Stream Load
Stream Load 支持通过 HTTP 协议将本地文件或数据流导入到 Doris 中。Stream Load 是一个同步导入方式,执行导入后返回导入结果,可以通过请求的返回判断导入是否成功。一般来说,可以使用 Stream Load 导入 10GB 以下的文件,如果文件过大,建议将文件进行切分后使用 Stream Load 进行导入。Stream Load 可以保证一批导入任务的原子性,要么全部导入成功,要么全部导入失败。
提示
相比于直接使用 curl 的单并发导入,更推荐使用 专用导入工具 Doris Streamloader 该工具是一款用于将数据导入 Doris 数据库的专用客户端工具,可以提供多并发导入的功能,降低大数据量导入的耗时。拥有以下功能:
- 并发导入,实现 Stream Load 的多并发导入。可以通过
workers值设置并发数。 - 多文件导入,一次导入可以同时导入多个文件及目录,支持设置通配符以及会自动递归获取文件夹下的所有文件。
- 断点续传,在导入过程中可能出现部分失败的情况,支持在失败点处进行继续传输。
- 自动重传,在导入出现失败的情况后,无需手动重传,工具会自动重传默认的次数,如果仍然不成功,打印出手动重传的命令。
点击 Doris Streamloader 文档 了解使用方法与实践详情。
使用场景
支持格式
Stream Load 支持导入 CSV、JSON、Parquet 与 ORC 格式的数据。
使用限制
在导入 CSV 文件时,需要明确区分空值(null)与空字符串:
空值(null)需要用
\N表示,a,\N,b数据表示中间列是一个空值(null)空字符串直接将数据置空,a, ,b 数据表示中间列是一个空字符串
基本原理
在使用 Stream Load 时,需要通过 HTTP 协议发起导入作业给 FE 节点,FE 会以轮询方式,重定向(redirect)请求给一个 BE 节点以达到负载均衡的效果。也可以直接发送 HTTP 请求作业给指定的 BE 节点。在 Stream Load 中,Doris 会选定一个节点做为 Coordinator 节点。Coordinator 节点负责接受数据并分发数据到其他节点上。
下图展示了 Stream Load 的主要流程:
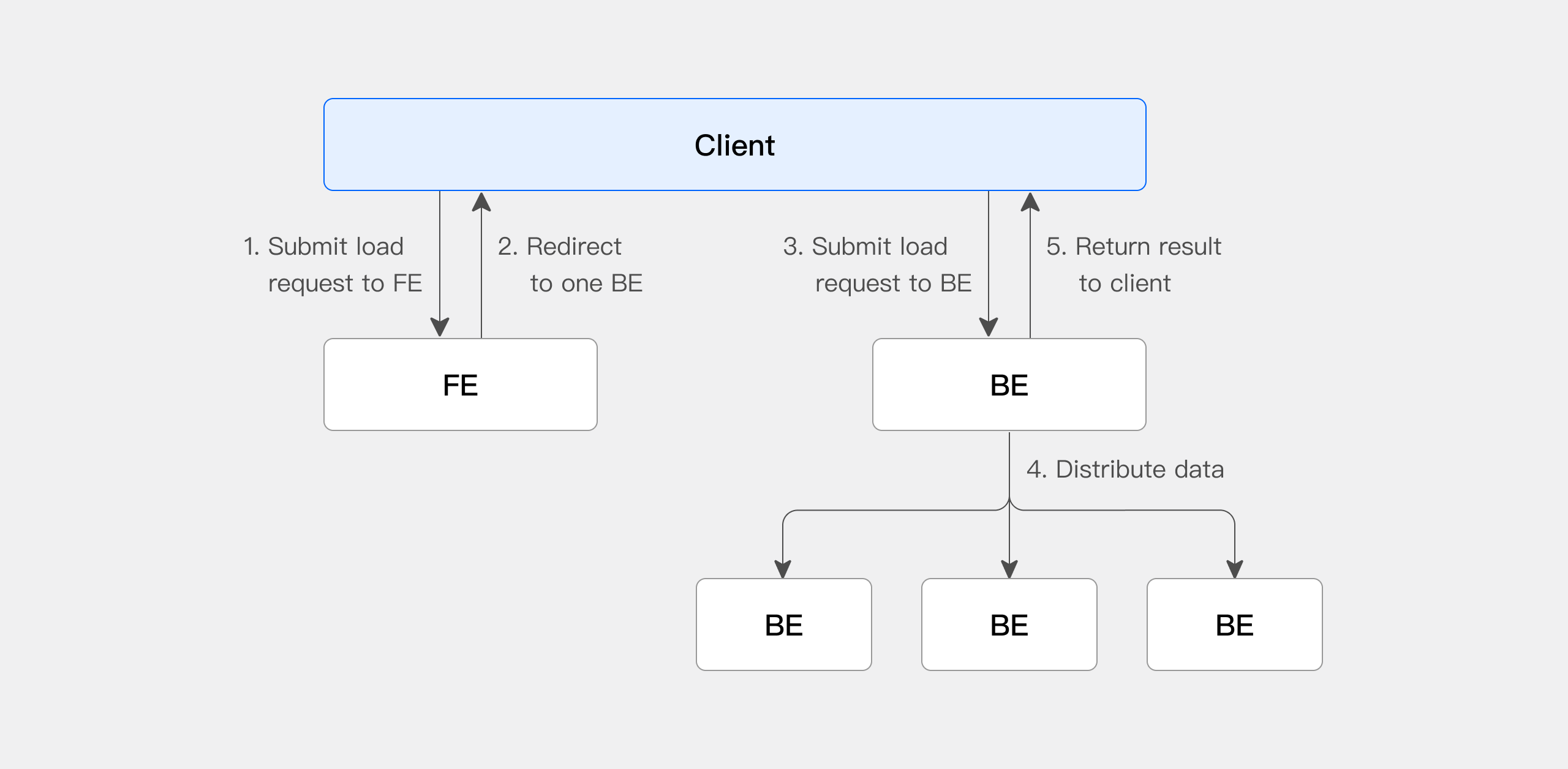
Client 向 FE 提交 Stream Load 导入作业请求
FE 会随机选择一台 BE 作为 Coordinator 节点,负责导入作业调度,然后返回给 Client 一个 HTTP 重定向
Client 连接 Coordinator BE 节点,提交导入请求
Coordinator BE 会分发数据给相应 BE 节点,导入完成后会返回导入结果给 Client
Client 也可以直接通过指定 BE 节点作为 Coordinator,直接分发导入作业
快速上手
Stream Load 通过 HTTP 协议提交和传输。下例以 curl 工具为例,演示通过 Stream Load 提交导入作业。
详细语法可以参见 STREAM LOAD
前置检查
Stream Load 需要对目标表的 INSERT 权限。如果没有 INSERT 权限,可以通过 GRANT 命令给用户授权。
创建导入作业
导入 CSV 数据
创建导入数据
创建 csv 文件 streamload_example.csv 文件。具体内容如下
1,Emily,25
2,Benjamin,35
3,Olivia,28
4,Alexander,60
5,Ava,17
6,William,69
7,Sophia,32
8,James,64
9,Emma,37
10,Liam,64创建导入 Doris 表
在 Doris 中创建被导入的表,具体语法如下
CREATE TABLE testdb.test_streamload(
user_id BIGINT NOT NULL COMMENT "用户 ID",
name VARCHAR(20) COMMENT "用户姓名",
age INT COMMENT "用户年龄"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;启用导入作业
通过
curl命令可以提交 Stream Load 导入作业。curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "column_separator:," \
-H "columns:user_id,name,age" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_loadStream Load 是一种同步导入方式,导入结果会直接返回给用户。
{
"TxnId": 3,
"Label": "123",
"Comment": "",
"TwoPhaseCommit": "false",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 10,
"NumberLoadedRows": 10,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 118,
"LoadTimeMs": 173,
"BeginTxnTimeMs": 1,
"StreamLoadPutTimeMs": 70,
"ReadDataTimeMs": 2,
"WriteDataTimeMs": 48,
"CommitAndPublishTimeMs": 52
}查看导入数据
mysql> select count(*) from testdb.test_streamload;
+----------+
| count(*) |
+----------+
| 10 |
+----------+
导入 JSON 数据
创建导入数据
创建 JSON 文件 streamload_example.json。具体内容如下
[
{"userid":1,"username":"Emily","userage":25},
{"userid":2,"username":"Benjamin","userage":35},
{"userid":3,"username":"Olivia","userage":28},
{"userid":4,"username":"Alexander","userage":60},
{"userid":5,"username":"Ava","userage":17},
{"userid":6,"username":"William","userage":69},
{"userid":7,"username":"Sophia","userage":32},
{"userid":8,"username":"James","userage":64},
{"userid":9,"username":"Emma","userage":37},
{"userid":10,"username":"Liam","userage":64}
]创建导入 Doris 表
在 Doris 中创建被导入的表,具体语法如下
CREATE TABLE testdb.test_streamload(
user_id BIGINT NOT NULL COMMENT "用户 ID",
name VARCHAR(20) COMMENT "用户姓名",
age INT COMMENT "用户年龄"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;启用导入作业
通过
curl命令可以提交 Stream Load 导入作业。curl --location-trusted -u <doris_user>:<doris_password> \
