Runtime Filter
Runtime Filter 主要分为两种,Join Runtime Filter 与 TopN Runtime Filter。本文将详细介绍两类 Runtime Filter 的工作原理、使用指南与调优方法。
Join Runtime Filter
Join Runtime Filter (以下简称 JRF) 是一种优化技术,它根据运行时数据在 Join 节点通过 Join 条件动态生成 Filter。此技术不仅能降低 Join Probe 的规模,还能有效减少数据 IO 和网络传输。
工作原理
我们以一个类似 TPC-H Schema 上的 Join 为例,来说明 JRF 的工作原理。
假设数据库中有两张表:
订单表(orders),包含 1 亿行数据,记录订单号 (o_orderkey)、客户编号 (o_custkey) 以及订单的其它信息。
客户表(customer),包含 10 万行数据,记录客户编号 (c_custkey)、客户国籍 (c_nation) 以及客户的其它信息。该表共记录了 25 个国家的客户,每个国家约有 4 千客户。
统计客户来自中国的订单数量,查询语句如下:
select count(*)
from orders join customer on o_custkey = c_custkey
where c_nation = "china"
此查询的执行计划主体是一个 Join,如下图所示:
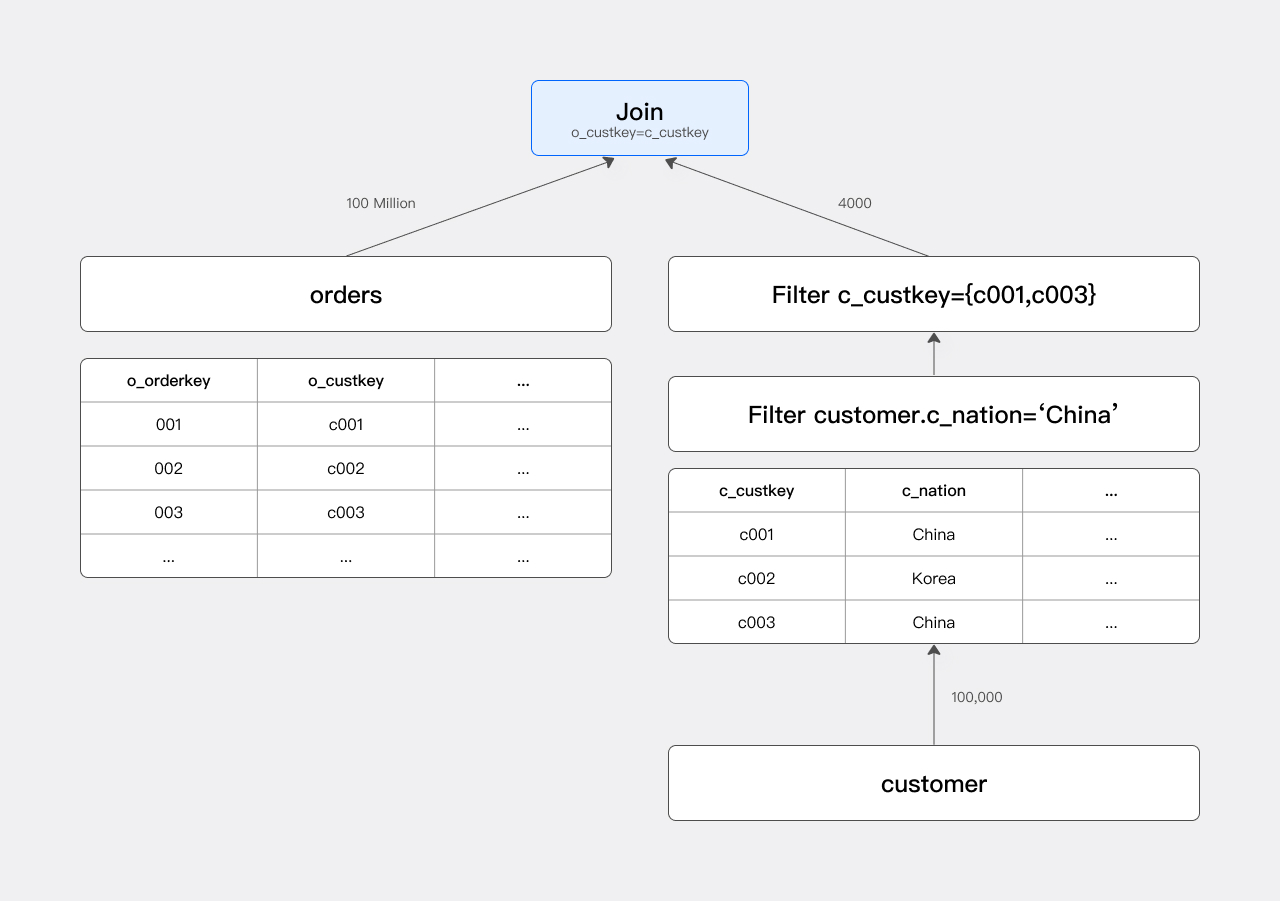
在没有 JRF 的情况下,Scan 节点会扫描 orders 表,读入 1 亿行数据,Join 节点则对这 1 亿行数据进行 Hash Probe,最后生成 Join 结果。
1. 优化思路
过滤条件 c_nation = "china" 会过滤掉所有非中国的客户,因此参与 Join 的 customer 只是 customer 表的一部分(约 1/25)。后续的 Join 条件为 o_custkey = c_custkey,所以我们需要关注过滤结果中 c_custkey 列有哪些被选中的 custkey。将过滤后的 c_custkey 记为集合 A。在下文中,我们用集合 A 专门指代参与 Join 的 c_custkey 集合。
