原理介绍
异步物化视图构建
物化视图创建分区有两种方式:自定义分区和依赖基表的分区自动创建分区
自定义分区
创建物化视图时,如果不指定分区信息,物化视图将默认创建一个分区,所有数据都存放在这个分区中。
依赖基表进行分区
物化视图可以通过多个基表 JOIN 关联创建,并可以选择追随其中一个基表进行分区(建议选择事实表)。
例如,基表t1和t2的建表语句分别如下:
CREATE TABLE `t1` (
`user_id` LARGEINT NOT NULL,
`o_date` DATE NOT NULL,
`num` SMALLINT NOT NULL
) ENGINE=OLAP
COMMENT 'OLAP'
PARTITION BY RANGE(`o_date`)
(
PARTITION p20170101 VALUES [('2017-01-01'), ('2017-01-02')),
PARTITION p20170102 VALUES [('2017-01-02'), ('2017-01-03')),
PARTITION p20170201 VALUES [('2017-02-01'), ('2017-02-02'))
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 2
PROPERTIES ('replication_num' = '1') ;
CREATE TABLE `t2` (
`user_id` LARGEINT NOT NULL,
`age` SMALLINT NOT NULL
) ENGINE=OLAP
PARTITION BY LIST(`age`)
(
PARTITION `p1` VALUES IN ('1'),
PARTITION `p2` VALUES IN ('2')
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 2
PROPERTIES ('replication_num' = '1') ;
若物化视图的建表语句如下:
CREATE MATERIALIZED VIEW mv1
BUILD DEFERRED REFRESH AUTO ON MANUAL
partition by(`order_date`)
DISTRIBUTED BY RANDOM BUCKETS 2
PROPERTIES (
'replication_num' = '1'
)
AS
SELECT t1.o_date as order_date, t1.user_id as user_id, t1.num, t2.age FROM t1 join t2 on t1.user_id=t2.user_id;
那么物化视图mv1将和t1一样,有三个分区:
[('2017-01-01'), ('2017-01-02'))[('2017-01-02'), ('2017-01-03'))[('2017-02-01'), ('2017-02-02'))
若物化视图的建表语句如下:
CREATE MATERIALIZED VIEW mv2
BUILD DEFERRED REFRESH AUTO ON MANUAL
partition by(`age`)
DISTRIBUTED BY RANDOM BUCKETS 2
PROPERTIES (
'replication_num' = '1'
)
AS
SELECT t1.o_date as order_date, t1.user_id as user_id, t1.num, t2.age FROM t1 join t2 on t1.user_id=t2.user_id;
那么物化视图mv2将和t2一样,有两个分区:
('1')('2')
在依赖基表分区创建物化视图时,不同场景需要合理设计不同的分区策略,下面将举例说明多列分区、部分分区与分区上卷三种情况。
1. 基表有多列分区
自 Doris 2.1.0 版本起支持多列分区
目前仅支持 Hive 外表有多列分区。Hive 外表有很多多级分区的情况,例如一级分区按照日期,二级分区按照区域。物化视图可以选择 Hive 的某一级分区列作为物化视图的分区列。
例如,Hive 的建表语句如下:
CREATE TABLE hive1 (
`k1` int)
PARTITIONED BY (
`year` int,
`region` string)
STORED AS ORC;
alter table hive1 add if not exists
partition(year=2020,region="bj")