-H "label:124" \
-H "Expect:100-continue" \
-H "format:json" -H "strip_outer_array:true" \
-H "jsonpaths:[\"$.userid\", \"$.username\", \"$.userage\"]" \
-H "columns:user_id,name,age" \
-T streamload_example.json \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load备注若 JSON 文件内容不是 JSON Array,而是每行一个JSON对象, 添加 Header
-H "strip_outer_array:false"-H "read_json_by_line:true"。Stream Load 是一种同步导入方式,导入结果会直接返回给用户。
{
"TxnId": 7,
"Label": "125",
"Comment": "",
"TwoPhaseCommit": "false",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 10,
"NumberLoadedRows": 10,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 471,
"LoadTimeMs": 52,
"BeginTxnTimeMs": 0,
"StreamLoadPutTimeMs": 11,
"ReadDataTimeMs": 0,
"WriteDataTimeMs": 23,
"CommitAndPublishTimeMs": 16
}
查看导入作业
默认情况下,Stream Load 是同步返回给 Client,所以系统模式是不记录 Stream Load 历史作业的。如果需要记录,则在 be.conf 中添加配置 enable_stream_load_record=true。具体配置可以参考 BE 配置项。
配置后,可以通过 show stream load 命令查看已完成的 Stream Load 任务。
mysql> show stream load from testdb;
+-------+--------+-----------------+---------------+---------+---------+------+-----------+------------+--------------+----------------+-----------+-------------------------+-------------------------+------+---------+
| Label | Db | Table | ClientIp | Status | Message | Url | TotalRows | LoadedRows | FilteredRows | UnselectedRows | LoadBytes | StartTime | FinishTime | User | Comment |
+-------+--------+-----------------+---------------+---------+---------+------+-----------+------------+--------------+----------------+-----------+-------------------------+-------------------------+------+---------+
| 12356 | testdb | test_streamload | 192.168.88.31 | Success | OK | N/A | 10 | 10 | 0 | 0 | 118 | 2023-11-29 08:53:00.594 | 2023-11-29 08:53:00.650 | root | |
+-------+--------+-----------------+---------------+---------+---------+------+-----------+------------+--------------+----------------+-----------+-------------------------+-------------------------+------+---------+
1 row in set (0.00 sec)
取消导入作业
用户无法手动取消 Stream Load,Stream Load 在超时 0 或者导入错误后会被系统自动取消。
参考手册
导入命令
Stream Load 导入语法如下:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" [-H ""...] \
-T <file_path> \
-XPUT http://fe_host:http_port/api/{db}/{table}/_stream_load
Stream Load 操作支持 HTTP 分块导入(HTTP chunked)与 HTTP 非分块导入方式。对于非分块导入方式,必须要有 Content-Length 来标示上传内容的长度,这样能保证数据的完整性。
导入配置参数
FE 配置
- stream_load_default_timeout_second
默认值:259200(s)
动态配置:是
FE Master 独有配置:是
参数描述:Stream Load 默认的超时时间。导入任务的超时时间(以秒为单位),导入任务在设定的 timeout 时间内未完成则会被系统取消,变成 CANCELLED。如果导入的源文件无法在规定时间内完成导入,用户可以在 Stream Load 请求中设置单独的超时时间。或者调整 FE 的参数stream_load_default_timeout_second 来设置全局的默认超时时间。
enable_pipeline_load
是否开启 Pipeline 引擎执行 Streamload 任务。详见导入文档。
BE 配置
- streaming_load_max_mb
默认值:10240(MB)
动态配置:是
参数描述:Stream load 的最大导入大小。如果用户的原始文件超过这个值,则需要调整 BE 的参数
streaming_load_max_mb。
- Header 参数
可以通过 HTTP 的 Header 部分来传入导入参数。具体参数介绍如下:
| 标签 | 参数说明 |
|---|---|
| label | 用于指定 Doris 该次导入的标签,标签相同的数据无法多次导入。如果不指定 label,Doris 会自动生成一个标签。用户可以通过指定 label 的方式来避免一份数据重复导入的问题。Doris 默认保留三天内的导入作业标签,可以 label_keep_max_second 调整保留时长。例如,指定本次导入 label 为 123,需要指定命令 -H "label:123"。label 的使用,可以防止用户重复导入相同的数据。强烈推荐用户同一批次数据使用相同的 label。这样同一批次数据的重复请求只会被接受一次,保证了 At-Most-Once 当 label 对应的导入作业状态为 CANCELLED 时,该 label 可以再次被使用。 |
| column_separator | 用于指定导入文件中的列分隔符,默认为\t。如果是不可见字符,则需要加\x作为前缀,使用十六进制来表示分隔符。可以使用多个字符的组合作为列分隔符。例如,hive 文件的分隔符 \x01,需要指定命令 -H "column_separator:\x01"。 |