如果将集合 A 作为一个 in 条件推给 orders 表,那么 orders 表的 Scan 节点就可以对 orders 进行过滤。这就类似增加了一个过滤条件 c_custkey in (c001, c003)。
基于以上的优化思路,SQL 可以优化为:
select count(*)
from orders join customer on o_custkey = c_custkey
where c_nation = "china" and o_custkey in (c001, c003)
优化后的执行计划如下图所示:
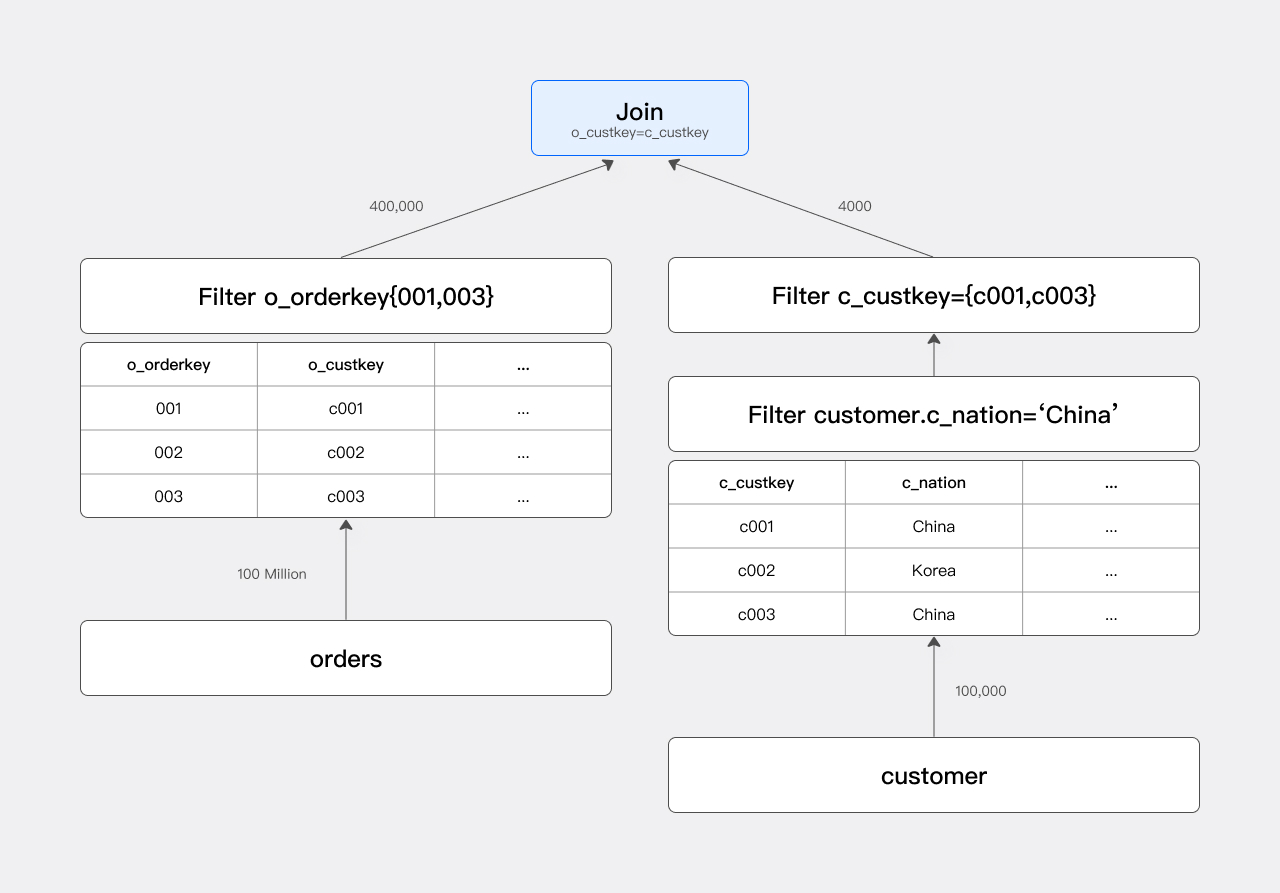
可以看到,通过增加 Orders 表上的过滤条件,实际参与 Join 的 Orders 行数从 1 亿下降到 40 万,查询速度得到大幅提升。
2. 实现方法
上述优化效果显著,但优化器并不知道实际被选中的 c_custkey,即集合 A。因此,优化器无法在优化阶段静态分析生成一个固定的 in-predicate 过滤算子。
在实际应用中,我们会在 Join 节点收集右侧数据后,运行时生成集合 A,并将集合 A 下推给 orders 表的 scan 节点。我们通常将这个 JRF 记为:RF(c_custkey -> [o_custkey])。
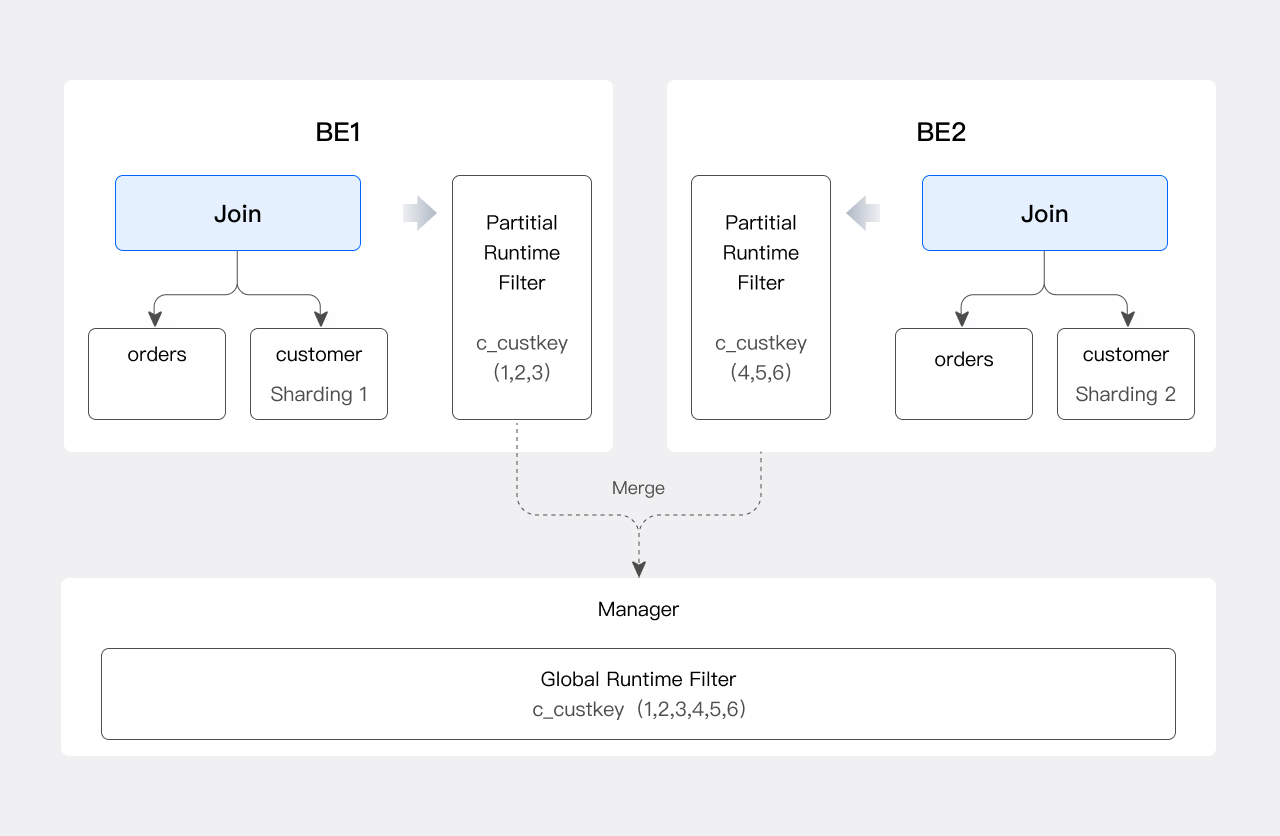
Doris 是一个分布式数据库,为了满足分布式场景的需求,JRF 还需要进行一次合并。假设上述例子中的 Join 是一个 Shuffle Join,那么这个 Join 有多个 Instance,每个 Join 只处理 orders 和 customer 表的一个分片。因此,每个 Join Instance 都只得到了集合 A 的一部分。
在当前 Doris 的版本中,我们会选出一个节点作为 Runtime Filter Manager。每个 Join Instance 根据各自分片中的 c_custkey 生成 Partial JRF,并发送给 Manager。Manager 收集所有 Partial JRF 后,合并生成 Global JRF,再将 Global JRF 发送给 orders 表的所有 Scan Instance。