partition(year=2020,region="sh")
partition(year=2021,region="bj")
partition(year=2021,region="sh")
partition(year=2022,region="bj")
partition(year=2022,region="sh")
当物化视图的创建语句如下时,物化视图mv_hive将有三个分区:('2020'),('2021'),('2022')
CREATE MATERIALIZED VIEW mv_hive
BUILD DEFERRED REFRESH AUTO ON MANUAL
partition by(`year`)
DISTRIBUTED BY RANDOM BUCKETS 2
PROPERTIES ('replication_num' = '1')
AS
SELECT k1,year,region FROM hive1;
当物化视图的建表语句如下时,那么物化视图mv_hive2将有如下两个分区:('bj'),('sh'):
CREATE MATERIALIZED VIEW mv_hive2
BUILD DEFERRED REFRESH AUTO ON MANUAL
partition by(`region`)
DISTRIBUTED BY RANDOM BUCKETS 2
PROPERTIES ('replication_num' = '1')
AS
SELECT k1,year,region FROM hive1;
2. 仅使用基表部分分区
自 Doris 2.1.1 版本起支持此功能
有些基表有很多分区,但是物化视图只关注最近一段时间的“热”数据,那么可以使用此功能。
基表的建表语句如下:
CREATE TABLE t1 (
`k1` INT,
`k2` DATE NOT NULL
) ENGINE=OLAP
DUPLICATE KEY(`k1`)
COMMENT 'OLAP'
PARTITION BY range(`k2`)
(
PARTITION p26 VALUES [("2024-03-26"),("2024-03-27")),
PARTITION p27 VALUES [("2024-03-27"),("2024-03-28")),
PARTITION p28 VALUES [("2024-03-28"),("2024-03-29"))
)
DISTRIBUTED BY HASH(`k1`) BUCKETS 2
PROPERTIES (
'replication_num' = '1'
);
物化视图的创建语句如以下举例,代表物化视图只关注最近一天的数据。若当前时间为 2024-03-28 xx:xx:xx,这样物化视图会仅有一个分区 [("2024-03-28"),("2024-03-29")]:
CREATE MATERIALIZED VIEW mv1
BUILD DEFERRED REFRESH AUTO ON MANUAL
partition by(`k2`)
DISTRIBUTED BY RANDOM BUCKETS 2
PROPERTIES (
'replication_num' = '1',
'partition_sync_limit'='1',
'partition_sync_time_unit'='DAY'
)
AS
SELECT * FROM t1;
若时间又过了一天,当前时间为 2024-03-29 xx:xx:xx,t1则会新增一个分区 [("2024-03-29"),("2024-03-30")],若此时刷新物化视图,刷新完成后,物化视图会仅有一个分区 [("2024-03-29"),("2024-03-30")]。
此外,分区字段是字符串类型时,可以设置物化视图属性 partition_date_format,例如 %Y-%m-%d 。
3. 分区上卷
自 Doris 2.1.5 版本起支持此功能
当基表数据经过聚合处理后,各分区的数据量可能会显著减少。在这种情况下,可以采用分区上卷策略,以降低物化视图的分区数量。
List 分区
需要注意的是,Hive 中的分区对应于 Doris 中的 list 分区。
假设基表的建表语句如下:
CREATE TABLE `t1` (
`k1` INT NOT NULL,
`k2` DATE NOT NULL
) ENGINE=OLAP
DUPLICATE KEY(`k1`)
COMMENT 'OLAP'
PARTITION BY list(`k2`)
(
