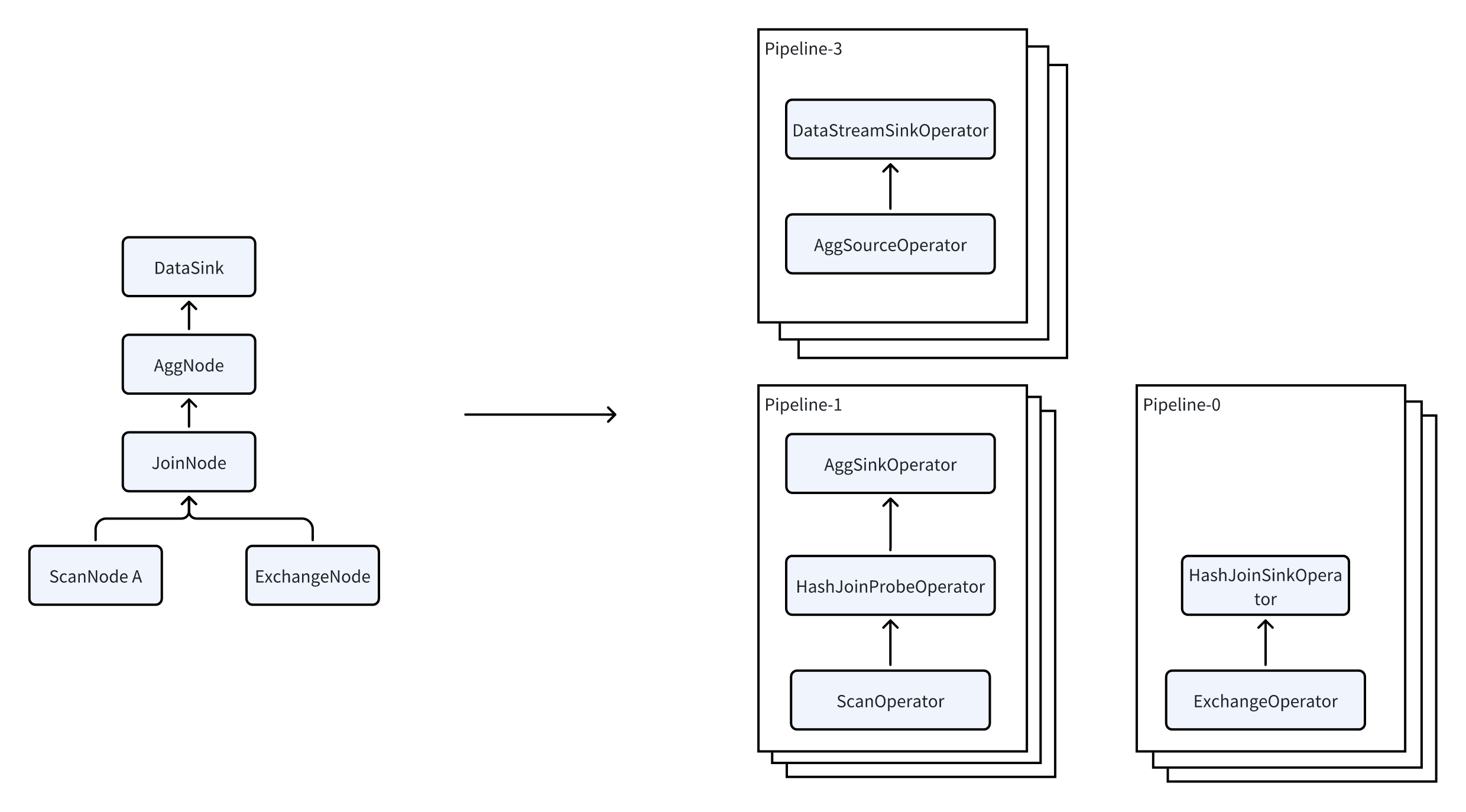
PlanFragment 是FE 发往BE 执行任务的最小单位。BE可能会收到同一个Query的多个不同的PlanFragment,每个PlanFragment都会被单独的处理。在收到PlanFragment 之后,BE会把PlanFragment 拆分为多个Pipeline,进而启动多个PipelineTask 来实现并行执行,提升查询效率。
Pipeline
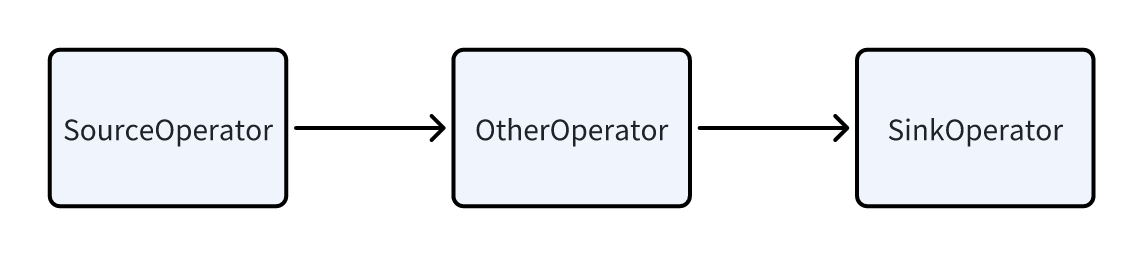
一个Pipeline 有一个SourceOperator 和 一个SinkOperator 以及中间的多个其他Operator组成。SourceOperator 代表从外部读取数据,可以是一个表(OlapTable),也可以是一个Buffer(Exchange)。SinkOperator 表示数据的输出,输出可以是通过网络shuffle到别的节点,比如DataStreamSinkOperator,也可以是输出到HashTable,比如Agg算子,JoinBuildHashTable等。
