Overview
Create Async-Materialized View
There are two ways to partition materialized views: manual partition and auto partition based on the base table.
Manual Partition
When creating a materialized view without specifying partition information, the materialized view will default to creating a single partition where all data is stored.
Auto Partition Based on the Base Table
Materialized views can be created through joins with multiple base tables and can choose to follow the partitioning of one of the base tables (it is recommended to choose the fact table).
For example, the table creation statements for base tables t1 and t2 are as follows:
CREATE TABLE `t1` (
`user_id` LARGEINT NOT NULL,
`o_date` DATE NOT NULL,
`num` SMALLINT NOT NULL
) ENGINE=OLAP
COMMENT 'OLAP'
PARTITION BY RANGE(`o_date`)
(
PARTITION p20170101 VALUES [('2017-01-01'), ('2017-01-02')),
PARTITION p20170102 VALUES [('2017-01-02'), ('2017-01-03')),
PARTITION p20170201 VALUES [('2017-02-01'), ('2017-02-02'))
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 2
PROPERTIES ('replication_num' = '1');
CREATE TABLE `t2` (
`user_id` LARGEINT NOT NULL,
`age` SMALLINT NOT NULL
) ENGINE=OLAP
PARTITION BY LIST(`age`)
(
PARTITION `p1` VALUES IN ('1'),
PARTITION `p2` VALUES IN ('2')
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 2
PROPERTIES ('replication_num' = '1');
If the materialized view creation statement is as follows:
CREATE MATERIALIZED VIEW mv1
BUILD DEFERRED REFRESH AUTO ON MANUAL
partition by(`order_date`)
DISTRIBUTED BY RANDOM BUCKETS 2
PROPERTIES (
'replication_num' = '1'
)
AS
SELECT t1.o_date as order_date, t1.user_id as user_id, t1.num, t2.age FROM t1 join t2 on t1.user_id=t2.user_id;
Then the materialized view mv1 will have the same three partitions as t1:
[('2017-01-01'), ('2017-01-02'))[('2017-01-02'), ('2017-01-03'))[('2017-02-01'), ('2017-02-02'))
If the materialized view creation statement is as follows:
CREATE MATERIALIZED VIEW mv2
BUILD DEFERRED REFRESH AUTO ON MANUAL
partition by(`age`)
DISTRIBUTED BY RANDOM BUCKETS 2
PROPERTIES (
'replication_num' = '1'
)
AS
SELECT t1.o_date as order_date, t1.user_id as user_id, t1.num, t2.age FROM t1 join t2 on t1.user_id=t2.user_id;
Then the materialized view mv2 will have the same two partitions as t2:
('1')('2')
When creating materialized views that depend on base table partitions, different partition strategies need to be designed appropriately for different scenarios. Below are examples illustrating multi-column partitioning, partial partitioning, and partition roll-up.
1. Base Table with Multi-Column Partitioning
Supported since Doris 2.1.0
Currently, only Hive external tables support multi-column partitioning. Hive external tables often have multi-level partitioning, for example, one level by date and another by region. The materialized view can choose one of the partitioning columns from Hive as its partitioning column.
For example, the Hive table creation statement is as follows:
CREATE TABLE hive1 (
`k1` int)
PARTITIONED BY (
`year` int,
`region` string)
STORED AS ORC;
alter table hive1 add if not exists
partition(year=2020,region="bj")
partition(year=2020,region="sh")
partition(year=2021,region="bj")
partition(year=2021,region="sh")
partition(year=2022,region="bj")
partition(year=2022,region="sh")
When the materialized view creation statement is as follows, the materialized view mv_hive will have three partitions: ('2020'), ('2021'), ('2022')
CREATE MATERIALIZED VIEW mv_hive
BUILD DEFERRED REFRESH AUTO ON MANUAL
partition by(`year`)
DISTRIBUTED BY RANDOM BUCKETS 2
PROPERTIES ('replication_num' = '1')
AS
SELECT k1,year,region FROM hive1;
When the materialized view creation statement is as follows, the materialized view mv_hive2 will have two partitions: ('bj'), ('sh'):
CREATE MATERIALIZED VIEW mv_hive2
BUILD DEFERRED REFRESH AUTO ON MANUAL
partition by(`region`)
DISTRIBUTED BY RANDOM BUCKETS 2
PROPERTIES ('replication_num' = '1')
AS
SELECT k1,year,region FROM hive1;
2. Using Partial Base Table Partitioning
Supported since Doris 2.1.1
Some base tables have many partitions, but the materialized view only focuses on the "hot" data from a recent period. This feature can be used in such scenarios.
