连接(JOIN)
什么是 JOIN
在关系型数据库中,数据被分布在多个表中,这些表之间通过特定关系相互关联。SQL JOIN 操作允许我们根据这些关联条件将不同的表合并成一个更完整的结果集。
Doris 支持的 JOIN 类型
INNER JOIN(内连接):对左表每一行和右表所有行进行 JOIN 条件比较,返回两个表中满足 JOIN 条件的匹配行。详细信息请参考 SELECT 中有关于联接查询的语法定义
LEFT JOIN(左连接):在 INNER JOIN 的结果集基础上。如果左表的行在右表中没有匹配,则返回左表的所有行,同时右表对应的列显示为 NULL。
RIGHT JOIN(右连接):与 LEFT JOIN 相反,如果右表的行在左表中没有匹配,则返回右表的所有行,同时左表对应的列显示为 NULL。
FULL JOIN(全连接):在 INNER JOIN 的结果集基础上。返回两个表中所有的行,如果某行在另一侧表中没有
CROSS JOIN(交叉连接):没有 JOIN 条件,返回两个表的笛卡尔积,即左表的每一行与右表的每一行都进行组合。
LEFT SEMI JOIN(左半连接):对左表每一行和右表所有行进行 JOIN 条件比较,如果存在匹配,就返回左表的对应行。
RIGHT SEMI JOIN(右半连接):与 LEFT SEMI JOIN 相反,对右表每一行和左表所有行进行 JOIN 条件比较,如果存在匹配,就返回右表的对应行。
LEFT ANTI JOIN(左反半连接):对左表每一行和右表所有行进行 JOIN 条件比较,如果没有匹配,则返回左表的对应行。
RIGHT ANTI JOIN(右反半连接):与 LEFT ANTI JOIN 相反,对右表每一行和左表所有行进行 JOIN 条件比较,如果没有匹配,则返回这些行。
NULL AWARE LEFT ANTI JOIN (对 NULL 值特殊处理的左反半连接):与 LEFT ANTI JOIN 类似,但忽略左表中匹配列为 NULL 的行。
Doris 中的 JOIN 物理实现
Doris 支持两种 JOIN 的物理实现方式:Hash Join 和 Nest Loop Join。
Hash Join: 在右表上根据等值 JOIN 列构建一个哈希表,左表的数据以流式方式通过该哈希表进行 JOIN 计算。这种方法的局限性在于它仅适用于等值 JOIN 条件的情况。
Nest Loop Join: 通过两层循环,以左表驱动,对左表的每一行逐一遍历右表的每一行,进行 join 条件判断。适用于所有 JOIN 场景,包括处理 Hash Join 无法胜任的情况,比如涉及大于或小于比较条件的查询,或是需要执行笛卡尔积运算的场景。但相比 Hash Join,Nest Loop Join 在性能上可能会有所不及。
Doris Hash Join 的实现方式
作为分布式 MPP 数据库,Apache Doris 在 Hash Join 过程中需要进行数据的 Shuffle,进行拆分调度,以确保 JOIN 结果的正确性。以下是几种数据 Shuffle 方式:
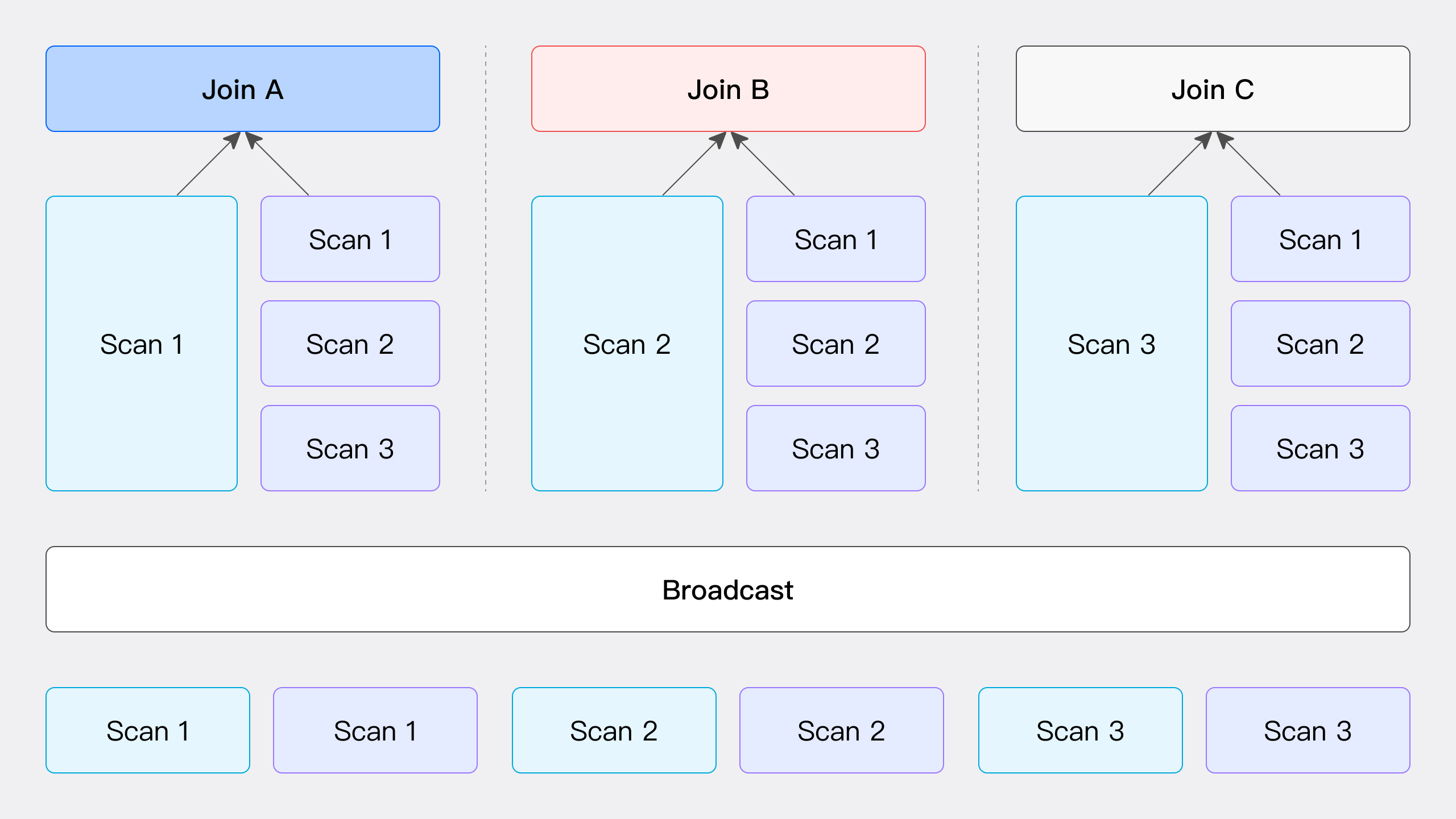
Broadcast Join