多个Pipeline 之间实际是有依赖关系的,以JoinNode为例,他实际被拆分到了2个Pipeline 里。其中Pipeline-0是读取Exchange的数据,来构建HashTable;Pipeline-1 是从表里读取数据,来进行Probe。这2个Pipeline 之间是有关联关系的,只有Pipeline-0运行完毕之后才能执行Pipeline-1。这两者之间的依赖关系,称为Dependency。当Pipeline-0 运行完毕后,会调用Dependency的set_ready 方法通知Pipeline-1 可执行。
PipelineTask
Pipeline 实际还是一个逻辑概念,他并不是一个可执行的实体。在有了Pipeline之后,需要进一步的把Pipeline 实例化为多个PipelineTask。将需要读取的数据分配给不同的PipelineTask 最终实现并行处理。同一个Pipeline的多个PipelineTask 之间的Operator 完全相同,他们的区别在于Operator的状态不一样,比如读取的数据不一样,构建出的HashTable 不一样,这些不一样的状态,我们称之为LocalState。 每个PipelineTask 最终都会被提交到一个线程池中作为独立的任务执行。在Dependency 这种触发机制下,可以更好的利用多核CPU,实现充分的并行。
Operator
在大多数时候,Pipeline 中的每个Operator 都对应了一个PlanNode,但是有一些特殊的算子除外:
- JoinNode,被拆分为JoinBuildOperator和JoinProbeOperator
- AggNode 被拆分为AggSinkOperator和AggSourceOperator
- SortNode 被拆分为SortSinkOperator 和 SortSourceOperator 基本原理是,对于一些breaking 算子(需要把所有的数据都收集齐之后才能运算的算子),把灌入数据的部分拆分为Sink,然后把从这个算子里获取数据的部分称为Source。
Scan 并行化