PARTITION p_20200101 VALUES IN ("2020-01-01"),
PARTITION p_20200102 VALUES IN ("2020-01-02"),
PARTITION p_20200201 VALUES IN ("2020-02-01")
)
DISTRIBUTED BY HASH(`k1`) BUCKETS 2
PROPERTIES ('replication_num' = '1') ;若物化视图的创建语句如下,则该物化视图将包含两个分区:
("2020-01-01","2020-01-02")和("2020-02-01")CREATE MATERIALIZED VIEW mv1
BUILD DEFERRED REFRESH AUTO ON MANUAL
partition by (date_trunc(`k2`,'month'))
DISTRIBUTED BY RANDOM BUCKETS 2
PROPERTIES (
'replication_num' = '1'
)
AS
SELECT * FROM t1;若物化视图的创建语句如下,则该物化视图将只包含一个分区:
("2020-01-01","2020-01-02","2020-02-01")CREATE MATERIALIZED VIEW mv1
BUILD DEFERRED REFRESH AUTO ON MANUAL
partition by (date_trunc(`k2`,'year'))
DISTRIBUTED BY RANDOM BUCKETS 2
PROPERTIES (
'replication_num' = '1'
)
AS
SELECT * FROM t1;Range 分区
假设基表的建表语句如下:
CREATE TABLE `t1` (
`k1` LARGEINT NOT NULL,
`k2` DATE NOT NULL
) ENGINE=OLAP
DUPLICATE KEY(`k1`)
COMMENT 'OLAP'
PARTITION BY range(`k2`)
(
PARTITION p_20200101 VALUES [("2020-01-01"),("2020-01-02")),
PARTITION p_20200102 VALUES [("2020-01-02"),("2020-01-03")),
PARTITION p_20200201 VALUES [("2020-02-01"),("2020-02-02"))
)
DISTRIBUTED BY HASH(`k1`) BUCKETS 2
PROPERTIES ('replication_num' = '1') ;若物化视图的创建语句如下,则该物化视图将包含两个分区:
[("2020-01-01","2020-02-01")]和[("2020-02-01","2020-03-01")]CREATE MATERIALIZED VIEW mv1
BUILD DEFERRED REFRESH AUTO ON MANUAL
partition by (date_trunc(`k2`,'month'))
DISTRIBUTED BY RANDOM BUCKETS 2
PROPERTIES (
'replication_num' = '1'
)
AS
SELECT * FROM t1;若物化视图的创建语句如下,则该物化视图将只包含一个分区:
[("2020-01-01","2021-01-01")]CREATE MATERIALIZED VIEW mv1
BUILD DEFERRED REFRESH AUTO ON MANUAL
partition by (date_trunc(`k2`,'year'))
DISTRIBUTED BY RANDOM BUCKETS 2
PROPERTIES (
'replication_num' = '1'
)
AS
SELECT * FROM t1;此外,如果分区字段为字符串类型,可以通过设置物化视图的
partition_date_format属性来指定日期格式,例如'%Y-%m-%d'。
异步物化视图刷新
物化视图是按照分区为单位进行刷新的。如果物化视图没有指定分区,那么每次都刷新物化视图的默认分区,即刷新物化视图的全部数据。
物化视图有三种触发刷新机制:
手动触发
用户通过 SQL 语句触发物化视图的刷新,目前有三种策略:
不关心具体刷新哪些分区,要求刷新完成后,物化视图的数据和基表保持同步。
REFRESH MATERIALIZED VIEW mvName AUTO;不管物化视图现存哪些数据,刷新物化视图的所有分区。
