Building lakehouse using Doris and Hudi
As a new open data management architecture, the Data Lakehouse integrates the high performance and real-time capabilities of data warehouses with the low cost and flexibility of data lakes, helping users more conveniently meet various data processing and analysis needs. It has been increasingly applied in enterprise big data systems.
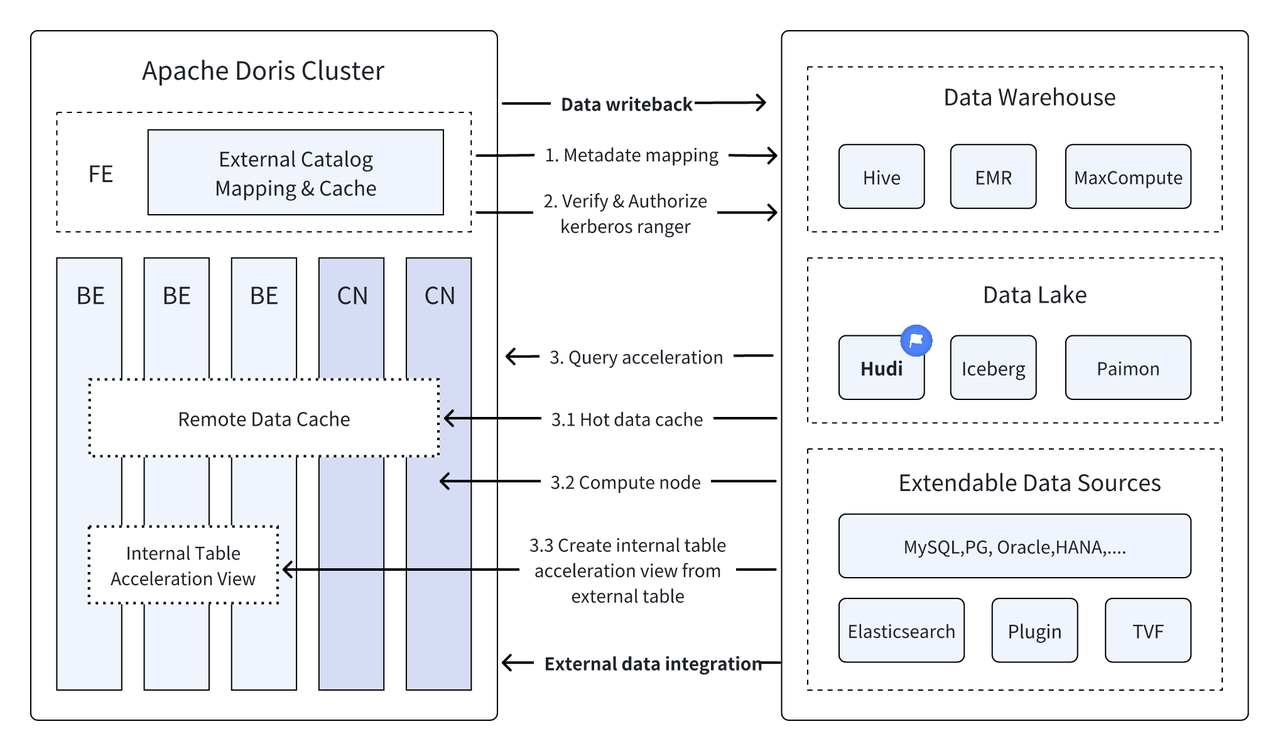
In recent versions, Apache Doris has deepened its integration with data lakes and has evolved a mature Data Lakehouse solution.
- Since version 0.15, Apache Doris has introduced Hive and Iceberg external tables, exploring the capabilities of combining with Apache Iceberg for data lakes.
- Starting from version 1.2, Apache Doris officially introduced the Multi-Catalog feature, enabling automatic metadata mapping and data access for various data sources, along with numerous performance optimizations for external data reading and query execution. It now fully possesses the ability to build a high-speed and user-friendly Lakehouse architecture.
- In version 2.1, Apache Doris' Data Lakehouse architecture was significantly enhanced, improving the reading and writing capabilities of mainstream data lake formats (Hudi, Iceberg, Paimon, etc.), introducing compatibility with multiple SQL dialects, and seamless migration from existing systems to Apache Doris. For data science and large-scale data reading scenarios, Doris integrated the Arrow Flight high-speed reading interface, achieving a 100-fold increase in data transfer efficiency.
Apache Doris & Hudi
Apache Hudi is currently one of the most popular open data lake formats and a transactional data lake management platform, supporting various mainstream query engines including Apache Doris.
Apache Doris has also enhanced its ability to read Apache Hudi data tables:
- Supports Copy on Write Table: Snapshot Query
- Supports Merge on Read Table: Snapshot Queries, Read Optimized Queries
- Supports Time Travel
- Supports Incremental Read
With Apache Doris' high-performance query execution and Apache Hudi's real-time data management capabilities, efficient, flexible, and cost-effective data querying and analysis can be achieved. It also provides robust data lineage, auditing, and incremental processing functionalities. The combination of Apache Doris and Apache Hudi has been validated and promoted in real business scenarios by multiple community users:
- Real-time data analysis and processing: Common scenarios such as real-time data updates and query analysis in industries like finance, advertising, and e-commerce require real-time data processing. Hudi enables real-time data updates and management while ensuring data consistency and reliability. Doris efficiently handles large-scale data query requests in real-time, meeting the demands of real-time data analysis and processing effectively when combined.