| line_delimiter | 用于指定导入文件中的换行符,默认为 \n。可以使用做多个字符的组合作为换行符。例如,指定换行符为 \n,需要指定命令 -H "line_delimiter:\n"。 |
| columns | 用于指定导入文件中的列和 table 中的列的对应关系。如果源文件中的列正好对应表中的内容,那么是不需要指定这个字段的内容的。如果源文件与表 schema 不对应,那么需要这个字段进行一些数据转换。有两种形式 column:直接对应导入文件中的字段,直接使用字段名表示衍生列,语法为 column_name = expression 详细案例参考 导入过程中数据转换。 |
| where | 用于抽取部分数据。用户如果有需要将不需要的数据过滤掉,那么可以通过设定这个选项来达到。例如,只导入大于 k1 列等于 20180601 的数据,那么可以在导入时候指定 -H "where: k1 = 20180601"。 |
| max_filter_ratio | 最大容忍可过滤(数据不规范等原因)的数据比例,默认零容忍。取值范围是 0~1。当导入的错误率超过该值,则导入失败。数据不规范不包括通过 where 条件过滤掉的行。例如,最大程度保证所有正确的数据都可以导入(容忍度 100%),需要指定命令 -H "max_filter_ratio:1"。 |
| partitions | 用于指定这次导入所涉及的 partition。如果用户能够确定数据对应的 partition,推荐指定该项。不满足这些分区的数据将被过滤掉。例如,指定导入到 p1, p2 分区,需要指定命令 -H "partitions: p1, p2"。 |
| timeout | 指定导入的超时时间。单位秒。默认是 600 秒。可设置范围为 1 秒 ~ 259200 秒。例如,指定导入超时时间为 1200s,需要指定命令 -H "timeout:1200"。 |
| strict_mode | 用户指定此次导入是否开启严格模式,默认为关闭。例如,指定开启严格模式,需要指定命令 -H "strict_mode:true"。 |
| timezone | 指定本次导入所使用的时区。默认为东八区。该参数会影响所有导入涉及的和时区有关的函数结果。例如,指定导入时区为 Africa/Abidjan,需要指定命令 -H "timezone:Africa/Abidjan"。 |
| exec_mem_limit | 导入内存限制。默认为 2GB。单位为字节。 |
| format | 指定导入数据格式,默认是 CSV 格式。目前支持以下格式:csv, json, arrow, csv_with_names(支持 csv 文件行首过滤)csv_with_names_and_types(支持 csv 文件前两行过滤)parquet, orc 例如,指定导入数据格式为 json,需要指定命令 -H "format:json"。 |
| jsonpaths | 导入 JSON 数据格式有两种方式:简单模式:没有指定 jsonpaths 为简单模式,这种模式要求 JSON 数据是对象类型匹配模式:用于 JSON 数据相对复杂,需要通过 jsonpaths 参数匹配对应的 value 在简单模式下,要求 JSON 中的 key 列与表中的列名是一一对应的,如 JSON 数据 {"k1":1, "k2":2, "k3":"hello"},其中 k1、k2 及 k3 分别对应表中的列。 |
| strip_outer_array | 指定 strip_outer_array 为 true 时表示 JSON 数据以数组对象开始且将数组对象中进行展平,默认为 false。在 JSON 数据的最外层是 [] 表示的数组时,需要设置 strip_outer_array 为 true。如以下示例数据,在设置 strip_outer_array 为 true 后,导入 Doris 中生成两行数据 [{"k1" : 1, "v1" : 2},{"k1" : 3, "v1" : 4}] |
| json_root | json_root 为合法的 jsonpath 字符串,用于指定 json document 的根节点,默认值为 ""。 |
| merge_type | 数据的合并类型,一共支持三种类型 APPEND、DELETE、MERGE:APPEND 是默认值,表示这批数据全部需要追加到现有数据中 DELETE 表示删除与这批数据 key 相同的所有行 MERGE 语义 需要与 delete 条件联合使用,表示满足 delete 条件的数据按照 DELETE 语义处理其余的按照 APPEND 语义处理例如,指定合并模式为 MERGE,需要指定命令-H "merge_type: MERGE" -H "delete: flag=1"。 |
| delete | 仅在 MERGE 下有意义,表示数据的删除条件 |
| function_column.sequence_col | 只适用于 UNIQUE KEYS 模型,相同 Key 列下,保证 Value 列按照 source_sequence 列进行 REPLACE。source_sequence 可以是数据源中的列,也可以是表结构中的一列。 |
| fuzzy_parse | 布尔类型,为 true 表示 JSON 将以第一行为 schema 进行解析。开启这个选项可以提高 json 导入效率,但是要求所有 json 对象的 key 的顺序和第一行一致,默认为 false,仅用于 JSON 格式 |
| num_as_string | 布尔类型,为 true 表示在解析 JSON 数据时会将数字类型转为字符串,确保不会出现精度丢失的情况下进行导入。 |
| read_json_by_line | 布尔类型,为 true 表示支持每行读取一个 json 对象,默认值为 false。 |
| send_batch_parallelism | 整型,用于设置发送批处理数据的并行度,如果并行度的值超过 BE 配置中的 max_send_batch_parallelism_per_job,那么作为协调点的 BE 将使用 max_send_batch_parallelism_per_job 的值。 |
| hidden_columns | 用于指定导入数据中包含的隐藏列,在 Header 中不包含 Columns 时生效,多个 hidden column 用逗号分割。系统会使用用户指定的数据导入数据。在下例中,导入数据中最后一列数据为 __DORIS_SEQUENCE_COL__。hidden_columns: __DORIS_DELETE_SIGN__,__DORIS_SEQUENCE_COL__ |
| load_to_single_tablet | 布尔类型,为 true 表示支持一个任务只导入数据到对应分区的一个 Tablet,默认值为 false。该参数只允许在对带有 random 分桶的 OLAP 表导数的时候设置。 |
| compress_type | 指定文件的压缩格式。目前只支持 CSV 文件的压缩。支持 gz, lzo, bz2, lz4, lzop, deflate 压缩格式。 |
| trim_double_quotes | 布尔类型,默认值为 false,为 true 时表示裁剪掉 CSV 文件每个字段最外层的双引号。 |
| skip_lines | 整数类型,默认值为 0,含义为跳过 CSV 文件的前几行。当设置 format 设置为 csv_with_names或csv_with_names_and_types时,该参数会失效。 |
| comment | 字符串类型,默认值为空。给任务增加额外的信息。 |