如图所示,Broadcast Join 的过程涉及将右表的所有数据发送到所有参与 Join 计算的节点,包括左表数据的扫描节点,而左表数据则保持不动。这一过程中,每个节点都会接收到右表的完整数据副本(总量为 T(R) 的数据),以确保所有节点都具备执行 Join 操作所需的数据。
该方法适用于多种通用场景,但不适用于 RIGHT OUTER, RIGHT ANTI, 和 RIGHT SEMI 类型的 Hash Join。其网络开销为 Join 的节点数 N 乘以右表数据量 T(R)。
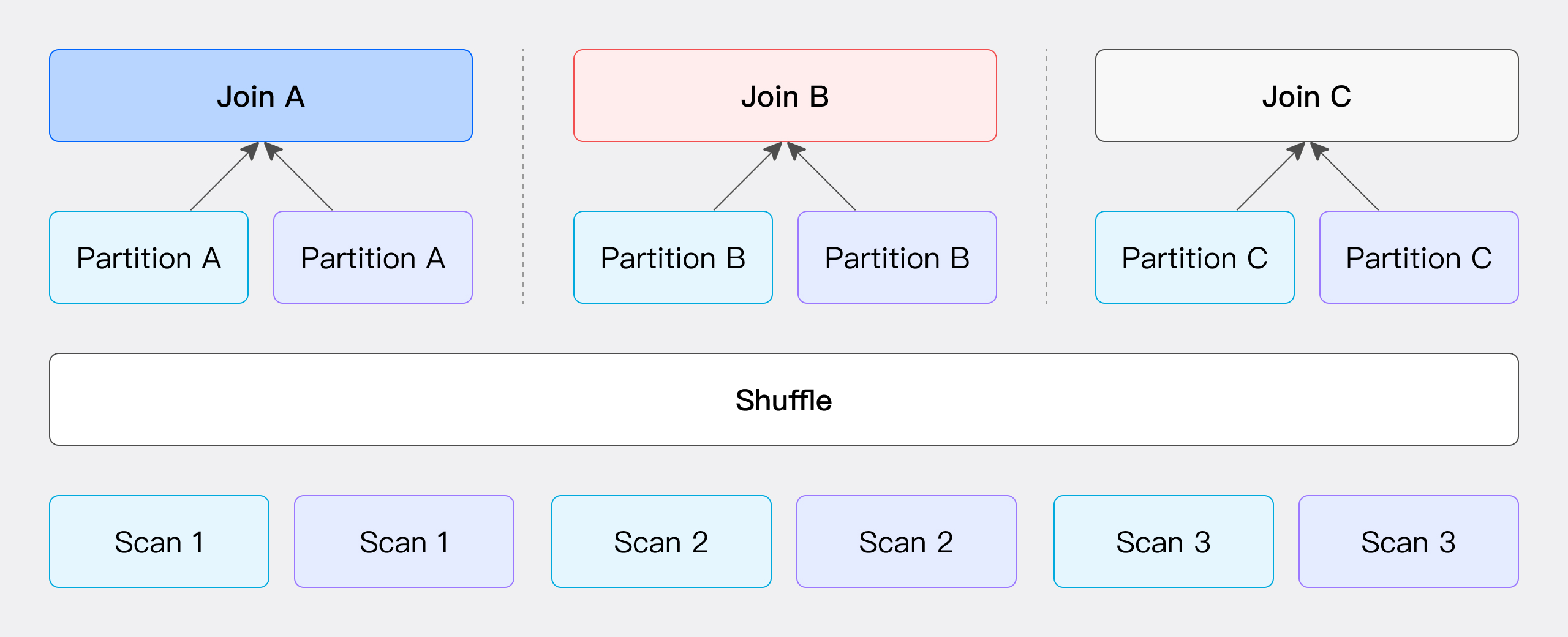
Partition Shuffle Join
此方式通过 JOIN 条件计算 Hash 值并进行分桶。具体来说,左右表的数据会根据 JOIN 条件计算得到的 Hash 值进行分区,然后这些分区数据被发送到相应的分区节点上(如图所示)。
该方法的网络开销主要包括两个部分:传输左表数据 T(S) 所需的开销和传输右表数据 T(R) 所需的开销。该方法的仅支持 Hash Join 操作,因为它依赖于 JOIN 条件来执行数据的分桶操作。
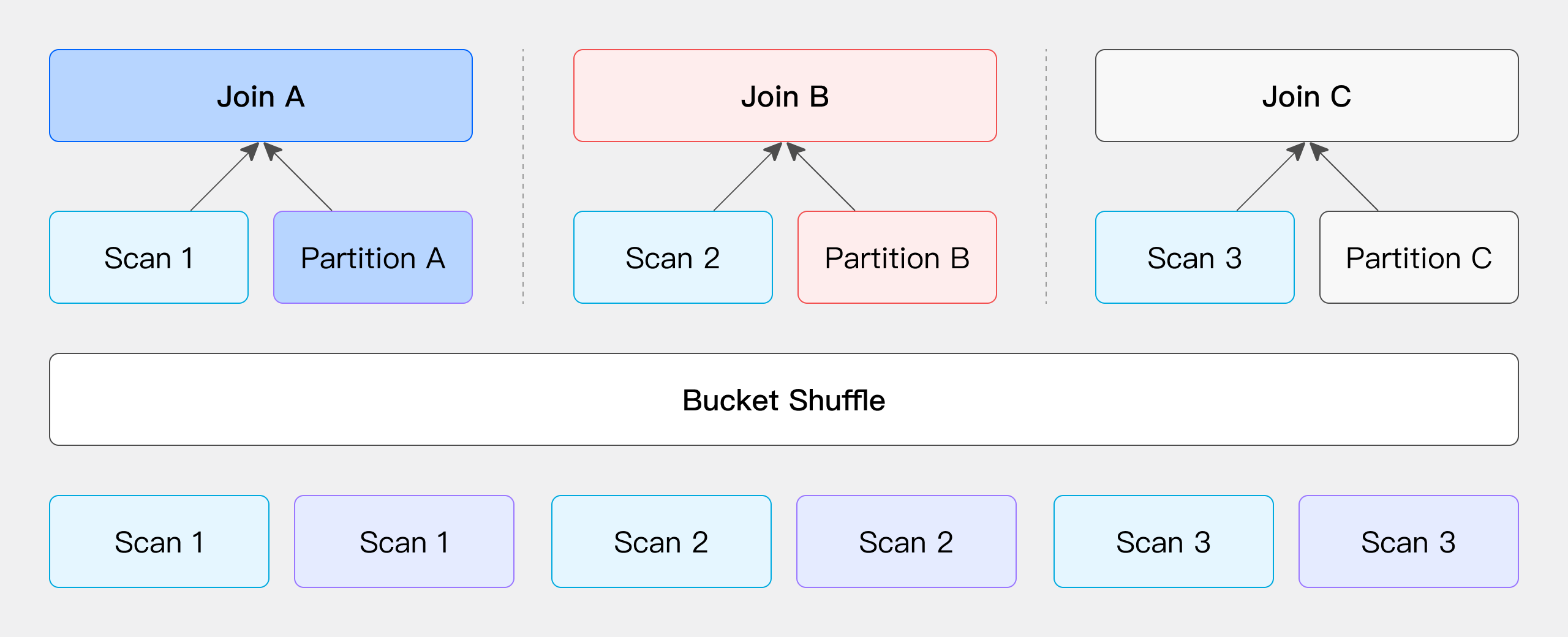
Bucket Shuffle Join
当 JOIN 条件包含左表的分桶列时,保持左表数据不动,将右表数据分发到左表节点进行 JOIN,减少网络开销。
当参与 Join 操作的某一侧表的数据已经按照 Join 条件列进行了 Hash 分布时,我们可以选择保持这一侧的数据位置不变,而将另一侧的数据依据相同的 Join 条件列,相同的 Hash 分布计算进行数据分发。(这里提到的“表”不仅限于物理存储的表,还可以是 SQL 查询中任意算子的输出结果,并且可以灵活选择保持左表或右表的数据位置不变,而只移动并分发另一侧的表。)
以 Doris 的物理表为例,由于其表数据本身就是通过 Hash 计算进行分桶存储,因此可以直接利用这一特性来优化 Join 操作的数据 Shuffle 过程。假设我们有两张表需要进行 Join,且 Join 列是左表的分桶列,那么在这种情况下,我们无需移动左表的数据,只需根据左表的分桶信息将右表的数据分发到相应的位置,即可完成 Join 计算(如图所示)。
此过程的网络开销主要来自于右表数据的移动,即 T(R)。
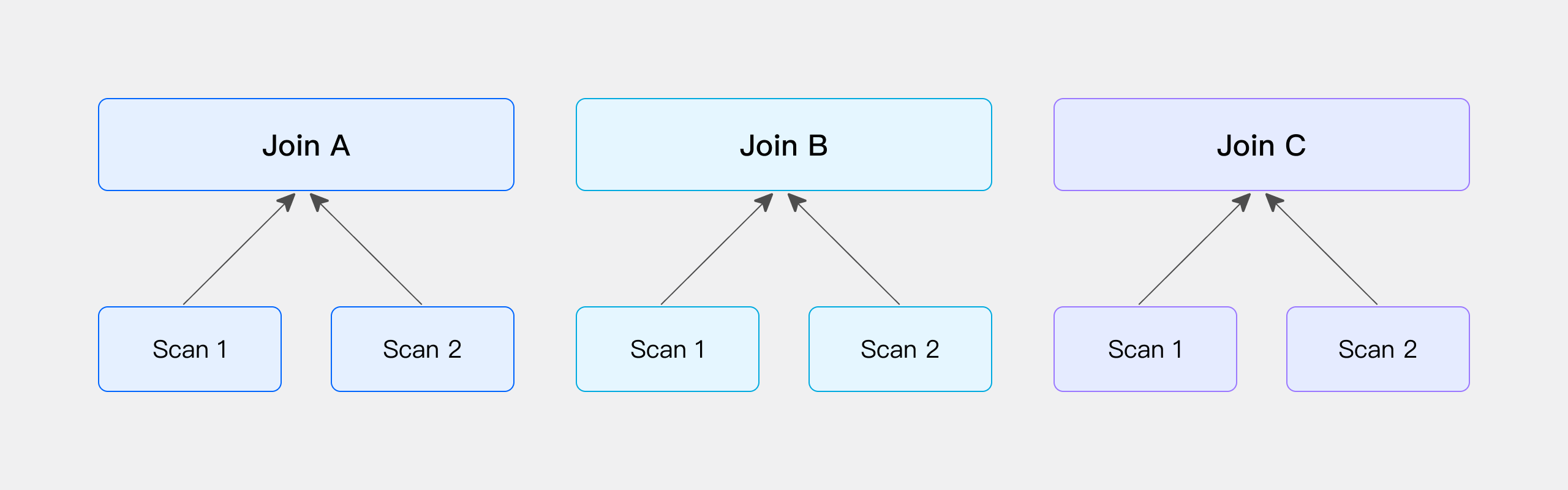
Colocate Join
与 Bucket Shuffle Join 相似,如果参与 Join 的两侧的表,刚好是按照 Join 条件列进行计算的 Hash 分布,那么可以跳过 Shuffle 过程,直接在本地进行 Join 计算。以下通过物理表进行简单说明:
当 Doris 在建表时指定为 DISTRIBUTED BY HASH,那么在数据导入时,系统会根据 Hash 分布键进行数据分发。如果两张表的 Hash 分布键恰好与 Join 条件列一致,那么可以认为这两张表的数据已经按照 Join 的需求进行了预分布,即无需额外的 Shuffle 操作。因此,在实际查询时,可以直接在这两张表上执行 Join 计算。
对于直接 Scan 数据后执行 Join 的场景,建表时需要满足一定的条件,具体请参考后续关于两张物理表进行 Colocate Join 的限制说明。
对比 Bucket Shuffle Join 与 Colocate Join