The base table creation statement is as follows:
CREATE TABLE t1 (
`k1` INT,
`k2` DATE NOT NULL
) ENGINE=OLAP
DUPLICATE KEY(`k1`)
COMMENT 'OLAP'
PARTITION BY range(`k2`)
(
PARTITION p26 VALUES [("2024-03-26"),("2024-03-27")),
PARTITION p27 VALUES [("2024-03-27"),("2024-03-28")),
PARTITION p28 VALUES [("2024-03-28"),("2024-03-29"))
)
DISTRIBUTED BY HASH(`k1`) BUCKETS 2
PROPERTIES (
'replication_num' = '1'
);
The materialized view creation statement, representing that the materialized view only focuses on the data from the last day, is as follows. If the current time is 2024-03-28 xx:xx:xx, the materialized view will only have one partition [("2024-03-28"),("2024-03-29")]:
CREATE MATERIALIZED VIEW mv1
BUILD DEFERRED REFRESH AUTO ON MANUAL
partition by(`k2`)
DISTRIBUTED BY RANDOM BUCKETS 2
PROPERTIES (
'replication_num' = '1',
'partition_sync_limit'='1',
'partition_sync_time_unit'='DAY'
)
AS
SELECT * FROM t1;
If the time passes by another day, and the current time becomes 2024-03-29 xx:xx:xx, t1 will add a new partition [("2024-03-29"),("2024-03-30")]. If the materialized view is refreshed at this point, after the refresh, the materialized view will only have one partition [("2024-03-29"),("2024-03-30")].
Additionally, if the partition field is of string type, you can set the materialized view property partition_date_format, such as %Y-%m-%d.
3. Partition Roll-Up
Supported since Doris 2.1.5
When the base table data is aggregated, the data volume in each partition may significantly decrease. In such cases, a partition roll-up strategy can be adopted to reduce the number of partitions in the materialized view.
List Partitioning
Note that partitions in Hive correspond to the list partitions in Doris.
Assuming the base table creation statement is as follows:
CREATE TABLE `t1` (
`k1` INT NOT NULL,
`k2` DATE NOT NULL
) ENGINE=OLAP
DUPLICATE KEY(`k1`)
COMMENT 'OLAP'
PARTITION BY list(`k2`)
(
PARTITION p_20200101 VALUES IN ("2020-01-01"),
PARTITION p_20200102 VALUES IN ("2020-01-02"),
PARTITION p_20200201 VALUES IN ("2020-02-01")
)
DISTRIBUTED BY HASH(`k1`) BUCKETS 2
PROPERTIES ('replication_num' = '1');If the materialized view creation statement is as follows, the materialized view will have two partitions:
("2020-01-01","2020-01-02")and("2020-02-01")CREATE MATERIALIZED VIEW mv1
BUILD DEFERRED REFRESH AUTO ON MANUAL
partition by (date_trunc(`k2`,'month'))
DISTRIBUTED BY RANDOM BUCKETS 2
PROPERTIES (
'replication_num' = '1'
)
AS
SELECT * FROM t1;If the materialized view creation statement is as follows, the materialized view will have only one partition:
("2020-01-01","2020-01-02","2020-02-01")CREATE MATERIALIZED VIEW mv1
BUILD DEFERRED REFRESH AUTO ON MANUAL
partition by (date_trunc(`k2`,'year'))
DISTRIBUTED BY RANDOM BUCKETS 2
PROPERTIES (
'replication_num' = '1'
)
AS
SELECT * FROM t1;Range Partitioning
Assuming the base table creation statement is as follows:
CREATE TABLE `t1` (
`k1` LARGEINT NOT NULL,
`k2` DATE NOT NULL
) ENGINE=OLAP
DUPLICATE KEY(`k1`)
COMMENT 'OLAP'
PARTITION BY range(`k2`)
(
PARTITION p_20200101 VALUES [("2020-01-01"),("2020-01-02")),
PARTITION p_20200102 VALUES [("2020-01-02"),("2020-01-03")),
PARTITION p_20200201 VALUES [("2020-02-01"),("2020-02-02"))
)
DISTRIBUTED BY HASH(`k1`) BUCKETS 2
PROPERTIES ('replication_num' = '1');If the materialized view creation statement is as follows, the materialized view will have two partitions:
[("2020-01-01","2020-02-01")]and[("2020-02-01","2020-03-01")]CREATE MATERIALIZED VIEW mv1
BUILD DEFERRED REFRESH AUTO ON MANUAL
partition by (date_trunc(`k2`,'month'))
DISTRIBUTED BY RANDOM BUCKETS 2
PROPERTIES (
'replication_num' = '1'
)
AS
SELECT * FROM t1;If the materialized view creation statement is as follows, the materialized view will have only one partition:
[("2020-01-01","2021-01-01")]CREATE MATERIALIZED VIEW mv1
BUILD DEFERRED REFRESH AUTO ON MANUAL
partition by (date_trunc(`k2`,'year'))
DISTRIBUTED BY RANDOM BUCKETS 2
PROPERTIES (
'replication_num' = '1'
)
AS
SELECT * FROM t1;Additionally, if the partition field is of string type, you can specify the date format by setting the
partition_date_formatproperty of the materialized view, such as'%Y-%m-%d'.
