Query Optimizers
In the current information technology landscape, query optimizers face multiple challenges: on the one hand, they need to handle increasingly complex query statements and diverse query scenarios from users; on the other hand, users have ever-stricter demands for query real-time performance, desiring instant access to required results. Furthermore, to address emerging new requirements, query optimizers must possess the capabilities of rapid iteration and flexible adaptation.
Based on this background, Doris embarked on the development of a brand-new query optimizer. Leveraging a modern optimizer architecture, this optimizer aims to more efficiently tackle query requests in the current Doris scenarios while providing exceptional scalability, laying a solid foundation for potentially more complex future demands.
Advantages of the Optimizer
Smarter
The optimizer clearly presents each optimization point of RBO (Rule-Based Optimization) and CBO (Cost-Based Optimization) in the form of rules. For each rule, the optimizer provides a set of patterns that describe the shape of the query plan, enabling precise matching of optimizable query plans. Therefore, the optimizer can better support more complex query statements such as nested multi-layer subqueries.
Meanwhile, the optimizer's CBO is based on the advanced Cascades framework, fully utilizing rich statistical data, data characteristic information, and a meticulously tuned cost model. This empowers the optimizer to handle complex queries like multi-table joins with ease and proficiency.
More Stable
All optimization rules of the optimizer are executed on the logical execution plan tree. After parsing the query syntax and semantics, the query is transformed into a tree structure. Compared to the old optimizer, the new optimizer's internal data structure is more reasonable and unified.
Taking subquery processing as an example, the new optimizer, based on its new data structure, avoids the separate handling of subqueries by numerous rules in the old optimizer, thereby reducing the likelihood of logical errors in optimization rules.
More Flexible
The optimizer's architecture is reasonably and modernly designed, making it very convenient to extend optimization rules and processing stages. Therefore, we can swiftly add new functionalities to meet evolving new requirements.
Principles of the Optimizer
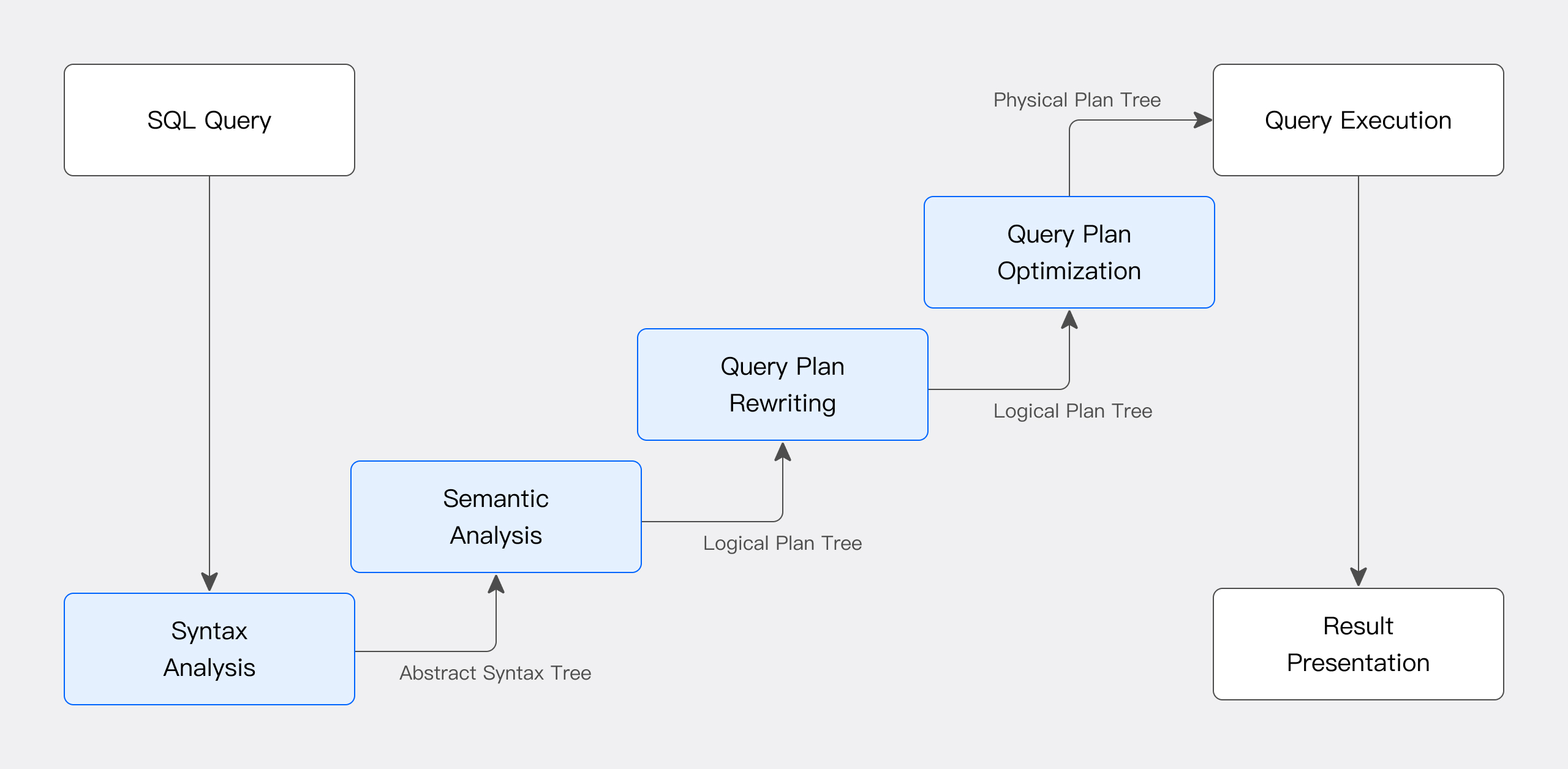
The execution process of the optimizer is divided into the following steps:
Syntax Analysis: The optimizer attempts to convert the SQL text into an Abstract Syntax Tree (AST). If the SQL text is valid, it proceeds to the next steps; if invalid, it reports an error and terminates execution.
Semantic Analysis: The optimizer performs semantic analysis on the elements in the AST. This step checks whether tables, columns, functions, etc., in the SQL query exist and whether their usage complies with syntax and semantic rules. If the semantics are valid, execution continues; if invalid, it reports an error and terminates execution.
Rewrite Query Plan (RBO): After syntax and semantic analysis, the optimizer performs Rule-Based Optimization (RBO). This step rewrites the query plan through a series of predefined rules to deterministically optimize execution speed. Common optimization techniques include column pruning, predicate pushdown, partition pruning, etc.
Optimize Query Plan (CBO): Finally, the optimizer performs Cost-Based Optimization (CBO). In this step, the optimizer enumerates equivalent plan sets in the search space and evaluates their execution costs. By comparing the execution costs of different plans, the optimizer selects the plan with the lowest cost as the final execution plan. This step aims to ensure that queries are executed in the most efficient manner, thereby providing optimal performance.
Session Variables
1. Set Planning Timeout enable_nereids_timeout_second
This variable is used to set the maximum allowed time for query planning. When the planning time exceeds this set value, query planning will be terminated, and an error message will be returned. During the process of planning query statements, the system obtains read locks for all tables involved in the SQL, primarily to maintain cluster stability and prevent excessive resource occupation and lock conflicts caused by excessively long planning times.
Default value: 30s
Applicable scenarios: When queries involve a large number of external tables or particularly complex query statements, this value can be appropriately increased to ensure that queries can proceed normally.