上文我们提到过,对于 Bucket Shuffle Join 和 Colocate Join 只要参与 Join 操作的两侧的表分布满足特定条件,就可以执行相应的 join 操作(这里的表指的是更广义的表,即 SQL 查询中任意算子的输出都可以视为一张“表”)。
接下来,我们将分别通过 t1 和 t2 两张表以及相关的 SQL 示例,来更详细地介绍广义上的 Bucket Shuffle Join 和 Colocate Join。首先,给出这两张表的建表语句如下:
create table t1
(
c1 bigint,
c2 bigint
)
DISTRIBUTED BY HASH(c1) BUCKETS 3
PROPERTIES ("replication_num" = "1");
create table t2
(
c1 bigint,
c2 bigint
)
DISTRIBUTED BY HASH(c1) BUCKETS 3
PROPERTIES ("replication_num" = "1");
Bucket Shuffle Join 示例
在下面的例子中,t1 和 t2 表都经过了 GROUP BY 算子处理,并输出了新的表(此时 tx 表按照 c1 进行 hash 分布,而 ty 表则按照 c2 进行 Hash 分布)。随后的 JOIN 条件是 tx.c1 = ty.c2,这恰好满足了 Bucket Shuffle Join 的条件。
explain select *
from
(
-- t1 表按照 c1 做了 hash 分布,经过 group by 算子后,仍然保持按照 c1 做的 hash 分布
select c1 as c1, sum(c2) as c2
from t1
group by c1
) tx
join
(
-- t2 表按照 c1 做了 hash 分布,经过 group by 算子后,数据分布变成按照 c2 进行的 hash 分布
select c2 as c2, sum(c1) as c1
from t2
group by c2
) ty
on tx.c1 = ty.c2;
从下面的 Explain 执行计划中,我们可以观察到,7 号 Hash Join 节点的左侧子节点是 6 号聚合节点,而右侧子节点是 4 号 Exchange 节点。这表示左侧子节点聚合后的数据位置保持不变,而右侧子节点的数据则会根据 Bucket Shuffle 的方式被分发到左侧子节点所在的节点上,以便进行后续的 Hash Join 操作。
+------------------------------------------------------------+
| Explain String(Nereids Planner) |
+------------------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS: |
| c1[#18] |
| c2[#19] |
| c2[#20] |
| c1[#21] |
| PARTITION: HASH_PARTITIONED: c1[#8] |
| |
| HAS_COLO_PLAN_NODE: true |
| |
| VRESULT SINK |
| MYSQL_PROTOCAL |