生成 Global JRF 的流程如下图所示:
Filter 类型
有多种数据结构均可用于实现 JRF,但它们在生成、合并、传输、应用等方面效率各异,因此各自适用于不同的场景。
1. In Filter
这是实现 JRF 的最简单方式。以之前的例子为例,使用 In Filter 时,执行引擎会在左表上生成谓词 o_custkey in (...A 中元素列表...)。通过这个 In 过滤条件,可以对 orders 表进行过滤。当集合 A 中元素数量较少时,In Filter 的效率较高。
然而,当集合 A 中元素数量过大时,使用 In Filter 会带来性能问题:
首先,生成 In Filter 的成本较高,尤其是在需要进行 JRF 合并的情况下。因为从不同数据分片对应的 Join 节点中收集的值可能会有重复,例如,如果
c_custkey不是表的主键,那么c001、c003这样的c_custkey可能出现多次,这时就需要进行去重操作,而这个过程比较耗时。其次,当集合 A 元素较多时,Join 节点与 orders 表的 Scan 节点之间传输数据的代价也较高。
最后,orders 表的 Scan 节点执行 In 谓词也会消耗时间。
基于上述考虑,我们引入了 Bloom Filter。
2. Bloom Filter
如果对 Bloom Filter 不太了解,可以将其理解为一个哈希表。简单来说,Bloom Filter 就是一组叠加的哈希表。使用 Bloom Filter(或哈希表)进行过滤,利用了以下性质:
基于集合 A 生成哈希表 T,如果一个元素不在哈希表 T 中,那么可以断定这个元素也不在集合 A 中。反之,则不成立。
因此,如果一个
o_orderkey被 Bloom Filter 过滤掉,那么可以断定在 Join 的右侧没有相等的c_custkey。但由于哈希碰撞,一些o_custkey即使没有相等的c_custkey,也可能通过 Bloom Filter。所以,虽然 Bloom Filter 不能实现精准过滤,但仍然能达到一定的过滤效果。