REFRESH MATERIALIZED VIEW mvName COMPLETE;不管物化视图现存哪些数据,只刷新指定的分区。
REFRESH MATERIALIZED VIEW mvName partitions(partitionName1,partitionName2);
partitionName 可以通过 SHOW PARTITIONS FROM mvName 获取。
定时触发
通过物化视图的创建语句指定间隔多久刷新一次数据
如果物化视图的创建语句如下,要求全量刷新 (
REFRESH COMPLETE),那么物化视图每 10 小时刷新一次,并且刷新物化视图的所有分区。CREATE MATERIALIZED VIEW mv1
REFRESH COMPLETE ON SCHEDULE EVERY 10 hour
partition by(`xxx`)
AS
select ...;如果物化视图的创建语句如下,要求自动计算需要刷新的分区 (
REFRESH AUTO),那么物化视图每 10 小时刷新一次(从 2.1.3 版本开始能自动计算 Hive 需要刷新的分区)。CREATE MATERIALIZED VIEW mv1
REFRESH AUTO ON SCHEDULE EVERY 10 hour
partition by(`xxx`)
AS
select ...;
自动触发
自 Apache Doris 2.1.4 版本起支持此功能。
基表数据发生变更后,自动触发相关物化视图刷新,刷新的分区范围与“定时触发”一致。
如果物化视图的创建语句如下,那么当 t1 的数据发生变化时,会自动触发物化视图的刷新。
CREATE MATERIALIZED VIEW mv1
REFRESH ON COMMIT
partition by(`xxx`)
AS
select ... from t1;
透明改写能力
Doris 的异步物化视图采用了基于 SPJG(SELECT-PROJECT-JOIN-GROUP-BY)模式的结构信息来进行透明改写的算法。Doris 能够分析查询 SQL 的结构信息,自动寻找满足要求的物化视图,并尝试进行透明改写,使用最优的物化视图来表达查询 SQL。
流程图
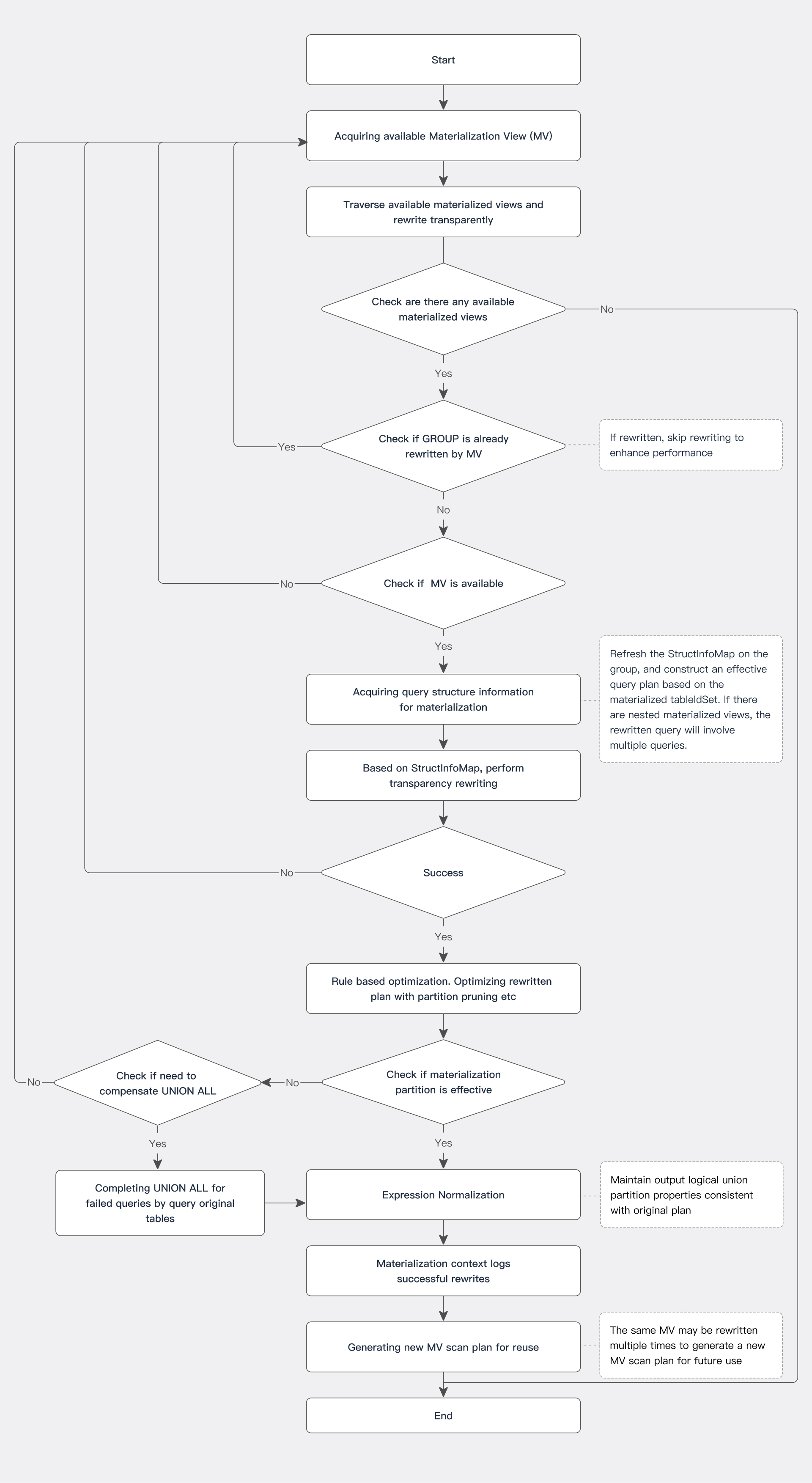
基于结构信息透明改写
如上述流程图所示,在获取物化对应的查询结构后,将基于结构信息进行透明改写。这时,需要做如下校验:
1. 校验物化视图是否包含查询所需的所有行
对于查询:
SELECT * FROM T1, T2, …, Tm WHERE Wq对于物化视图:
SELECT * FROM T1, T2, …, Tm WHERE Wv
查询的条件要强于或等于物化的条件。
其中 T1, T2 是表、Wq 代表查询的 WHERE 过滤条件、Wv 代表物化视图 WHERE 过滤条件。要满足视图包含了查询所需要的所有行,就要满足过滤条件 Wq 能够推导出 Wv,即 Wq -> Wv(比如 Wq > 20, Wv > 10,Wq 就能够推导出 Wv。)
对于表达式 W 还可以细化,过滤的表达式可以拆成三部分:PE ∧ PR ∧ PU。
PE 代表相等的表达式;
PR 代表范围过滤的表达式,使用“<”, “≤”, “=”, “≥”, “>”连接的操作符;
PU 代表除了前面表达式的其余补偿表达式。
因此,基于 Wq -> Wv 推导出 (PEq ∧ PRq ∧ PUq → PEv ∧ PRv ∧ PUv)。其中 q 代表查询,v 代表物化视图。
因为 A -> C,那么 AB -> C,上面的表达式可以进一步推导如下:
(PEq∧ PRq∧PUq⇒ PEv )∧
(PEq∧ PRq∧PUq⇒ PRv)∧
(PEq∧ PRq∧PUq⇒ PUv)
可以进一步简化成:
(PEq ⇒ PEv ) (Equijoin subsumption test 等值条件校验)
(PEq ∧ PRq ⇒ PRv) (Range subsumption test 范围条件校验)
(PEq ∧ PUq ⇒ PUv ) (Residual subsumption test 补偿条件校验)
等值条件校验:总体原则是物化视图的相等表达式是查询相等表达式的子集。等价表达式具有传递性,也应保持正确性。
视图的范围表达式应包含查询的表达式。例如,T=常量值,可以转换成 T>= 常量值 and T<= 常量值的形式。
采用 Expression Equals 的方式,校验物化视图中出现的补偿表达式是否是查询补偿表达式的子集。