| |
| 7:VHASH JOIN(364) |
| | join op: INNER JOIN(BUCKET_SHUFFLE)[] |
| | equal join conjunct: (c1[#12] = c2[#6]) |
| | cardinality=10 |
| | vec output tuple id: 8 |
| | output tuple id: 8 |
| | vIntermediate tuple ids: 7 |
| | hash output slot ids: 6 7 12 13 |
| | final projections: c1[#14], c2[#15], c2[#16], c1[#17] |
| | final project output tuple id: 8 |
| | distribute expr lists: c1[#12] |
| | distribute expr lists: c2[#6] |
| | |
| |----4:VEXCHANGE |
| | offset: 0 |
| | distribute expr lists: c2[#6] |
| | |
| 6:VAGGREGATE (update finalize)(342) |
| | output: sum(c2[#9])[#11] |
| | group by: c1[#8] |
| | sortByGroupKey:false |
| | cardinality=10 |
| | final projections: c1[#10], c2[#11] |
| | final project output tuple id: 6 |
| | distribute expr lists: c1[#8] |
| | |
| 5:VOlapScanNode(339) |
| TABLE: tt.t1(t1), PREAGGREGATION: ON |
| partitions=1/1 (t1) |
| tablets=1/1, tabletList=491188 |
| cardinality=21, avgRowSize=0.0, numNodes=1 |
| pushAggOp=NONE |
| |
| PLAN FRAGMENT 1 |
| |
| PARTITION: HASH_PARTITIONED: c2[#2] |
| |
| HAS_COLO_PLAN_NODE: true |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 04 |
| BUCKET_SHFFULE_HASH_PARTITIONED: c2[#6] |
| |
| 3:VAGGREGATE (merge finalize)(355) |
| | output: sum(partial_sum(c1)[#3])[#5] |
| | group by: c2[#2] |
| | sortByGroupKey:false |
| | cardinality=5 |
| | final projections: c2[#4], c1[#5] |
| | final project output tuple id: 3 |
| | distribute expr lists: c2[#2] |