哈希表的桶数量决定了过滤的准确率。桶数量越大,Filter 的大小越大,准确性越高,但生成、传输、使用的计算代价也越大。
因此,Bloom Filter 的大小也需要在过滤效果和使用代价之间取得平衡。基于此,我们设置了一组可配参数来约束 Bloom Filter 的最大和最小值,分别是
RUNTIME_BLOOM_FILTER_MIN_SIZE和RUNTIME_BLOOM_FILTER_MAX_SIZE。
3. Min/Max Filter
除了 Bloom Filter 外,还有 Min-Max Filter 可用于进行模糊过滤。如果数据列是有序的,那么 Min-Max Filter 会有很好的过滤效果。此外,生成、合并、使用 Min-Max Filter 的代价也远低于 In Filter 和 Bloom Filter。
对于非等值的 Join,In Filter 和 Bloom Filter 都无法工作,但 Min-Max Filter 仍然可以继续发挥作用。假设我们将上例中的查询修改为:
select count(*)
from orders join customer on o_custkey > c_custkey
where c_name = "China"
那么可以选出过滤后最大的 c_custkey,记为 n,并将 n 传给 orders 表的 scan 节点。scan 节点则会只输出 o_custkey > n 的行。
查看 Join Runtime Filter
查看一个 Query 上生成了哪些 JRF,可以通过 explain / explain shape plan / explain physical plan 命令来查看。
我们以 TPC-H Schema 为例,详细说明通过这三个命令如何查看 JRF。
select count(*) from orders join customer on o_custkey=c_custkey;
1. Explain
在传统 Explain 文本中,JRF(Join Reference File)的信息分布通常出现在 Join 节点和 Scan 节点中,具体展示如下图所示:
4: VHASH JOIN(258)