| enclose | 指定包围符。当 CSV 数据字段中含有行分隔符或列分隔符时,为防止意外截断,可指定单字节字符作为包围符起到保护作用。例如列分隔符为 ",",包围符为 "'",数据为 "a,'b,c'",则 "b,c" 会被解析为一个字段。注意:当 enclose 设置为"时,trim_double_quotes 一定要设置为 true。 |
| escape | 指定转义符。用于转义在字段中出现的与包围符相同的字符。例如数据为 "a,'b,'c'",包围符为 "'",希望 "b,'c 被作为一个字段解析,则需要指定单字节转义符,例如 \,将数据修改为 a,'b,\'c'。 |
| memtable_on_sink_node | 导入数据的时候是否开启 MemTable 前移,默认为 false。 |
导入返回值
Stream Load 是一种同步的导入方式,导入结果会通过创建导入的返回值直接给用户,如下所示:
{
"TxnId": 1003,
"Label": "b6f3bc78-0d2c-45d9-9e4c-faa0a0149bee",
"Status": "Success",
"ExistingJobStatus": "FINISHED", // optional
"Message": "OK",
"NumberTotalRows": 1000000,
"NumberLoadedRows": 1000000,
"NumberFilteredRows": 1,
"NumberUnselectedRows": 0,
"LoadBytes": 40888898,
"LoadTimeMs": 2144,
"BeginTxnTimeMs": 1,
"StreamLoadPutTimeMs": 2,
"ReadDataTimeMs": 325,
"WriteDataTimeMs": 1933,
"CommitAndPublishTimeMs": 106,
"ErrorURL": "http://192.168.1.1:8042/api/_load_error_log?file=__shard_0/error_log_insert_stmt_db18266d4d9b4ee5-abb00ddd64bdf005_db18266d4d9b4ee5_abb00ddd64bdf005"
}
其中,返回结果参数如下表说明:
| 参数名称 | 说明 |
|---|---|
| TxnId | 导入事务的 ID |
| Label | 导入作业的 label,通过 -H "label:<label_id> 指定 |
| Status | 导入的最终状态 Success:表示导入成功 Publish Timeout:该状态也表示导入已经完成,只是数据可能会延迟可见,无需重试 Label Already Exists:Label 重复,需要更换 labelFail:导入失败 |
| ExistingJobStatus | 已存在的 Label 对应的导入作业的状态。这个字段只有在当 Status 为 "Label Already Exists" 时才会显示。用户可以通过这个状态,知晓已存在 Label 对应的导入作业的状态。"RUNNING" 表示作业还在执行,"FINISHED" 表示作业成功。 |
| Message | 导入错误信息 |
| NumberTotalRows | 导入总处理的行数 |
| NumberLoadedRows | 成功导入的行数 |
| NumberFilteredRows | 数据质量不合格的行数 |
| NumberUnselectedRows | 被 where 条件过滤的行数 |
| LoadBytes | 导入的字节数 |
| LoadTimeMs | 导入完成时间。单位毫秒 |
| BeginTxnTimeMs | 向 FE 请求开始一个事务所花费的时间,单位毫秒 |
| StreamLoadPutTimeMs | 向 FE 请求获取导入数据执行计划所花费的时间,单位毫秒 |
| ReadDataTimeMs | 读取数据所花费的时间,单位毫秒 |
| WriteDataTimeMs | 执行写入数据操作所花费的时间,单位毫秒 |
| CommitAndPublishTimeMs | 向 FE 请求提交并且发布事务所花费的时间,单位毫秒 |
| ErrorURL | 如果有数据质量问题,通过访问这个 URL 查看具体错误行 |
通过 ErrorURL 可以查看因为数据质量不佳导致的导入失败数据。使用命令 curl "<ErrorURL>" 命令直接查看错误数据的信息。
TVF 在 Stream Load 中的应用 - http_stream 模式
依托 Doris 最新引入的 Table Value Function(TVF)的功能,在 Stream Load 中,可以通过使用 SQL 表达式来表达导入的参数。这个专门为 Stream Load 提供的 TVF 为 http_stream。
注意
使用 TVF http_stream 进行 Stream Load 导入时的 Rest API URL 不同于 Stream Load 普通导入的 URL。
普通导入的 URL 为:
http://fe_host:http_port/api/{db}/{table}/_stream_load
使用 TVF http_stream 导入的 URL 为:
http://fe_host:http_port/api/_http_stream
使用 curl 来使用 Stream Load 的 http stream 模式:
curl --location-trusted -u user:passwd [-H "sql: ${load_sql}"...] -T data.file -XPUT http://fe_host:http_port/api/_http_stream
在 Header 中添加一个sql的参数,去替代之前参数中的column_separator、line_delimiter、where、columns等参数,使用起来非常方便。
load_sql 举例:
insert into db.table (col, ...) select stream_col, ... from http_stream("property1"="value1");
http_stream 支持的参数:
"column_separator" = ",", "format" = "CSV",
...
示例:
curl --location-trusted -u root: -T test.csv -H "sql:insert into demo.example_tbl_1(user_id, age, cost) select c1, c4, c7 * 2 from http_stream(\"format\" = \"CSV\", \"column_separator\" = \",\" ) where age >= 30" http://127.0.0.1:28030/api/_http_stream
导入举例
设置导入超时时间与最大导入
导入任务的超时时间(以秒为单位),导入任务在设定的 timeout 时间内未完成则会被系统取消,变成 CANCELLED。通过指定参数 timeout 或者在 fe.conf 中添加参数 stream_load_default_timeout_second,可以调整 Stream Load 的导入超时时间。
在导入前需要根据文件大小计算导入的超时时间,如 100GB 的文件,预估 50MB/s 的性能导入:
导入时间 ≈ 100GB / 50MB/s ≈ 2048s
通过以下命令可以指定 timeout 3000s 创建 stream load 导入任务:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "timeout:3000"
-H "column_separator:," \