Refresh Async-Materialized View
Materialized views are refreshed on a per-partition basis. If no specific partition is designated for the materialized view, its default partition will be refreshed during each refresh operation, effectively refreshing all data within the materialized view.
There are three trigger mechanisms for refreshing materialized views:
Manual Refresh
Users can trigger the refresh of materialized views through SQL statements. Currently, there are three strategies:
Refresh without concern for specific partitions, requiring that the data in the materialized view synchronizes with the base table upon completion.
REFRESH MATERIALIZED VIEW mvName AUTO;Refresh all partitions of the materialized view, regardless of its current data.
REFRESH MATERIALIZED VIEW mvName COMPLETE;Refresh only specified partitions of the materialized view, regardless of its current data.
REFRESH MATERIALIZED VIEW mvName partitions(partitionName1,partitionName2);
::: tip
partitionName can be retrieved through SHOW PARTITIONS FROM mvName.
:::
Scheduled Refresh
The interval for refreshing data can be specified through the materialized view creation statement.
If the materialized view creation statement is as follows, requiring a full refresh (
REFRESH COMPLETE), the materialized view will refresh every 10 hours, refreshing all partitions.CREATE MATERIALIZED VIEW mv1
REFRESH COMPLETE ON SCHEDULE EVERY 10 HOUR
PARTITION BY(`xxx`)
AS
SELECT ...;If the materialized view creation statement is as follows, requiring automatic calculation of partitions to refresh (
REFRESH AUTO), the materialized view will refresh every 10 hours (since version 2.1.3, it can automatically calculate partitions to refresh for Hive).CREATE MATERIALIZED VIEW mv1
REFRESH AUTO ON SCHEDULE EVERY 10 HOUR
PARTITION BY(`xxx`)
AS
SELECT ...;
Auto Refresh
Supported since Apache Doris version 2.1.4.
After data in the base table changes, the related materialized views are automatically triggered for refresh, with the same partition scope as scheduled triggers.
If the materialized view creation statement is as follows, when data in t1 changes, it will automatically trigger the refresh of the materialized view.
CREATE MATERIALIZED VIEW mv1
REFRESH ON COMMIT
PARTITION BY(`xxx`)
AS
SELECT ... FROM t1;
Transparent Rewrite
Doris's async-materialized views employ an algorithm based on SPJG (SELECT-PROJECT-JOIN-GROUP-BY) pattern structural information for transparent rewrite. Doris can analyze the structural information of query SQL, automatically search for materialized views that meet the requirements, and attempt transparent rewrite, using the optimal materialized view to express the query SQL.