| join op: INNER JOIN(PARTITIONED)[]
| equal join conjunct: (o_custkey[#10] = c_custkey[#0])
| runtime filters: RF000[bloom] <- c_custkey[#0] (150000000/134217728/16777216)
| cardinality=1,500,000,000
| vec output tuple id: 3
| output tuple id: 3
| vIntermediate tuple ids: 2
| hash output slot ids: 10
| final projections: o_custkey[#17]
| final project output tuple id: 3
| distribute expr lists: o_custkey[#10]
| distribute expr lists: c_custkey[#0]
|
|---1: VEXCHANGE
| offset: 0
| distribute expr lists: c_custkey[#0]
3: VEXCHANGE
| offset: 0
| distribute expr lists:
PLAN FRAGMENT 2
| PARTITION: HASH_PARTITIONED: o_orderkey[#8]
| HAS_COLO_PLAN_NODE: false
| STREAM DATA SINK
| EXCHANGE ID: 03
| HASH_PARTITIONED: o_custkey[#10]
2: VOlapScanNode(242)
| TABLE: regression_test_nereids_tpch_shape_sf1000_p0.orders(orders)
| PREAGGREGATION: ON
| runtime filters: RF000[bloom] -> o_custkey[#10]
| partitions=1/1 (orders)
| tablets=96/96, tabletList=54990,54992,54994 ...