-H "columns:user_id,name,age" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
设置导入最大容错率
Doris 的导入任务可以容忍一部分格式错误的数据。容忍率通过 max_filter_ratio 设置。默认为 0,即表示当有一条错误数据时,整个导入任务将会失败。如果用户希望忽略部分有问题的数据行,可以将次参数设置为 0~1 之间的数值,Doris 会自动跳过哪些数据格式不正确的行。关于容忍率的一些计算方式,可以参阅 数据转换 文档。
通过以下命令可以指定 max_filter_ratio 容忍度为 0.4 创建 stream load 导入任务:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "max_filter_ratio:0.4" \
-H "column_separator:," \
-H "columns:user_id,name,age" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
设置导入过滤条件
导入过程中可以通过 WHERE 参数对导入的数据进行条件过滤。被过滤的数据不会参与到 filter ratio 的计算中,不影响 max_filter_ratio 的设置。在导入结束后,可以通过查看 num_rows_unselected 获取过滤的行数。
通过以下命令可以指定 WHERE 过滤条件创建 Stream Load 导入任务:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "where:age>=35" \
-H "column_separator:," \
-H "columns:user_id,name,age" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
导入指定分区数据
将本地文件中的数据导入到表中的 p1, p2 分区,允许 20% 的错误率。
curl --location-trusted -u <doris_user>:<doris_password> \
-H "label:123" \
-H "Expect:100-continue" \
-H "max_filter_ratio:0.2" \
-H "column_separator:," \
-H "columns:user_id,name,age" \
-H "partitions: p1, p2" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
指定导入时区
由于 Doris 目前没有内置时区的时间类型,所有 DATETIME 相关类型均只表示绝对的时间点,而不包含时区信息,不因 Doris 系统时区变化而发生变化。因此,对于带时区数据的导入,我们统一的处理方式为将其转换为特定目标时区下的数据。在 Doris 系统中,即 session variable time_zone 所代表的时区。
而在导入中,我们的目标时区通过参数 timezone 指定,该变量在发生时区转换、运算时区敏感函数时将会替代 session variable time_zone。因此,如果没有特殊情况,在导入事务中应当设定 timezone 与当前 Doris 集群的 time_zone 一致。此时意味着所有带时区的时间数据,均会发生向该时区的转换。
例如,Doris 系统时区为 "+08:00",导入数据中的时间列包含两条数据,分别为 "2012-01-01 01:00:00+00:00" 和 "2015-12-12 12:12:12-08:00",则我们在导入时通过 -H "timezone: +08:00" 指定导入事务的时区后,这两条数据都会向该时区发生转换,从而得到结果 "2012-01-01 09:00:00" 和 "2015-12-13 04:12:12"。
更多关于时区解读可参考文档 时区。
使用 Streaming 方式导入
Stream Load 是基于 HTTP 的协议进行导入,所以是支持使用程序,比如 Java、Go 或者 Python 等程序来流式写入,这也是为什么起名叫 Stream Load 的原因。
下面通过 bash 的命令管道来举例这种使用方式,这种导入的数据就是程序流式生成的,而不是本地文件。
seq 1 10 | awk '{OFS="\t"}{print $1, $1 * 10}' | curl --location-trusted -u root -T - http://host:port/api/testDb/testTbl/_stream_load
设置 CSV 首行过滤导入
文件数据:
id,name,age
1,doris,20
2,flink,10
通过指定format=csv_with_names过滤首行导入
curl --location-trusted -u root -T test.csv -H "label:1" -H "format:csv_with_names" -H "column_separator:," http://host:port/api/testDb/testTbl/_stream_load
指定 merge_type 进行 Delete 操作
在 Stream Load 中有三种导入类型:APPEND、DELETE 与 MERGE。可以通过指定参数 merge_type 进行调整。如想指定将与导入数据 Key 相同的数据全部删除,可以使用以下命令:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "merge_type: DELETE" \
-H "column_separator:," \
-H "columns:user_id,name,age" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
如导入数据前表中数据为:
+--------+----------+----------+------+
| siteid | citycode | username | pv |
+--------+----------+----------+------+
| 3 | 2 | tom | 2 |
| 4 | 3 | bush | 3 |
| 5 | 3 | helen | 3 |
+--------+----------+----------+------+
导入数据为:
3,2,tom,0
导入后会删除原表数据,变成以下结果集
+--------+----------+----------+------+
| siteid | citycode | username | pv |
+--------+----------+----------+------+
| 4 | 3 | bush | 3 |
| 5 | 3 | helen | 3 |
+--------+----------+----------+------+
指定 merge_type 进行 Merge 操作
指定 merge_type 为 MERGE,可以将导入的数据 MERGE 到表中。MERGE 语义需要结合 DELETE 条件联合使用,表示满足 DELETE 条件的数据按照 DELETE 语义处理,其余按照 APPEND 语义添加到表中,如下面操作表示删除 siteid 为 1 的行,其余数据添加到表中:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "merge_type: MERGE" \
-H "delete: siteid=1" \
-H "column_separator:," \