| | |
| 2:VEXCHANGE |
| offset: 0 |
| distribute expr lists: |
| |
| PLAN FRAGMENT 2 |
| |
| PARTITION: HASH_PARTITIONED: c1[#0] |
| |
| HAS_COLO_PLAN_NODE: false |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 02 |
| HASH_PARTITIONED: c2[#2] |
| |
| 1:VAGGREGATE (update serialize)(349) |
| | STREAMING |
| | output: partial_sum(c1[#0])[#3] |
| | group by: c2[#1] |
| | sortByGroupKey:false |
| | cardinality=5 |
| | distribute expr lists: c1[#0] |
| | |
| 0:VOlapScanNode(346) |
| TABLE: tt.t2(t2), PREAGGREGATION: ON |
| partitions=1/1 (t2) |
| tablets=1/1, tabletList=491198 |
| cardinality=10, avgRowSize=0.0, numNodes=1 |
| pushAggOp=NONE |
| |
| |
| Statistics |
| planed with unknown column statistics |
+------------------------------------------------------------+
97 rows in set (0.01 sec)
Colocate Join 示例
在下面的例子中,t1 和 t2 表都通过 GROUP BY 算子进行了处理,并输出了新的表(此时 tx 和 ty 均按照 c2 进行了 Hash 分布)。随后的 JOIN 条件是 tx.c2 = ty.c2,这恰好满足了 Colocate Join 的条件。
explain select *
from
(
-- t1 表按照 c1 做了 hash 分布,经过 group by 算子后,数据分布变成按照 c2 进行的 hash 分布
select c2 as c2, sum(c1) as c1
from t1
group by c2
) tx
join
(
-- t2 表按照 c1 做了 hash 分布,经过 group by 算子后,数据分布变成按照 c2 进行的 hash 分布
select c2 as c2, sum(c1) as c1
from t2
group by c2
) ty
on tx.c2 = ty.c2;
从下面的 Explain 执行计划结果中可以看出,8 号 Hash Join 节点的左侧子节点是 7 号聚合节点,右侧子节点是 3 号聚合节点,并且没有出现 Exchange 节点。这表明左侧和右侧子节点聚合后的数据都保持在其原始位置不动,无需进行数据移动,可以直接在本地进行后续的 Hash Join 操作。