接下来,我们将通过举例进一步解释检验步骤:
物化视图的定义:
Select l_orderkey, o_custkey, l_partkey,
l_shipdate, o_orderdate,
l_quantity*l_extendedprice as gross_revenue
From dbo.lineitem, dbo.orders, dbo.part
Where l_orderkey = o_orderkey
And l_partkey = p_partkey
And p_partkey >= 150
And o_custkey >= 50 and o_custkey <= 500
And p_name like ‘%abc%’
查询的定义:
Select l_orderkey, o_custkey, l_partkey,
l_quantity*l_extendedprice
From lineitem, orders, part
Where l_orderkey = o_orderkey
And l_partkey = p_partkey
And l_partkey >= 150 and l_partkey <= 160
And o_custkey = 123
And o_orderdate = l_shipdate
And p_name like ‘%abc%’
And l_quantity*l_extendedprice > 100
第一步:计算等价类
视图等价类:
{l_orderkey, o_orderkey},{l_partkey, p_partkey}, {o_orderdate}, {l_shipdate}查询等价类:
{l_orderkey, o_orderkey},{l_partkey, p_partkey}, {o_orderdate, l_shipdate}
第二步:校验等值等价类
- 若 视图等价表达式 = 查询等价表达式的子集,则通过校验。
第三步:计算范围表达式
视图范围表达式:
{l_partkey, p_partkey} ∈ (150, +∞), {o_custkey} ∈ (50, 500)查询范围表达式:
{l_partkey, p_partkey} ∈ (150, 160), {o_custkey} ∈ (123, 123)
第四步:校验范围表达式
视图范围表达式:(150, 160) 在 (150, +∞) 范围内
查询范围表达式:(123, 123) 在 (50, 500) 范围内
第五步:校验补偿表达式
视图补偿表达式:p_name like‘%abc%’
查询补偿表达式:p_name like‘%abc%’
因为 l_quantity*l_extendedprice > 100,视图的补偿表达式是查询的子集。在经过以上步骤校验,可以保证所有的行从视图中获取,需要在视图上添加补偿条件,补偿条件如下:
(o_orderdate = l_shipdate),
({p_partkey,l_partkey} <= 160),
(o_custkey = 123), and
(l_quantity*l_extendedprice > 100.00).
2. 补偿的条件是否可以从物化视图获取
需要对视图添加补偿条件,才能保证最终获取的数据和原始查询一致。需要进行校验,验证补偿条件中选择的列或表达式可以从视图上获取。
即需要校验列 o_orderdate,l_shipdate,p_partkey,{p_partkey, l_partkey},o_custkey 以及表达式 l_quantity*l_extendedprice 是否可从视图中获取。
3. 表达式和列是否可从物化视图获取
与校验补偿条件相似,如果输出表达式是常量,可以直接在视图上复制常量;如果是简单的列引用,校验它是否可以从视图中获取;对于表达式,如果表达式的列可以从物化视图中获取,就直接获取,否则校验不通过。
4. 输出数据重复度一致校验
对于查询和使用物化视图后获取的数据,对于重复的行,需要有相同的重复行数。如果查询和物化视图引用的表相同,就不会出现上述问题。只有当查询和物化视图引用的表不同时,才有可能出现重复的行且重复行数不同的情况,比如星型查询多一个连接关系时,如果连接键不是主外键的关系,就容易造成数据膨胀,导致数据重复因数不一致。
通常需要校验物化视图和查询在相同表情况下的 JOIN 类型,以及在不同表情况下是否满足 JOIN 消除。
5. 聚合校验
物化的维度是否比查询更细,是否包含查询的维度
查询使用的聚合函数是否可以从物化视图获取,或者是否可以通过物化视图的函数上卷获得。