-H "columns:user_id,name,age" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
如导入前的数据为:
+--------+----------+----------+------+
| siteid | citycode | username | pv |
+--------+----------+----------+------+
| 4 | 3 | bush | 3 |
| 5 | 3 | helen | 3 |
| 1 | 1 | jim | 2 |
+--------+----------+----------+------+
导入的数据为:
2,1,grace,2
3,2,tom,2
1,1,jim,2
导入后,将按照条件删除 siteid = 1 的行,siteid 为 2 与 3 的行会添加到表中:
+--------+----------+----------+------+
| siteid | citycode | username | pv |
+--------+----------+----------+------+
| 4 | 3 | bush | 3 |
| 2 | 1 | grace | 2 |
| 3 | 2 | tom | 2 |
| 5 | 3 | helen | 3 |
+--------+----------+----------+------+
指定导入需要 Merge 的 Sequence 列
当 Unique Key 表设置了 Sequence 列时,在相同 Key 列下,Sequence 列的值会作为 REPLACE 聚合函数替换顺序的依据,较大值可以替换较小值。当对这种表基于DORIS_DELETE_SIGN 进行删除标记时,需要保证 Key 相同和 Sequence 列值要大于等于当前值。通过制定 function_column.sequence_col 参数可以结合 merge_type: DELETE 进行删除操作:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "merge_type: DELETE" \
-H "function_column.sequence_col: age"
-H "column_separator:," \
-H "columns: name, gender, age"
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
如有以下表结构:
mysql> SET show_hidden_columns=true;
Query OK, 0 rows affected (0.00 sec)
mysql> DESC table1;
+------------------------+--------------+------+-------+---------+---------+
| Field | Type | Null | Key | Default | Extra |
+------------------------+--------------+------+-------+---------+---------+
| name | VARCHAR(100) | No | true | NULL | |
| gender | VARCHAR(10) | Yes | false | NULL | REPLACE |
| age | INT | Yes | false | NULL | REPLACE |
| __DORIS_DELETE_SIGN__ | TINYINT | No | false | 0 | REPLACE |
| __DORIS_SEQUENCE_COL__ | INT | Yes | false | NULL | REPLACE |
+------------------------+--------------+------+-------+---------+---------+
4 rows in set (0.00 sec)
假设原表中数据为:
+-------+--------+------+
| name | gender | age |
+-------+--------+------+
| li | male | 10 |
| wang | male | 14 |
| zhang | male | 12 |
+-------+--------+------+
1. Sequence 参数生效,导入 Sequence 列大于等于表中原有数据
导入数据为:
li,male,10
由于指定了 function_column.sequence_col: age,并且 age 大于等于表中原有的列,原表数据被删除,表中数据变为:
+-------+--------+------+
| name | gender | age |
+-------+--------+------+
| wang | male | 14 |
| zhang | male | 12 |
+-------+--------+------+
2. Sequence 参数未生效,导入 Sequence 列小于等于表中原有数据:
导入数据为:
li,male,9
由于指定了 function_column.sequence_col: age,但 age 小于表中原有的列,DELETE 操作并未生效,表中数据不变,依然会看到主键为 li 的列:
+-------+--------+------+
| name | gender | age |
+-------+--------+------+
| li | male | 10 |
| wang | male | 14 |
| zhang | male | 12 |
+-------+--------+------+
并没有被删除,这是因为在底层的依赖关系上,会先判断 Key 相同的情况,对外展示 Sequence 列的值大的行数据,然后在看该行的 DORIS_DELETE_SIGN 值是否为 1,如果为 1 则不会对外展示,如果为 0,则仍会读出来。
导入包含包围符的数据
当 CSV 中的数据包含了分隔符或者分列符,为了防止截断,可以指定单字节字符作为包围符起到保护的作用。
如下列数据中,列中包含了分隔符 ,:
张三,30,'上海市,黄浦区,大沽路'
通过制定包围符',可以将“上海市,黄浦区,大沽路”指定为一个字段:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "column_separator:," \
-H "enclose:'" \
-H "escape:\" \
-H "columns:username,age,address" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
如果包围字符也出现在字段中,如希望将“上海市,黄浦区,'大沽路”作为一个字段,需要先在列中进行字符串转义:
张三,30,'上海市,黄浦区,\'大沽路'
可以通过 escape 参数可以指定单字节转义字符,如下例中 \:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "column_separator:," \
-H "enclose:'" \
-H "columns:username,age,address" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
导入包含 DEFAULT CURRENT_TIMESTAMP 类型的字段
下面给出导入数据到表字段含有 DEFAULT CURRENT_TIMESTAMP 的表中的例子:
表结构:
`id` bigint(30) NOT NULL,
`order_code` varchar(30) DEFAULT NULL COMMENT '',
`create_time` datetimev2(3) DEFAULT CURRENT_TIMESTAMP
JSON 数据格式:
{"id":1,"order_Code":"avc"}
导入命令:
curl --location-trusted -u root -T test.json -H "label:1" -H "format:json" -H 'columns: id, order_code, create_time=CURRENT_TIMESTAMP()' http://host:port/api/testDb/testTbl/_stream_load
简单模式导入 JSON 格式数据
在 JSON 字段和表中的列名一一对应时,可以通过指定参数 "strip_outer_array:true" 与 "format:json" 将 JSON 数据格式导入到表中。
如表定义如下:
CREATE TABLE testdb.test_streamload(
user_id BIGINT NOT NULL COMMENT "用户 ID",
name VARCHAR(20) COMMENT "用户姓名",
age INT COMMENT "用户年龄"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;
导入数据字段名与表中的字段名一一对应:
[
{"user_id":1,"name":"Emily","age":25},
{"user_id":2,"name":"Benjamin","age":35},
{"user_id":3,"name":"Olivia","age":28},
{"user_id":4,"name":"Alexander","age":60},
{"user_id":5,"name":"Ava","age":17},
{"user_id":6,"name":"William","age":69},
{"user_id":7,"name":"Sophia","age":32},
{"user_id":8,"name":"James","age":64},
{"user_id":9,"name":"Emma","age":37},
{"user_id":10,"name":"Liam","age":64}
]
通过以下命令,可以将 JSON 数据导入到表中:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "format:json" \
-H "strip_outer_array:true" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
匹配模式导入复杂的 JSON 格式数据
在 JSON 数据较为复杂,无法与表中的列名一一对应,或者有多余的列时,可以通过指定参数 jsonpaths 完成列名映射,进行数据匹配导入。如下列数据:
[
{"userid":1,"hudi":"lala","username":"Emily","userage":25,"userhp":101},
{"userid":2,"hudi":"kpkp","username":"Benjamin","userage":35,"userhp":102},
{"userid":3,"hudi":"ji","username":"Olivia","userage":28,"userhp":103},
{"userid":4,"hudi":"popo","username":"Alexander","userage":60,"userhp":103},
{"userid":5,"hudi":"uio","username":"Ava","userage":17,"userhp":104},
{"userid":6,"hudi":"lkj","username":"William","userage":69,"userhp":105},
{"userid":7,"hudi":"komf","username":"Sophia","userage":32,"userhp":106},
{"userid":8,"hudi":"mki","username":"James","userage":64,"userhp":107},
{"userid":9,"hudi":"hjk","username":"Emma","userage":37,"userhp":108},
{"userid":10,"hudi":"hua","username":"Liam","userage":64,"userhp":109}
]
通过指定 jsonpaths 参数可以匹配指定的列:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "format:json" \
-H "strip_outer_array:true" \
-H "jsonpaths:[\"$.userid\", \"$.username\", \"$.userage\"]" \
-H "columns:user_id,name,age" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
指定 JSON 根节点导入数据
如果 JSON 数据包含了嵌套 JSON 字段,需要指定导入 json 的根节点。默认值为“”。
如下列数据,期望将 comment 列中的数据导入到表中:
[
{"user":1,"comment":{"userid":101,"username":"Emily","userage":25}},
{"user":2,"comment":{"userid":102,"username":"Benjamin","userage":35}},
{"user":3,"comment":{"userid":103,"username":"Olivia","userage":28}},
{"user":4,"comment":{"userid":104,"username":"Alexander","userage":60}},
{"user":5,"comment":{"userid":105,"username":"Ava","userage":17}},
{"user":6,"comment":{"userid":106,"username":"William","userage":69}},
{"user":7,"comment":{"userid":107,"username":"Sophia","userage":32}},
{"user":8,"comment":{"userid":108,"username":"James","userage":64}},
{"user":9,"comment":{"userid":109,"username":"Emma","userage":37}},
{"user":10,"comment":{"userid":110,"username":"Liam","userage":64}}
]
首先需要通过 json_root 参数指定根节点为 comment,然后根据 jsonpaths 参数完成列名映射:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "format:json" \
-H "strip_outer_array:true" \
-H "json_root: $.comment" \
-H "jsonpaths:[\"$.userid\", \"$.username\", \"$.userage\"]" \