+------------------------------------------------------------+
| Explain String(Nereids Planner) |
+------------------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS: |
| c2[#20] |
| c1[#21] |
| c2[#22] |
| c1[#23] |
| PARTITION: HASH_PARTITIONED: c2[#10] |
| |
| HAS_COLO_PLAN_NODE: true |
| |
| VRESULT SINK |
| MYSQL_PROTOCAL |
| |
| 8:VHASH JOIN(373) |
| | join op: INNER JOIN(PARTITIONED)[] |
| | equal join conjunct: (c2[#14] = c2[#6]) |
| | cardinality=10 |
| | vec output tuple id: 9 |
| | output tuple id: 9 |
| | vIntermediate tuple ids: 8 |
| | hash output slot ids: 6 7 14 15 |
| | final projections: c2[#16], c1[#17], c2[#18], c1[#19] |
| | final project output tuple id: 9 |
| | distribute expr lists: c2[#14] |
| | distribute expr lists: c2[#6] |
| | |
| |----3:VAGGREGATE (merge finalize)(367) |
| | | output: sum(partial_sum(c1)[#3])[#5] |
| | | group by: c2[#2] |
| | | sortByGroupKey:false |
| | | cardinality=5 |
| | | final projections: c2[#4], c1[#5] |
| | | final project output tuple id: 3 |
| | | distribute expr lists: c2[#2] |
| | | |
| | 2:VEXCHANGE |
| | offset: 0 |
| | distribute expr lists: |
| | |
| 7:VAGGREGATE (merge finalize)(354) |
| | output: sum(partial_sum(c1)[#11])[#13] |
| | group by: c2[#10] |
| | sortByGroupKey:false |
| | cardinality=10 |
| | final projections: c2[#12], c1[#13] |
| | final project output tuple id: 7 |
| | distribute expr lists: c2[#10] |
| | |
| 6:VEXCHANGE |
| offset: 0 |