扫描数据是一个非常重的IO 操作,它需要从本地磁盘读取大量的数据(如果是数据湖的场景,就需要从HDFS或者S3中读取,延时更长),需要比较多的时间。所以我们在ScanOperator 中引入了并行扫描的技术,ScanOperator会动态的生成多个Scanner,每个Scanner 扫描100w-200w 行左右的数据,每个Scanner 在做数据扫描时,完成相应的数据解压、过滤等计算任务,然后把数据发送给一个DataQueue,供ScanOperator 读取。
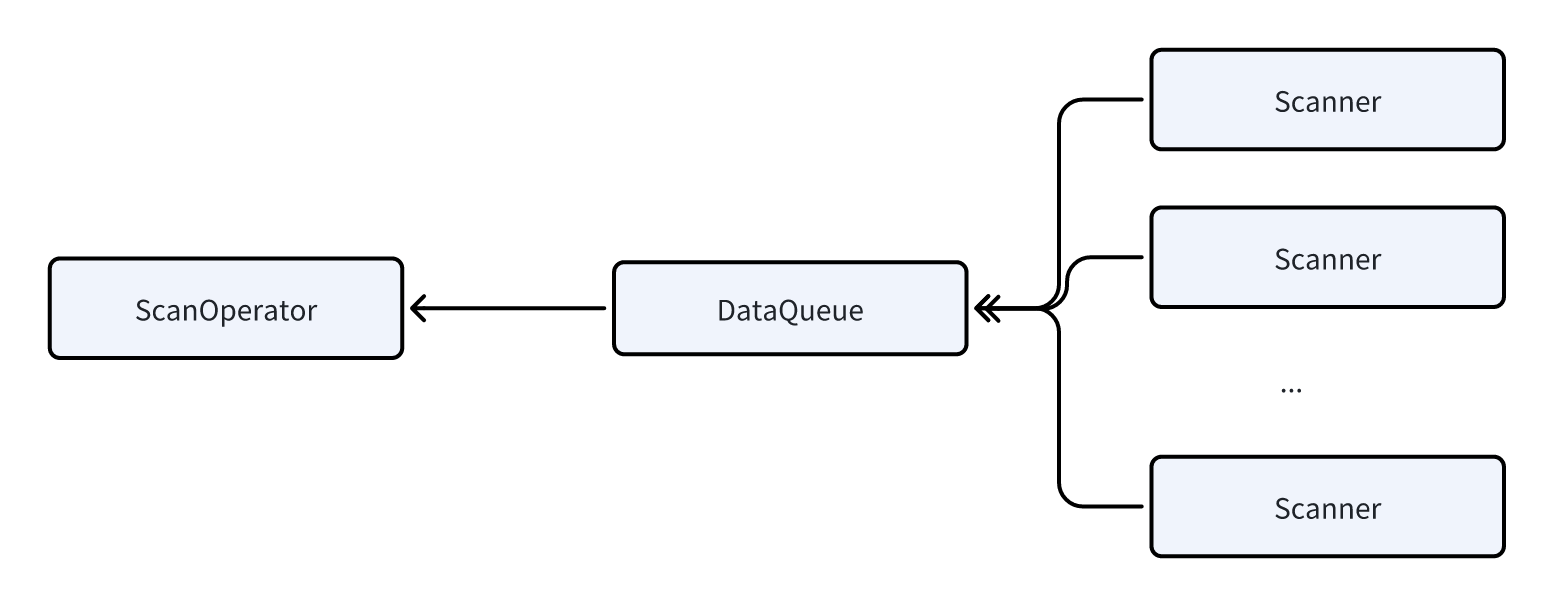
通过并行扫描的技术可以有效的避免由于分桶不合理或者数据倾斜导致某些ScanOperator 执行时间特别久,把整个查询的延时都拖慢的问题。
Local Shuffle
在Pipeline执行模型中,Local Exchange作为一个Pipeline Breaker出现,是在本地将数据重新分发至各个执行任务的技术。它把上游Pipeline输出的全部数据以某种方式(HASH / Round Robin)均匀分发到下游Pipeline的全部Task中。解决执行过程中的数据倾斜的问题,使执行模型不再受数据存储以及plan的限制。接下来我们举例来说明Local Exchange的工作逻辑。 我们用上述例子中的Pipeline-1为例子进一步阐述Local Exchange如何可以避免数据倾斜。