| cardinality=0, avgRowSize=0.0, numNodes=1
| pushAggOp=NONE
Join 端:
runtime filters: RF000[bloom] <- c_custkey[#0] (150000000/134217728/16777216)这表示生成了一个 Bloom Filter,编号 000,它以
c_custkey字段作为输入生成 JRF。后面的三个数字和 Bloom Filter Size 计算相关,我们可以暂时忽略。Scan 端:
runtime filters: RF000[bloom] -> o_custkey[#10]这表示 000 号 JRF 将作用在 orders 表的 Scan 节点上,我们用 JRF 对
o_custkey字段进行过滤。
2. Explain Shape Plan
在 Explain Plan 系列中,我们以 Shape Plan 为例说明如何查看 JRF。
mysql> explain shape plan select count(*) from orders join customer on o_custkey=c_custkey where c_nationkey=5;
+--------------------------------------------------------------------------------------------------------------------------+
Explain String(Nereids Planner) |
+--------------------------------------------------------------------------------------------------------------------------+
PhysicalResultSink |
--hashAgg[GLOBAL] |
----PhysicalDistribute[DistributionSpecGather] |
------hashAgg[LOCAL] |
--------PhysicalProject |
----------hashJoin[INNER_JOIN shuffle] |
------------hashCondition=((orders.o_custkey=customer.c_custkey)) otherCondition=() buildRFs:RF0 c_custkey->[o_custkey] |
--------------PhysicalProject |
----------------Physical0lapScan[orders] apply RFs: RF0 |
--------------PhysicalProject |
----------------filter((customer.c_nationkey=5)) |
------------------Physical0lapScan[customer] |
+--------------------------------------------------------------------------------------------------------------------------+
11 rows in set (0.02 sec)
如上图所示:
- Join 端:
build RFs: RF0 c_custkey -> [o_custkey]表示我们以c_custkey列的数据作为输入,生成一个作用到o_custkey的 JRF,编号 0。 - scan 端:
PhysicalOlapScan[orders] apply RFs:RF0 表示 orders 表被 RF0 过滤。
3. Profile
在实际执行中,BE 会将 JRF 的使用情况输出到 Profile(需要 set enable_profile=true)。我们仍然以上面的 SQL 为例,在 Profile 中查看 JRF 执行的实际情况。
Join 端
HASH_JOIN_SINK_OPERATOR (id=3 , nereids_id=367):(ExecTime: 703.905us)
- JoinType: INNER_JOIN
。。。
- BuildRows: 617
。。。
- RuntimeFilterComputeTime: 70.741us
- RuntimeFilterInitTime: 10.882us这是 Join 的 Build 侧 Profile。在这个例子中,生成 JRF 耗时 70.741us,JRF 有 617 行数据作为输入。JRF 的 Size 和类型由 Scan 端展示。
Scan 端
OLAP_SCAN_OPERATOR (id=2. nereids_id=351. table name = orders(orders)):(ExecTime: 13.32ms)
- RuntimeFilters: : RuntimeFilter: (id = 0, type = bloomfilter, need_local_merge: false, is_broadcast: true, build_bf_cardinality: false,
。。。
- RuntimeFilterInfo:
- filter id = 0 filtered: 714.761K (714761)
- filter id = 0 input: 747.862K (747862)