| distribute expr lists: |
| |
| PLAN FRAGMENT 1 |
| |
| PARTITION: HASH_PARTITIONED: c1[#8] |
| |
| HAS_COLO_PLAN_NODE: false |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 06 |
| HASH_PARTITIONED: c2[#10] |
| |
| 5:VAGGREGATE (update serialize)(348) |
| | STREAMING |
| | output: partial_sum(c1[#8])[#11] |
| | group by: c2[#9] |
| | sortByGroupKey:false |
| | cardinality=10 |
| | distribute expr lists: c1[#8] |
| | |
| 4:VOlapScanNode(345) |
| TABLE: tt.t1(t1), PREAGGREGATION: ON |
| partitions=1/1 (t1) |
| tablets=1/1, tabletList=491188 |
| cardinality=21, avgRowSize=0.0, numNodes=1 |
| pushAggOp=NONE |
| |
| PLAN FRAGMENT 2 |
| |
| PARTITION: HASH_PARTITIONED: c1[#0] |
| |
| HAS_COLO_PLAN_NODE: false |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 02 |
| HASH_PARTITIONED: c2[#2] |
| |
| 1:VAGGREGATE (update serialize)(361) |
| | STREAMING |
| | output: partial_sum(c1[#0])[#3] |
| | group by: c2[#1] |
| | sortByGroupKey:false |
| | cardinality=5 |
| | distribute expr lists: c1[#0] |
| | |
| 0:VOlapScanNode(358) |
| TABLE: tt.t2(t2), PREAGGREGATION: ON |
| partitions=1/1 (t2) |
| tablets=1/1, tabletList=491198 |
| cardinality=10, avgRowSize=0.0, numNodes=1 |
| pushAggOp=NONE |
| |
| |
| Statistics |
| planed with unknown column statistics |
+------------------------------------------------------------+
105 rows in set (0.06 sec)
四种 Shuffle 方式对比
| Shuffle 方式 | 网络开销 | 物理算子 | 适用场景 |
|---|---|---|---|