- Data lineage and auditing: For industries with high requirements for data security and accuracy like finance and healthcare, data lineage and auditing are crucial functionalities. Hudi offers Time Travel functionality for viewing historical data states, combined with Apache Doris' efficient querying capabilities, enabling quick analysis of data at any point in time for precise lineage and auditing.
- Incremental data reading and analysis: Large-scale data analysis often faces challenges of large data volumes and frequent updates. Hudi supports incremental data reading, allowing users to process only the changed data without full data updates. Additionally, Apache Doris' Incremental Read feature enhances this process, significantly improving data processing and analysis efficiency.
- Cross-data source federated queries: Many enterprises have complex data sources stored in different databases. Doris' Multi-Catalog feature supports automatic mapping and synchronization of various data sources, enabling federated queries across data sources. This greatly shortens the data flow path and enhances work efficiency for enterprises needing to retrieve and integrate data from multiple sources for analysis.
This article will introduce readers to how to quickly set up a test and demonstration environment for Apache Doris + Apache Hudi in a Docker environment, and demonstrate various operations to help readers get started quickly.
For more information, please refer to Hudi Catalog
User Guide
All scripts and code mentioned in this article can be obtained from this address: https://github.com/apache/doris/tree/master/samples/datalake/hudi
01 Environment Preparation
This article uses Docker Compose for deployment, with the following components and versions:
| Component | Version |
|---|---|
| Apache Doris | Default 2.1.4, can be modified |
| Apache Hudi | 0.14 |
| Apache Spark | 3.4.2 |
| Apache Hive | 2.1.3 |
| MinIO | 2022-05-26T05-48-41Z |
02 Environment Deployment
Create a Docker network
sudo docker network create -d bridge hudi-netStart all components
sudo ./start-hudi-compose.shNote: Before starting, you can modify the
DORIS_PACKAGEandDORIS_DOWNLOAD_URLinstart-hudi-compose.shto the desired Doris version. It is recommended to use version 2.1.4 or higher.After starting, you can use the following script to log in to Spark command line or Doris command line:
-- Doris
sudo ./login-spark.sh
-- Spark
sudo ./login-doris.sh
03 Data Preparation
Next, generate Hudi data through Spark. As shown in the code below, there is already a Hive table named customer in the cluster. You can create a Hudi table using this Hive table:
-- ./login-spark.sh
spark-sql> use default;
-- create a COW table
spark-sql> CREATE TABLE customer_cow
USING hudi
TBLPROPERTIES (
type = 'cow',
primaryKey = 'c_custkey',
preCombineField = 'c_name'
)
PARTITIONED BY (c_nationkey)
AS SELECT * FROM customer;
-- create a MOR table
spark-sql> CREATE TABLE customer_mor
USING hudi
TBLPROPERTIES (
type = 'mor',
primaryKey = 'c_custkey',
preCombineField = 'c_name'
)
PARTITIONED BY (c_nationkey)
AS SELECT * FROM customer;
04 Data Query
As shown below, a Catalog named hudi has been created in the Doris cluster (can be viewed using SHOW CATALOGS). The following is the creation statement for this Catalog:
-- Already created, no need to execute again
CREATE CATALOG `hive` PROPERTIES (
"type"="hms",
'hive.metastore.uris' = 'thrift://hive-metastore:9083',
"s3.access_key" = "minio",
"s3.secret_key" = "minio123",
"s3.endpoint" = "http://minio:9000",
"s3.region" = "us-east-1",
"use_path_style" = "true"
);
Manually refresh this Catalog to synchronize the created Hudi table:
-- ./login-doris.sh
doris> REFRESH CATALOG hive;Operations on data in Hudi using Spark are immediately visible in Doris without the need to refresh the Catalog. We insert a row of data into both COW and MOR tables using Spark:
spark-sql> insert into customer_cow values (100, "Customer#000000100", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 25);
spark-sql> insert into customer_mor values (100, "Customer#000000100", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 25);Through Doris, you can directly query the latest inserted data:
doris> use hive.default;
doris> select * from customer_cow where c_custkey = 100;
doris> select * from customer_mor where c_custkey = 100;Insert data with c_custkey=32 that already exists using Spark, thus overwriting the existing data:
spark-sql> insert into customer_cow values (32, "Customer#000000032_update", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 15);
spark-sql> insert into customer_mor values (32, "Customer#000000032_update", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 15);With Doris, you can query the updated data:
doris> select * from customer_cow where c_custkey = 32;
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
doris> select * from customer_mor where c_custkey = 32;
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
05 Incremental Read
Incremental Read is one of the features provided by Hudi. With Incremental Read, users can obtain incremental data within a specified time range, enabling incremental processing of data. In this regard, Doris can query the changed data after inserting c_custkey=100. As shown below, we inserted a data with c_custkey=32:
doris> select * from customer_cow@incr('beginTime'='20240603015018572');
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
spark-sql> select * from hudi_table_changes('customer_cow', 'latest_state', '20240603015018572');
doris> select * from customer_mor@incr('beginTime'='20240603015058442');
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