。。。
- WaitForRuntimeFilter: 6.317ms
RuntimeFilter: (id = 0, type = bloomfilter):
- Info: [IsPushDown = true, RuntimeFilterState = READY, HasRemoteTarget = false, HasLocalTarget = true, Ignored = false]
- RealRuntimeFilterType: bloomfilter
- BloomFilterSize: 1024在这个部分,我们需要关注以下几点信息:
第 5/6 行,显示这个 JRF 的输入和过滤掉的行数。如果 Filtered 行数越大,那么这个 JRF 的效果越好。
第 10 行,
IsPushDown = true,表示 JRF 计算已经下推到存储层。如果下推到存储层,那么有利于存储层实现延迟物化,可以减少 IO。第 10 行,
RuntimeFilterState = READY,表示 Scan 节点是否应用了 JRF。因为 JRF 采用 Try-best 机制,如果 JRF 生成需要很长时间,那么 Scan 节点在等待一段时间后开始扫描数据,这样输出的数据可能没有经过 JRF 的过滤。第 12 行,
BloomFilterSize: 1024,这是一个 Bloom Filter,它的 size 是 1024 字节。
调优
关于 Join Runtime Filter 调优,在绝大多数情况下功能为自适应,用户不需要手动调优。
1. 开关 JRF
Session 变量 runtime_filter_mode 可以控制是否生成 JRF。
打开 JRF:
set runtime_filter_mode = GLOBAL关闭 JRF:
set runtime_filter_mode = OFF
2. 设定 JRF Type
Session 变量 runtime_filter_type 可以控制 JRF 的类型,包括:
IN(1)BLOOM(2)MIN_MAX(4)IN_OR_BLOOM(8)
IN_OR_BLOOM Filter 可以让 BE 根据实际数据行数自适应选择生成 IN Filter 还是 BLOOM Filter。
JRF type 可以叠加,即根据一个 Join 条件生成多个类型的 JRF。括号中的整数表示 Runtime Filter Type 的枚举值。如果希望生成多个 Type 的 JRF,那么将 runtime_filter_type 设置为对应枚举值之和。
例如,set runtime_filter_type = 6,那么将同时为每个 Join 条件生成 BLOOM Filter 和 MIN_MAX Filter。
再比如,在 2.1 版本中,runtime_filter_type 的默认值是 12,即同时生成 MIN_MAX Filter 和 IN_OR_BLOOMFilter。
3. 设定等待时间
前面提到 JRF 使用的是 Try-best 机制,Scan 节点启动前会等待 JRF。Doris 系统根据运行时状态计算等待时间。但在一些特殊情况下,可能等待时间不够,导致 JRF 没有生效,那么 Scan 节点的输出数据行数会比预期多。前面我们已经在 Profile 部分介绍了如何判断是否等到了 JRF。如果 Profile 中 Scan 节点 RuntimeFilterState = false,那么用户可以手动设置一个更长的等待时间。
Session 变量 runtime_filter_wait_time_ms 可以控制 Scan 节点等待 JRF 的时间。默认值是 1000 毫秒。
4. 裁剪 JRF
在某些情况下,JRF 可能没有过滤性。比如 orders 表和 customer 表存在主外键关系,但 customer 表上没有过滤条件,那么 JRF 的输入是全体 custkey,那么 orders 表中的所有行都能通过 JRF 过滤。优化器会根据列统计信息判断 JRF 的有效性进行裁剪。
Session 变量 enable_runtime_filter_prune = true/false 可以控制是否进行裁剪。默认值为 true。
TopN Runtime Filter
工作原理
在 Doris 中,数据是以分块流式的方式进行处理的。因此,当 SQL 语句中包含 topN 算子时,Doris 并不会计算所有结果,而是会生成一个动态的 Filter 来提前对数据进行过滤。
以下面 SQL 语句举例:
select o_orderkey from orders order by o_orderdate limit 5;
此 SQL 语句的执行计划如下图所示:
mysql> explain select o_orderkey from orders order by o_orderdate limit 5;
+-----------------------------------------------------+
| Explain String(Nereids Planner) |
+-----------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS: |
| o_orderkey[#11] |
| PARTITION: UNPARTITIONED |
| |
| HAS_COLO_PLAN_NODE: false |
| |
| VRESULT SINK |
| MYSQL_PROTOCAL |