-H "columns:user_id,name,age" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
导入 Array 数据类型
如下列数据中包含了数组类型:
1|Emily|[1,2,3,4]
2|Benjamin|[22,45,90,12]
3|Olivia|[23,16,19,16]
4|Alexander|[123,234,456]
5|Ava|[12,15,789]
6|William|[57,68,97]
7|Sophia|[46,47,49]
8|James|[110,127,128]
9|Emma|[19,18,123,446]
10|Liam|[89,87,96,12]
将数据导入以下的表结构中:
CREATE TABLE testdb.test_streamload(
typ_id BIGINT NOT NULL COMMENT "ID",
name VARCHAR(20) NULL COMMENT "名称",
arr ARRAY<int(10)> NULL COMMENT "数组"
)
DUPLICATE KEY(typ_id)
DISTRIBUTED BY HASH(typ_id) BUCKETS 10;
通过 Stream Load 任务作业,可以直接将文本文件中的 ARRAY 类型导入到表中:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "column_separator:|" \
-H "columns:typ_id,name,arr" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
导入 map 数据类型
当导入数据中包含 map 类型,如以下的例子中:
[
{"user_id":1,"namemap":{"Emily":101,"age":25}},
{"user_id":2,"namemap":{"Benjamin":102,"age":35}},
{"user_id":3,"namemap":{"Olivia":103,"age":28}},
{"user_id":4,"namemap":{"Alexander":104,"age":60}},
{"user_id":5,"namemap":{"Ava":105,"age":17}},
{"user_id":6,"namemap":{"William":106,"age":69}},
{"user_id":7,"namemap":{"Sophia":107,"age":32}},
{"user_id":8,"namemap":{"James":108,"age":64}},
{"user_id":9,"namemap":{"Emma":109,"age":37}},
{"user_id":10,"namemap":{"Liam":110,"age":64}}
]
将数据导入以下表结构中:
CREATE TABLE testdb.test_streamload(
user_id BIGINT NOT NULL COMMENT "ID",
namemap Map<STRING, INT> NULL COMMENT "名称"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;
通过 Stream Load 任务作业,可以直接将文本文件中的 map 类型导入到表中:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "format: json" \
-H "strip_outer_array:true" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
导入 Bitmap 类型数据
在导入过程中,遇到 Bitmap 类型的数据,可以通过 to_bitmap 将数据转换成 Bitmap,或者通过 bitmap_empty 函数填充 Bitmap。
如导入数据如下:
1|koga|17723
2|nijg|146285
3|lojn|347890
4|lofn|489871
5|jfin|545679
6|kon|676724
7|nhga|767689
8|nfubg|879878
9|huang|969798
10|buag|97997
将数据导入到以下包含 Bitmap 类型的表中:
CREATE TABLE testdb.test_streamload(
typ_id BIGINT NULL COMMENT "ID",
hou VARCHAR(10) NULL COMMENT "one",
arr BITMAP BITMAP_UNION NULL COMMENT "two"
)
AGGREGATE KEY(typ_id,hou)
DISTRIBUTED BY HASH(typ_id,hou) BUCKETS 10;
通过以 to_bitmap 可以将数据转换成 Bitmap 类型:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "columns:typ_id,hou,arr,arr=to_bitmap(arr)"
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
导入 HLL 数据类型
通过 hll_hash 函数可以将数据转换成 hll 类型,如下数据:
1001|koga
1002|nijg
1003|lojn
1004|lofn
1005|jfin
1006|kon
1007|nhga
1008|nfubg
1009|huang
1010|buag
导入下例表中:
CREATE TABLE testdb.test_streamload(
typ_id BIGINT NULL COMMENT "ID",
typ_name VARCHAR(10) NULL COMMENT "NAME",
pv hll hll_union NULL COMMENT "hll"
)
AGGREGATE KEY(typ_id,typ_name)
DISTRIBUTED BY HASH(typ_id) BUCKETS 10;
通过 hll_hash 命令进行导入:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "column_separator:|" \
-H "columns:typ_id,typ_name,pv=hll_hash(typ_id)" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
Label、导入事务、多表原子性
Doris 中所有导入任务都是原子生效的。并且在同一个导入任务中对多张表的导入也能够保证原子性。同时,Doris 还可以通过 Label 的机制来保证数据导入的不丢不重。具体说明可以参阅 导入事务和原子性 文档。
列映射、衍生列和过滤
Doris 可以在导入语句中支持非常丰富的列转换和过滤操作。支持绝大多数内置函数和 UDF。关于如何正确的使用这个功能,可参阅 数据转换 文档。
启用严格模式导入
strict_mode 属性用于设置导入任务是否运行在严格模式下。该属性会对列映射、转换和过滤的结果产生影响,它同时也将控制部分列更新的行为。关于严格模式的具体说明,可参阅 严格模式 文档。
导入时进行部分列更新
关于导入时,如何表达部分列更新,可以参考 数据操作/数据更新 文档
更多帮助
关于 Stream Load 使用的更多详细语法及最佳实践,请参阅 Stream Load 命令手册,你也可以在 MySQL 客户端命令行下输入 HELP STREAM LOAD 获取更多帮助信息。