| Broadcast | N * T(R) | Hash Join /Nest Loop Join | 通用 |
| Shuffle | T(S) + T(R) | Hash Join | 通用 |
| Bucket Shuffle | T(R) | Hash Join | JOIN 条件含左表分桶列,左表单分区 |
| Colocate | 0 | Hash Join | JOIN 条件含左表分桶列,且两表属同一 Colocate Group |
N:参与 Join 计算的 Instance 个数
T(关系) : 关系的 Tuple 数目
上述四种 Shuffle 方式的灵活性依次递减,它们对数据分布的要求也愈发严格。在多数场景下,随着对数据分布要求的提高,Join 计算的性能往往也会逐步提升。值得注意的是,如果表的 Bucket 数量较少,Bucket Shuffle 或 Colocate Join 可能会因为并行度较低而导致性能下降,甚至可能慢于 Shuffle Join。这是因为 Shuffle 操作能更有效地均衡数据的分布,从而在后续处理中提供更高的并行度。
常见问题
Bucket Shuffle Join 和 Colocate Join 在应用时对数据分布和 JOIN 条件具有一定限制条件。下面,我们将详细阐述这两种 JOIN 方式各自的具体限制。
Bucket Shuffle Join 的限制
在直接扫描两张物理表以进行 Bucket Shuffle Join 时,需要满足以下条件:
等值 Join 条件:Bucket Shuffle Join 仅适用于 Join 条件为等值的场景,因为它依赖于 Hash 计算来确定数据分布。
包含分桶列的等值条件:等值 Join 条件中须包含两张表的分桶列,当左表的分桶列作为等值 Join 条件时,更有可能被规划为 Bucket Shuffle Join。
数据类型一致性:由于不同的数据类型的 hash 值计算结果不同,左表的分桶列与右表的等值 Join 列的数据类型必须一致,否则将无法进行对应的规划。
表类型限制:Bucket Shuffle Join 仅适用于 Doris 原生的 OLAP 表。对于 ODBC、MySQL、ES 等外部表,当它们作为左表时,Bucket Shuffle Join 无法生效。
单分区要求:对于分区表,由于每个分区的数据分布可能不同,Bucket Shuffle Join 仅在左表为单分区时保证有效。因此在执行 SQL 时,应尽可能使用
WHERE条件来启用分区裁剪策略。
Colocate Join 的限制
在直接扫描两张物理表时,Colocate Join 相较于 Bucket Shuffle Join 具有更严格的限制条件,除了满足 Bucket Shuffle Join 的所有条件外,还需满足以下要求:
不仅分桶列的类型必须一致,分桶的数量也必须相同,以确保数据分布的一致性。
表的副本数必须保持一致。
需要显式指定 Colocation Group,只有处于相同 Colocation Group 的表才能进行 Colocate Join。
在进行副本修复或副本均衡等操作时,Colocation Group 可能处于 Unstable 状态,此时 Colocate Join 将退化为普通的 Join 操作。