Flow Chart
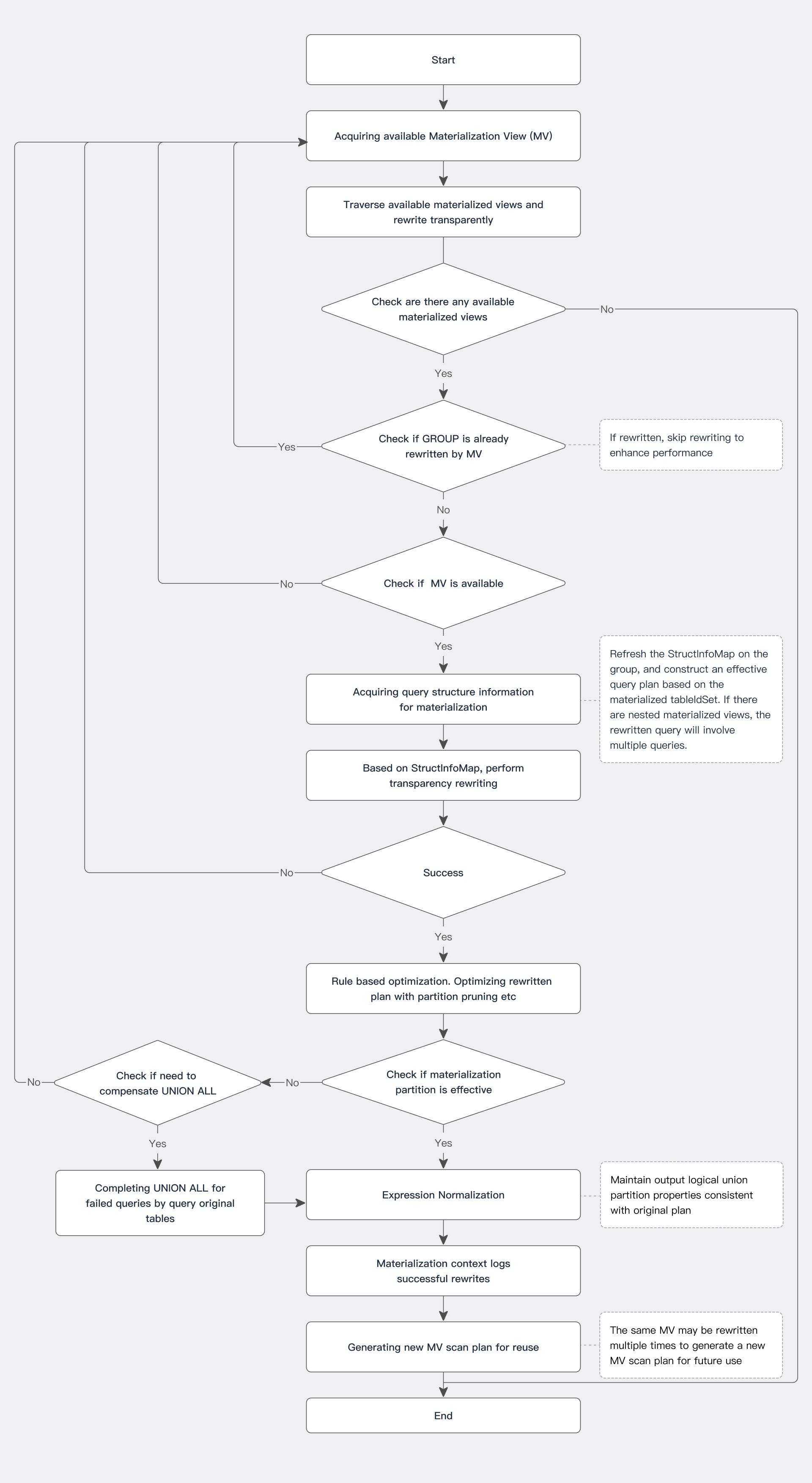
Transparent Rewrite Based on Structural Information
As shown in the flowchart, after obtaining the query structure corresponding to the materialization, transparent rewrite will be based on structural information. At this point, the following verifications are required:
1. Verify if the materialized view contains all rows required for the query
For the query:
SELECT * FROM T1, T2, …, Tm WHERE WqFor the materialized view:
SELECT * FROM T1, T2, …, Tm WHERE Wv
The query conditions must be stronger than or equal to the materialized conditions.
Where T1, T2 are tables, Wq represents the WHERE filter condition of the query, and Wv represents the WHERE filter condition of the materialized view. To ensure that the view contains all rows required by the query, the filter condition Wq must be able to derive Wv, i.e., Wq -> Wv (for example, if Wq > 20 and Wv > 10, Wq can derive Wv).
The expression W can be further refined, with filter expressions divisible into three parts: PE ∧ PR ∧ PU.
PE represents equal expressions;
PR represents range filter expressions, using operators such as "<", "≤", "=", "≥", ">";
PU represents residual expressions excluding the aforementioned.
Therefore, based on Wq -> Wv, we can derive (PEq ∧ PRq ∧ PUq → PEv ∧ PRv ∧ PUv). Where q represents the query, and v represents the materialized view.