| |
| 2:VMERGING-EXCHANGE |
| offset: 0 |
| limit: 5 |
| final projections: o_orderkey[#9] |
| final project output tuple id: 2 |
| distribute expr lists: |
| |
| PLAN FRAGMENT 1 |
| |
| PARTITION: HASH_PARTITIONED: O_ORDERKEY[#0] |
| |
| HAS_COLO_PLAN_NODE: false |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 02 |
| UNPARTITIONED |
| |
| 1:VTOP-N(119) |
| | order by: o_orderdate[#10] ASC |
| | TOPN OPT |
| | offset: 0 |
| | limit: 5 |
| | distribute expr lists: O_ORDERKEY[#0] |
| | |
| 0:VOlapScanNode(113) |
| TABLE: tpch.orders(orders), PREAGGREGATION: ON |
| TOPN OPT:1 |
| partitions=1/1 (orders) |
| tablets=3/3, tabletList=135112,135114,135116 |
| cardinality=150000, avgRowSize=0.0, numNodes=1 |
| pushAggOp=NONE |
+-----------------------------------------------------+
41 rows in set (0.06 sec)
在没有 topn filter 的情况下,scan 节点会依次读入 orders 表的每个数据块,并将这些数据块传递给 TopN 节点。TopN 节点通过堆排序维护着当前已扫描数据 orders 表中排名前 5 行。
由于一个数据 Block 大约包含 1024 行数据,因此在 TopN 处理了第一个数据块后,就能找到该数据块中排名第 5 的行。
假设这个 o_orderdate 是 1995-01-01,那么 scan 节点在输出第二个数据块时,就可以使用 1995-01-01 作为过滤条件,o_orderdate 大于 1995-01-01 的行则不需要再发送给 TopN 节点进行计算。
这个阈值会进行动态更新,例如,TopN 在处理第二个经过此阈值过滤的数据块时,如果发现了更小的 o_orderdate,那么 TopN 会将阈值更新为第一个和第二个数据块中排名第 5 的 o_orderdate。
查看 TopN Runtime Filter
通过 Explain 命令,我们可以查看优化器规划的 TopN runtime filter。
1:VTOP-N(119)
| order by: o_orderdate[#10] ASC
| TOPN OPT
| offset: 0
| limit: 5
| distribute expr lists: O_ORDERKEY[#0]
|
0:VLapScanNode[113]
TABLE: regression_test_nereids_tpch_p0.(orders), PREAGGREGATION: ON
TOPN OPT: 1
partitions=1/1 (orders)
tablets=3/3, tabletList=135112,135114,135116
cardinality=150000, avgRowSize=0.0, numNodes=1
pushAggOp: NONE
如上述例子所示:
TopN 节点上会显示
TOPN OPT,表示这个 TopN 节点会产生一个 TopN Runtime Filter。Scan 节点上会标注它使用的 TopN Runtime Filter 是由哪个 TopN 节点产生的。比如,例子中 11 行,表示
orders表的 Scan 节点将使用编号为 1 的 TopN 节点生成的 Runtime Filter,因此在 Plan 中显示为TOPN OPT: 1。
作为一个分布式数据库,Doris 还需要考虑 TopN 节点和 Scan 节点实际运行的物理机器。因为跨 BE 通信的代价比较高,所以 BE 会自适应地决定是否使用 TopN Runtime Filter,以及使用的范围。当前,我们实现了 BE 级别的 TopN Runtime Filter,即 TopN 和 Scan 在同一个 BE 里。这是因为 TopN Runtime Filter 阈值的更新只需要线程间通信,代价比较低。
调优
Session 变量 topn_opt_limit_threshold 可以控制是否生成 TopN Runtime Filter。
如果 SQL 中 limit 的数量越少,那么 TopN Runtime Filter 的过滤性就越强。因此,系统默认情况下,只有在 limit 数量小于 1024 时,才会启用生成对应的 TopN Runtime Filter。
例如,如果设置 set topn_opt_limit_threshold=10,那么执行以下查询就不会生成 TopN Runtime Filter。
select o_orderkey from orders order by o_orderdate limit 20;