spark-sql> select * from hudi_table_changes('customer_mor', 'latest_state', '20240603015058442');
06 TimeTravel
Doris supports querying specific snapshot versions of Hudi data, thereby enabling Time Travel functionality for data. First, you can query the commit history of two Hudi tables using Spark:
spark-sql> call show_commits(table => 'customer_cow', limit => 10);
20240603033556094 20240603033558249 commit 448833 0 1 1 183 0 0
20240603015444737 20240603015446588 commit 450238 0 1 1 202 1 0
20240603015018572 20240603015020503 commit 436692 1 0 1 1 0 0
20240603013858098 20240603013907467 commit 44902033 100 0 25 18751 0 0
spark-sql> call show_commits(table => 'customer_mor', limit => 10);
20240603033745977 20240603033748021 deltacommit 1240 0 1 1 0 0 0
20240603015451860 20240603015453539 deltacommit 1434 0 1 1 1 1 0
20240603015058442 20240603015100120 deltacommit 436691 1 0 1 1 0 0
20240603013918515 20240603013922961 deltacommit 44904040 100 0 25 18751 0 0
Next, using Doris, you can execute c_custkey=32 to query the data snapshot before the data insertion. As shown below, the data with c_custkey=32 has not been updated yet:
Note: Time Travel syntax is currently not supported by the new optimizer. You need to first execute
set enable_nereids_planner=false;to disable the new optimizer. This issue will be fixed in future versions.
doris> select * from customer_cow for time as of '20240603015018572' where c_custkey = 32 or c_custkey = 100;
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tlp2iQ6ZcO3J | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious requests across the e | 15 |
| 100 | Customer#000000100 | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 25 |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
-- compare with spark-sql
spark-sql> select * from customer_mor timestamp as of '20240603015018572' where c_custkey = 32 or c_custkey = 100;
doris> select * from customer_mor for time as of '20240603015058442' where c_custkey = 32 or c_custkey = 100;
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| 100 | Customer#000000100 | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 25 |
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tlp2iQ6ZcO3J | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious requests across the e | 15 |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
spark-sql> select * from customer_mor timestamp as of '20240603015058442' where c_custkey = 32 or c_custkey = 100;
Query Optimization
Data in Apache Hudi can be roughly divided into two categories - baseline data and incremental data. Baseline data is typically merged Parquet files, while incremental data refers to data increments generated by INSERT, UPDATE, or DELETE operations. Baseline data can be read directly, while incremental data needs to be read through Merge on Read.
For querying Hudi COW tables or Read Optimized queries on MOR tables, the data belongs to baseline data and can be directly read using Doris' native Parquet Reader, providing fast query responses. For incremental data, Doris needs to access Hudi's Java SDK through JNI calls. To achieve optimal query performance, Apache Doris divides the data in a query into baseline and incremental data parts and reads them using the aforementioned methods.
To verify this optimization approach, we can use the EXPLAIN statement to see how many baseline and incremental data are present in a query example below. For a COW table, all 101 data shards are baseline data (hudiNativeReadSplits=101/101), so the COW table can be entirely read directly using Doris' Parquet Reader, resulting in the best query performance. For a ROW table, most data shards are baseline data (hudiNativeReadSplits=100/101), with one shard being incremental data, which also provides good query performance.
-- COW table is read natively
doris> explain select * from customer_cow where c_custkey = 32;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_cow |
| predicates: (c_custkey[#5] = 32) |
| inputSplitNum=101, totalFileSize=45338886, scanRanges=101 |
| partition=26/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=101/101 |
-- MOR table: because only the base file contains `c_custkey = 32` that is updated, 100 splits are read natively, while the split with log file is read by JNI.
doris> explain select * from customer_mor where c_custkey = 32;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_mor |
| predicates: (c_custkey[#5] = 32) |
| inputSplitNum=101, totalFileSize=45340731, scanRanges=101 |
| partition=26/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=100/101 |
You can further observe the changes in Hudi baseline data and incremental data by performing some deletion operations using Spark:
-- Use delete statement to see more differences
spark-sql> delete from customer_cow where c_custkey = 64;
doris> explain select * from customer_cow where c_custkey = 64;
spark-sql> delete from customer_mor where c_custkey = 64;
doris> explain select * from customer_mor where c_custkey = 64;
Additionally, you can reduce the data volume further by using partition conditions for partition pruning to improve query speed. In the example below, partition pruning is done using the partition condition c_nationkey=15, allowing the query request to access data from only one partition (partition=1/26).
-- customer_xxx is partitioned by c_nationkey, we can use the partition column to prune data
doris> explain select * from customer_mor where c_custkey = 64 and c_nationkey = 15;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_mor |
| predicates: (c_custkey[#5] = 64), (c_nationkey[#12] = 15) |
| inputSplitNum=4, totalFileSize=1798186, scanRanges=4 |
| partition=1/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=3/4 |