Since A -> C, then AB -> C. The above expression can be further derived as follows:
(PEq∧ PRq∧PUq⇒ PEv )∧
(PEq∧ PRq∧PUq⇒ PRv)∧
(PEq∧ PRq∧PUq⇒ PUv)
Which can be further simplified to:
(PEq ⇒ PEv ) (Equijoin subsumption test - Equivalence condition verification)
(PEq ∧ PRq ⇒ PRv) (Range subsumption test - Range condition verification)
(PEq ∧ PUq ⇒ PUv ) (Residual subsumption test - Residual condition verification)
Equivalence condition verification: The general principle is that the equal expressions of the materialized view are a subset of the query's equal expressions. Equivalent expressions are transitive and should maintain correctness.
The range expressions of the view should encompass those of the query. For example, T=constant can be converted to T>=constant AND T<=constant.
Using Expression Equals, verify if the residual expressions appearing in the materialized view are a subset of those in the query.
Next, we will further explain the verification steps through examples:
Materialized view definition:
SELECT l_orderkey, o_custkey, l_partkey,
l_shipdate, o_orderdate,
l_quantity*l_extendedprice AS gross_revenue
FROM dbo.lineitem, dbo.orders, dbo.part
WHERE l_orderkey = o_orderkey
AND l_partkey = p_partkey
AND p_partkey >= 150
AND o_custkey >= 50 AND o_custkey <= 500
AND p_name LIKE '%abc%'
Query definition:
SELECT l_orderkey, o_custkey, l_partkey,
l_quantity*l_extendedprice
FROM lineitem, orders, part
WHERE l_orderkey = o_orderkey
AND l_partkey = p_partkey
AND l_partkey >= 150 AND l_partkey <= 160
AND o_custkey = 123
AND o_orderdate = l_shipdate
AND p_name LIKE '%abc%'
AND l_quantity*l_extendedprice > 100
Step 1: Calculate equivalence classes
View equivalence classes:
{l_orderkey, o_orderkey},{l_partkey, p_partkey}, {o_orderdate}, {l_shipdate}Query equivalence classes:
{l_orderkey, o_orderkey},{l_partkey, p_partkey}, {o_orderdate, l_shipdate}
Step 2: verify equivalence equivalence classes
- If the view equivalence expression is a subset of the query equivalence expression, the verification passes.
Step 3: Calculate range expressions
View range expressions:
{l_partkey, p_partkey} ∈ (150, +∞), {o_custkey} ∈ (50, 500)Query range expressions:
{l_partkey, p_partkey} ∈ (150, 160), {o_custkey} ∈ (123, 123)
Step 4: Verify range expressions
View range expressions: (150, 160) falls within (150, +∞)
Query range expressions: (123, 123) falls within (50, 500)
Step 5: Verify residual expressions
View residual expression: p_name LIKE '%abc%'
Query residual expression: p_name LIKE '%abc%'
Since l_quantity*l_extendedprice > 100, the view's residual expression is a subset of the query's. After verifying the above steps, we can ensure all rows are retrieved from the view, and compensation conditions need to be added to the view:
(o_orderdate = l_shipdate),
({p_partkey,l_partkey} <= 160),
(o_custkey = 123), and
(l_quantity*l_extendedprice > 100.00).
2. Verify if the compensation conditions can be obtained from the materialized view
To ensure the final data obtained is consistent with the original query, compensation conditions need to be added to the view. Verification is required to confirm if the columns or expressions selected in the compensation conditions can be obtained from the view.
This involves verifying if columns o_orderdate, l_shipdate, p_partkey, {p_partkey, l_partkey}, o_custkey, and expression l_quantity*l_extendedprice can be obtained from the view.
3. Verify if expressions and columns can be obtained from the materialized view
Similar to verifying compensation conditions, if the output expression is a constant, it can be directly copied from the view. If it's a simple column reference, verify if it can be obtained from the view. For expressions, if the columns in the expression can be obtained from the materialized view, obtain them directly; otherwise, the verification fails.
4. Verify consistency in output data duplication
For data obtained through queries and materialized views, the number of duplicate rows must be the same. If the tables referenced by the query and materialized view are the same, this issue will not arise. Duplicates and their counts may differ only when the tables referenced by the query and materialized view are different, especially in star schema queries with an additional join that is not a primary-foreign key relationship, potentially leading to data expansion and inconsistent duplication factors.
Usually, it's necessary to verify the JOIN types of the materialized view and query for the same tables and whether JOIN elimination is satisfied for different tables.
5. Aggregation verification
Verify if the materialized dimensions are finer than those of the query and if they encompass the query's dimensions.
Verify if the aggregation functions used in the query can be obtained from the materialized view or derived through roll-up of the materialized view's functions.