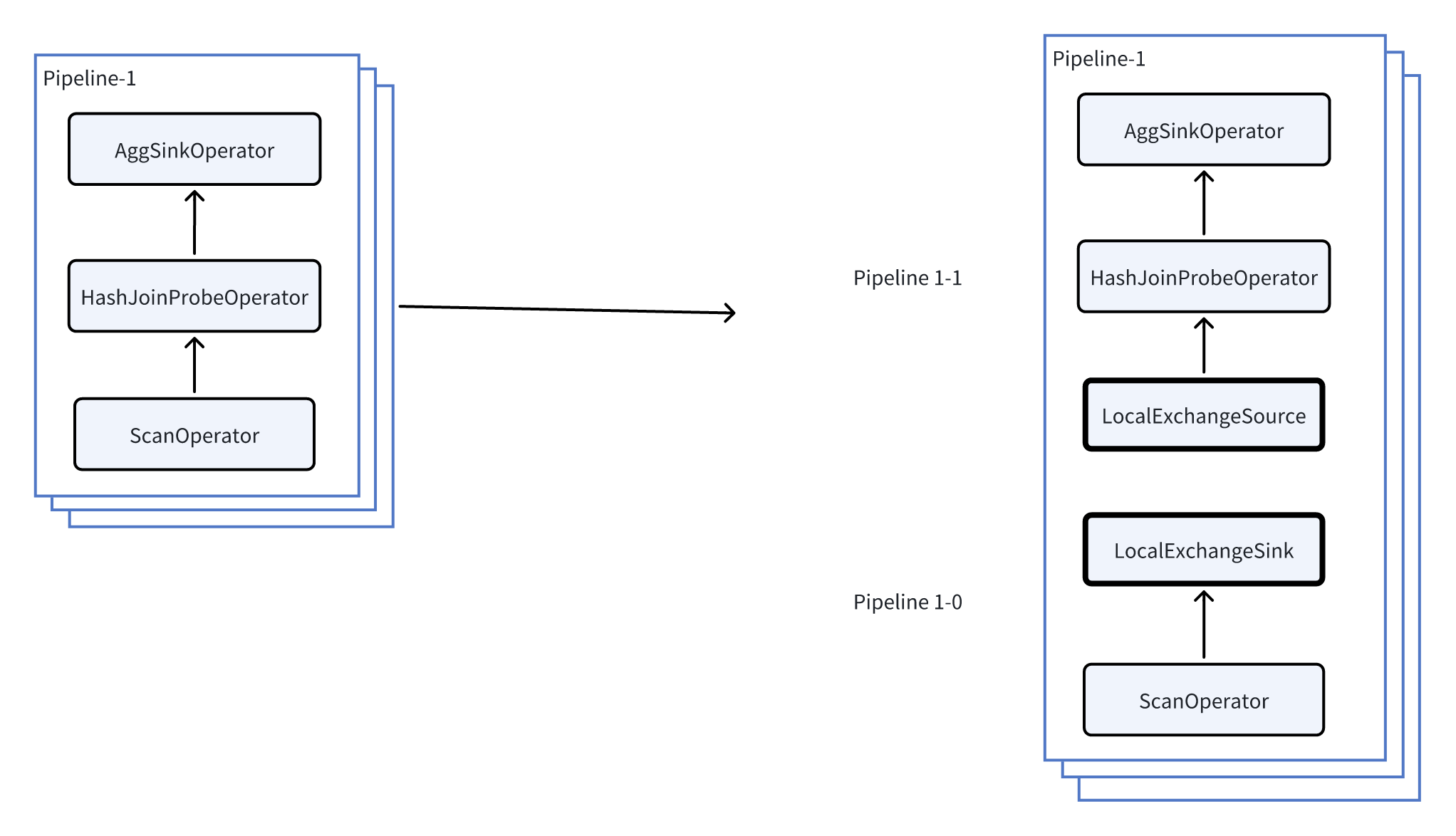
如上图所示,首先,通过在Pipeline 1中插入Local Exchange,我们把Pipeline 1进一步拆分成Pipeline 1-0和Pipeline 1-1。 此时,我们不妨假设当前并发等于3(每个Pipeline有3个task),每个task读取存储层的一个bucket,而3个bucket中数据行数分别是1,1,7。则插入Local Exchange前后的执行变化如下:
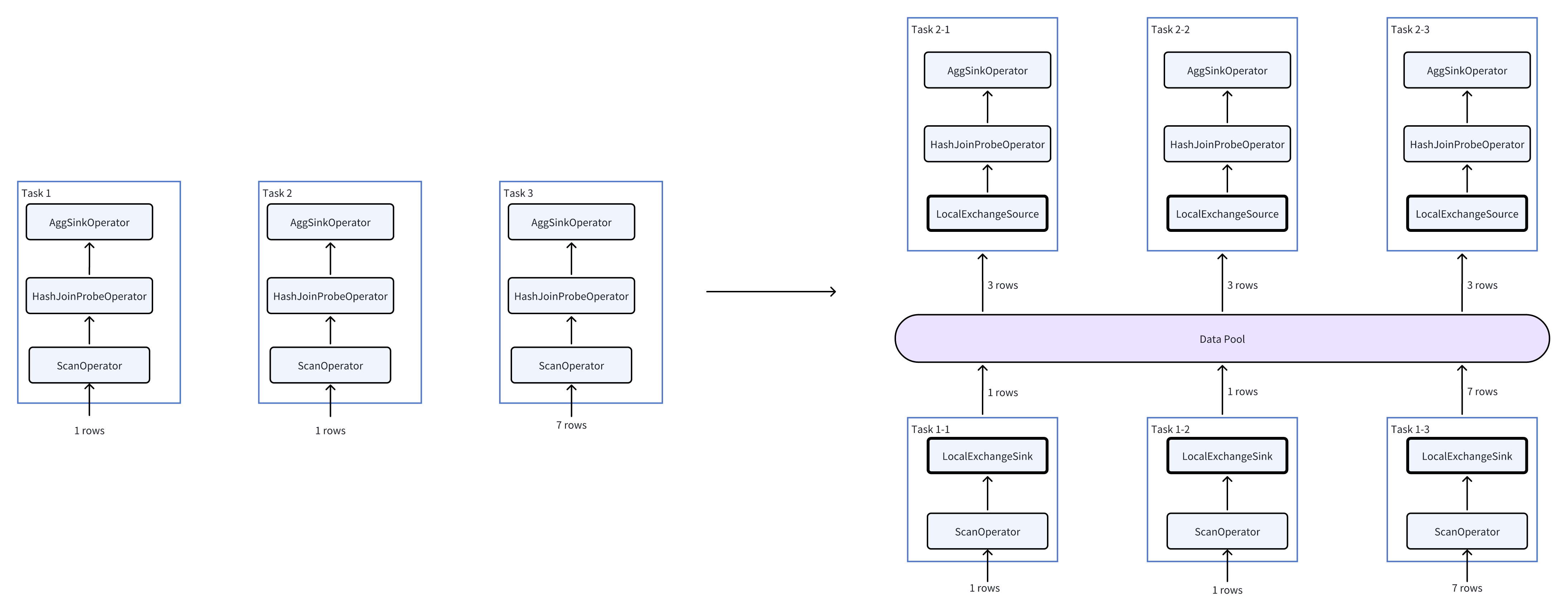
从图右可以看出,HashJoin和Agg算子需要处理的数据量从(1,1,7)变成了(3,3,3)从而避免了数据倾斜。 在Doris中,Local Exchange根据一系列规则来决定是否被规划,例如当查询耗时比较大的Join、聚合、窗口函数等算子需要被执行时,我们就需要使用Local Exchange来尽可能避免数据倾斜。
